 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforced Diffusion: Learning to Push the Limits of Anisotropic Diffusion for Image Denoising
Dec 30, 2025Image denoising is an important problem in low-level vision and serves as a critical module for many image recovery tasks. Anisotropic diffusion is a wide family of image denoising approaches with promising performance. However, traditional anisotropic diffusion approaches use explicit diffusion operators which are not well adapted to complex image structures. As a result, their performance is limited compared to recent learning-based approaches. In this work, we describe a trainable anisotropic diffusion framework based on reinforcement learning. By modeling the denoising process as a series of naive diffusion actions with order learned by deep Q-learning, we propose an effective diffusion-based image denoiser. The diffusion actions selected by deep Q-learning at different iterations indeed composite a stochastic anisotropic diffusion process with strong adaptivity to different image structures, which enjoys improvement over the traditional ones. The proposed denoiser is applied to removing three types of often-seen noise. The experiments show that it outperforms existing diffusion-based methods and competes with the representative deep CNN-based methods.
Highly Efficient No-reference 4K Video Quality Assessment with Full-Pixel Covering Sampling and Training Strategy
Jul 30, 2024



Deep Video Quality Assessment (VQA) methods have shown impressive high-performance capabilities. Notably, no-reference (NR) VQA methods play a vital role in situations where obtaining reference videos is restricted or not feasible. Nevertheless, as more streaming videos are being created in ultra-high definition (e.g., 4K) to enrich viewers' experiences, the current deep VQA methods face unacceptable computational costs. Furthermore, the resizing, cropping, and local sampling techniques employed in these methods can compromise the details and content of original 4K videos, thereby negatively impacting quality assessment. In this paper, we propose a highly efficient and novel NR 4K VQA technology. Specifically, first, a novel data sampling and training strategy is proposed to tackle the problem of excessive resolution. This strategy allows the VQA Swin Transformer-based model to effectively train and make inferences using the full data of 4K videos on standard consumer-grade GPUs without compromising content or details. Second, a weighting and scoring scheme is developed to mimic the human subjective perception mode, which is achieved by considering the distinct impact of each sub-region within a 4K frame on the overall perception. Third, we incorporate the frequency domain information of video frames to better capture the details that affect video quality, consequently further improving the model's generalizability. To our knowledge, this is the first technology for the NR 4K VQA task. Thorough empirical studies demonstrate it not only significantly outperforms existing methods on a specialized 4K VQA dataset but also achieves state-of-the-art performance across multiple open-source NR video quality datasets.
Dataset-free Deep learning Method for Low-Dose CT Image Reconstruction
May 01, 2022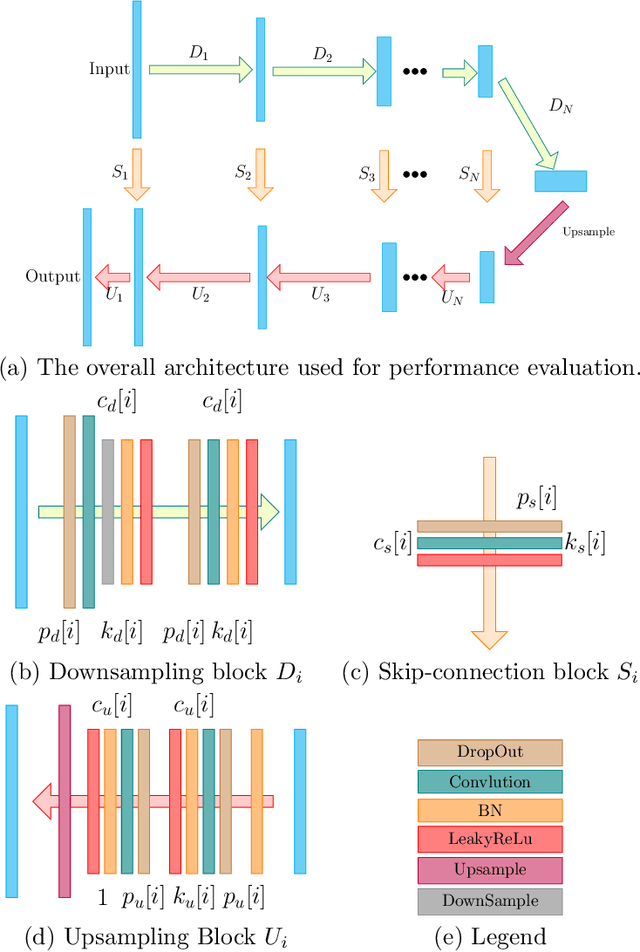

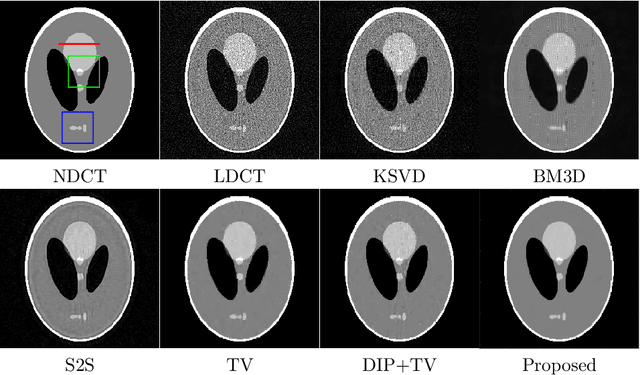
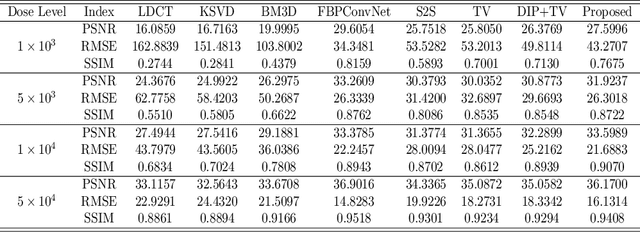
Low-dose CT (LDCT) imaging attracted a considerable interest for the reduction of the object's exposure to X-ray radiation. In recent years, supervised deep learning has been extensively studied for LDCT image reconstruction, which trains a network over a dataset containing many pairs of normal-dose and low-dose images. However, the challenge on collecting many such pairs in the clinical setup limits the application of such supervised-learning-based methods for LDCT image reconstruction in practice. Aiming at addressing the challenges raised by the collection of training dataset, this paper proposed a unsupervised deep learning method for LDCT image reconstruction, which does not require any external training data. The proposed method is built on a re-parametrization technique for Bayesian inference via deep network with random weights, combined with additional total variational (TV) regularization. The experiments show that the proposed method noticeably outperforms existing dataset-free image reconstruction methods on the test data.
Gaussian Kernel Mixture Network for Single Image Defocus Deblurring
Oct 31, 2021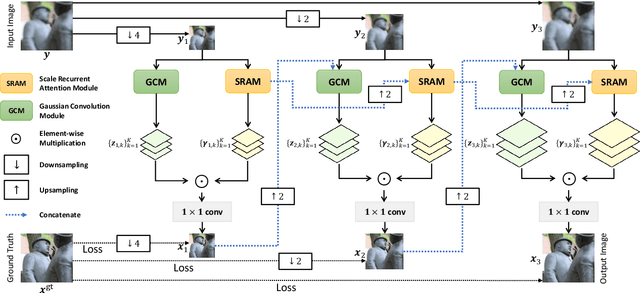
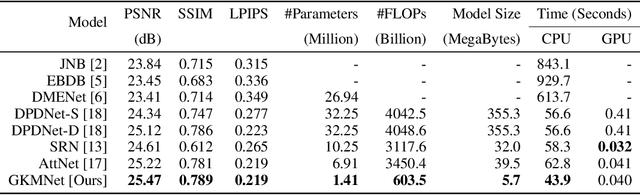
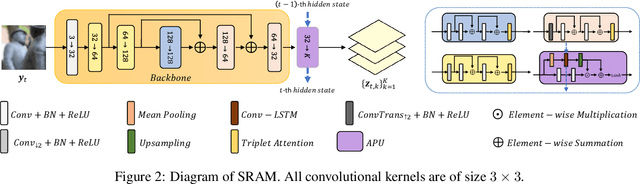
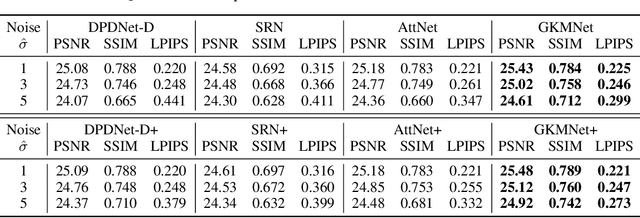
Defocus blur is one kind of blur effects often seen in images, which is challenging to remove due to its spatially variant amount. This paper presents an end-to-end deep learning approach for removing defocus blur from a single image, so as to have an all-in-focus image for consequent vision tasks. First, a pixel-wise Gaussian kernel mixture (GKM) model is proposed for representing spatially variant defocus blur kernels in an efficient linear parametric form, with higher accuracy than existing models. Then, a deep neural network called GKMNet is developed by unrolling a fixed-point iteration of the GKM-based deblurring. The GKMNet is built on a lightweight scale-recurrent architecture, with a scale-recurrent attention module for estimating the mixing coefficients in GKM for defocus deblurring. Extensive experiments show that the GKMNet not only noticeably outperforms existing defocus deblurring methods, but also has its advantages in terms of model complexity and computational efficiency.
Recurrent Exposure Generation for Low-Light Face Detection
Jul 21, 2020
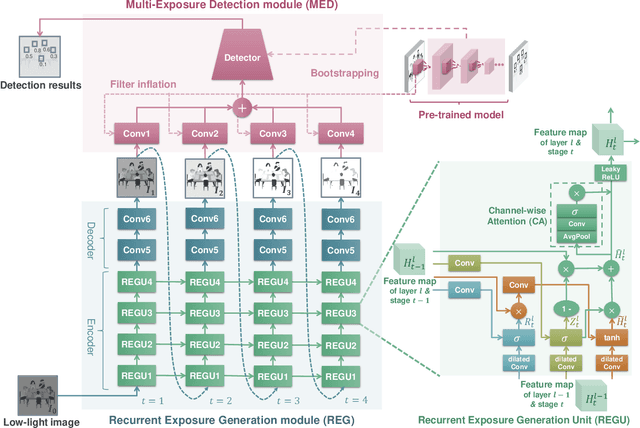


Face detection from low-light images is challenging due to limited photos and inevitable noise, which, to make the task even harder, are often spatially unevenly distributed. A natural solution is to borrow the idea from multi-exposure, which captures multiple shots to obtain well-exposed images under challenging conditions. High-quality implementation/approximation of multi-exposure from a single image is however nontrivial. Fortunately, as shown in this paper, neither is such high-quality necessary since our task is face detection rather than image enhancement. Specifically, we propose a novel Recurrent Exposure Generation (REG) module and couple it seamlessly with a Multi-Exposure Detection (MED) module, and thus significantly improve face detection performance by effectively inhibiting non-uniform illumination and noise issues. REG produces progressively and efficiently intermediate images corresponding to various exposure settings, and such pseudo-exposures are then fused by MED to detect faces across different lighting conditions. The proposed method, named REGDet, is the first `detection-with-enhancement' framework for low-light face detection. It not only encourages rich interaction and feature fusion across different illumination levels, but also enables effective end-to-end learning of the REG component to be better tailored for face detection. Moreover, as clearly shown in our experiments, REG can be flexibly coupled with different face detectors without extra low/normal-light image pairs for training. We tested REGDet on the DARK FACE low-light face benchmark with thorough ablation study, where REGDet outperforms previous state-of-the-arts by a significant margin, with only negligible extra parameters.
Deep Bilateral Retinex for Low-Light Image Enhancement
Jul 04, 2020

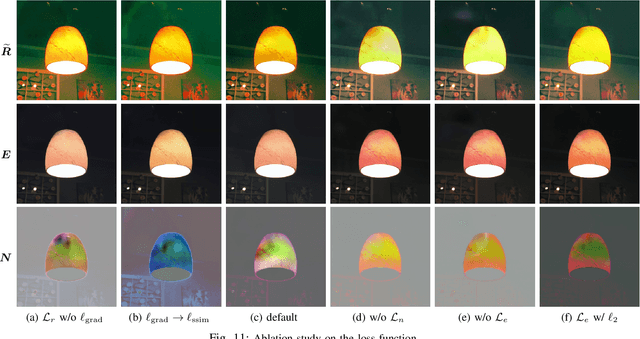

Low-light images, i.e. the images captured in low-light conditions, suffer from very poor visibility caused by low contrast, color distortion and significant measurement noise. Low-light image enhancement is about improving the visibility of low-light images. As the measurement noise in low-light images is usually significant yet complex with spatially-varying characteristic, how to handle the noise effectively is an important yet challenging problem in low-light image enhancement. Based on the Retinex decomposition of natural images, this paper proposes a deep learning method for low-light image enhancement with a particular focus on handling the measurement noise. The basic idea is to train a neural network to generate a set of pixel-wise operators for simultaneously predicting the noise and the illumination layer, where the operators are defined in the bilateral space. Such an integrated approach allows us to have an accurate prediction of the reflectance layer in the presence of significant spatially-varying measurement noise. Extensive experiments on several benchmark datasets have shown that the proposed method is very competitive to the state-of-the-art methods, and has significant advantage over others when processing images captured in extremely low lighting conditions.
Image Cartoon-Texture Decomposition Using Isotropic Patch Recurrence
Nov 10, 2018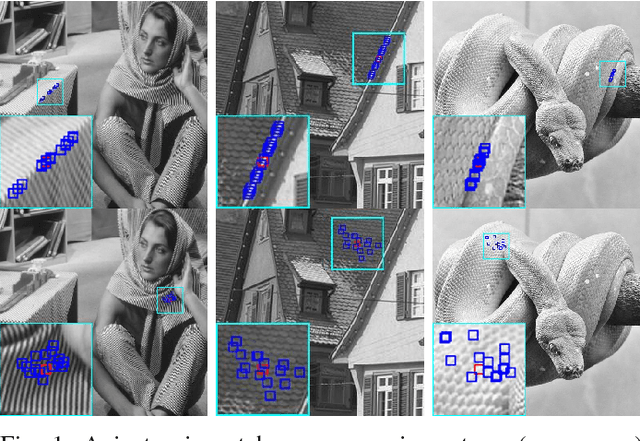
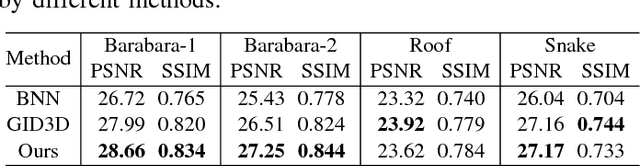
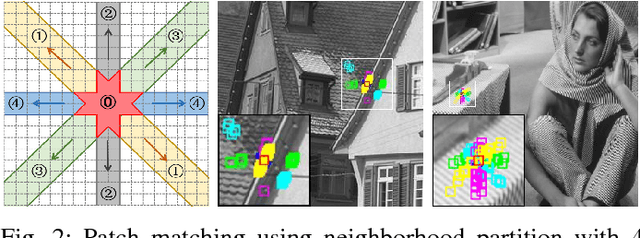

Aiming at separating the cartoon and texture layers from an image, cartoon-texture decomposition approaches resort to image priors to model cartoon and texture respectively. In recent years, patch recurrence has emerged as a powerful prior for image recovery. However, the existing strategies of using patch recurrence are ineffective to cartoon-texture decomposition, as both cartoon contours and texture patterns exhibit strong patch recurrence in images. To address this issue, we introduce the isotropy prior of patch recurrence, that the spatial configuration of similar patches in texture exhibits the isotropic structure which is different from that in cartoon, to model the texture component. Based on the isotropic patch recurrence, we construct a nonlocal sparsification system which can effectively distinguish well-patterned features from contour edges. Incorporating the constructed nonlocal system into morphology component analysis, we develop an effective method to both noiseless and noisy cartoon-texture decomposition. The experimental results have demonstrated the superior performance of the proposed method to the existing ones, as well as the effectiveness of the isotropic patch recurrence prior.