 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHighly Efficient No-reference 4K Video Quality Assessment with Full-Pixel Covering Sampling and Training Strategy
Jul 30, 2024



Deep Video Quality Assessment (VQA) methods have shown impressive high-performance capabilities. Notably, no-reference (NR) VQA methods play a vital role in situations where obtaining reference videos is restricted or not feasible. Nevertheless, as more streaming videos are being created in ultra-high definition (e.g., 4K) to enrich viewers' experiences, the current deep VQA methods face unacceptable computational costs. Furthermore, the resizing, cropping, and local sampling techniques employed in these methods can compromise the details and content of original 4K videos, thereby negatively impacting quality assessment. In this paper, we propose a highly efficient and novel NR 4K VQA technology. Specifically, first, a novel data sampling and training strategy is proposed to tackle the problem of excessive resolution. This strategy allows the VQA Swin Transformer-based model to effectively train and make inferences using the full data of 4K videos on standard consumer-grade GPUs without compromising content or details. Second, a weighting and scoring scheme is developed to mimic the human subjective perception mode, which is achieved by considering the distinct impact of each sub-region within a 4K frame on the overall perception. Third, we incorporate the frequency domain information of video frames to better capture the details that affect video quality, consequently further improving the model's generalizability. To our knowledge, this is the first technology for the NR 4K VQA task. Thorough empirical studies demonstrate it not only significantly outperforms existing methods on a specialized 4K VQA dataset but also achieves state-of-the-art performance across multiple open-source NR video quality datasets.
Statistical Learning for OCR Text Correction
Nov 21, 2016

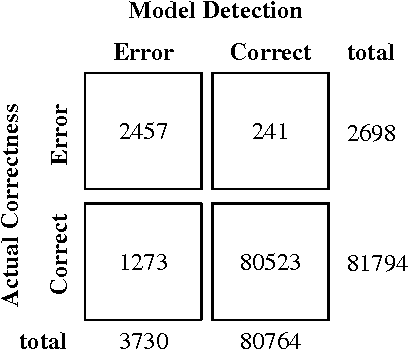

The accuracy of Optical Character Recognition (OCR) is crucial to the success of subsequent applications used in text analyzing pipeline. Recent models of OCR post-processing significantly improve the quality of OCR-generated text, but are still prone to suggest correction candidates from limited observations while insufficiently accounting for the characteristics of OCR errors. In this paper, we show how to enlarge candidate suggestion space by using external corpus and integrating OCR-specific features in a regression approach to correct OCR-generated errors. The evaluation results show that our model can correct 61.5% of the OCR-errors (considering the top 1 suggestion) and 71.5% of the OCR-errors (considering the top 3 suggestions), for cases where the theoretical correction upper-bound is 78%.