 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen do Convolutional Neural Networks Stop Learning?
Mar 04, 2024



Convolutional Neural Networks (CNNs) have demonstrated outstanding performance in computer vision tasks such as image classification, detection, segmentation, and medical image analysis. In general, an arbitrary number of epochs is used to train such neural networks. In a single epoch, the entire training data -- divided by batch size -- are fed to the network. In practice, validation error with training loss is used to estimate the neural network's generalization, which indicates the optimal learning capacity of the network. Current practice is to stop training when the training loss decreases and the gap between training and validation error increases (i.e., the generalization gap) to avoid overfitting. However, this is a trial-and-error-based approach which raises a critical question: Is it possible to estimate when neural networks stop learning based on training data? This research work introduces a hypothesis that analyzes the data variation across all the layers of a CNN variant to anticipate its near-optimal learning capacity. In the training phase, we use our hypothesis to anticipate the near-optimal learning capacity of a CNN variant without using any validation data. Our hypothesis can be deployed as a plug-and-play to any existing CNN variant without introducing additional trainable parameters to the network. We test our hypothesis on six different CNN variants and three different general image datasets (CIFAR10, CIFAR100, and SVHN). The result based on these CNN variants and datasets shows that our hypothesis saves 58.49\% of computational time (on average) in training. We further conduct our hypothesis on ten medical image datasets and compared with the MedMNIST-V2 benchmark. Based on our experimental result, we save $\approx$ 44.1\% of computational time without losing accuracy against the MedMNIST-V2 benchmark.
Will Your Forthcoming Book be Successful? Predicting Book Success with CNN and Readability Scores
Jul 21, 2020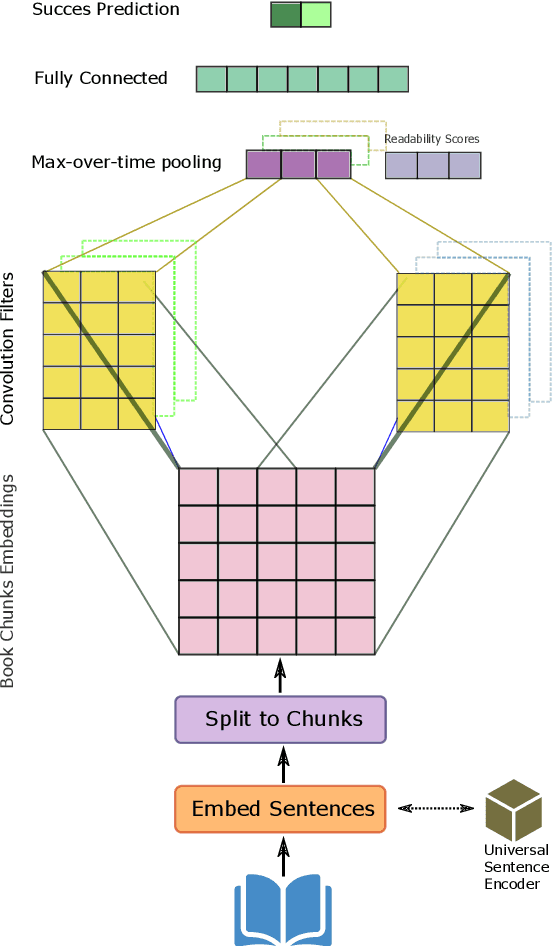
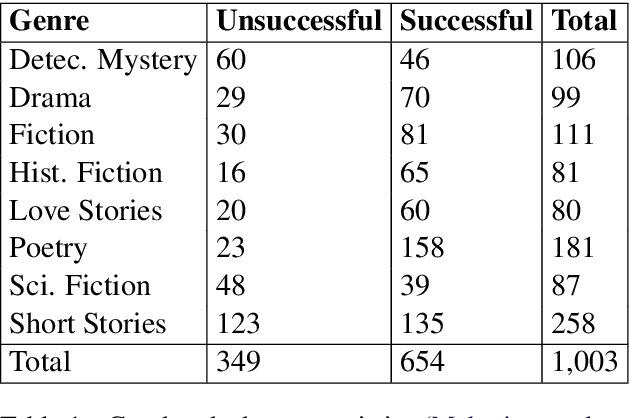

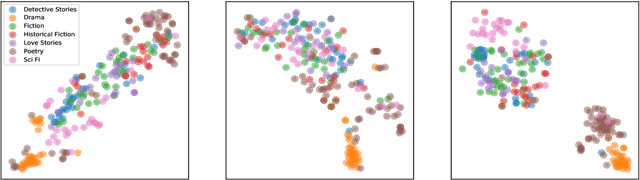
Predicting the potential success of a book in advance is vital in many applications. This could help both publishers and readers in their decision making process whether or not a book is worth publishing and reading, respectively. This prediction could also help authors decide whether a book draft is good enough to send to a publisher. We propose a model that leverages Convolutional Neural Networks along with readability indices. Unlike previous methods, our method includes no count-based, lexical, or syntactic hand-crafted features. Instead, we make use of a pre-trained sentence encoder to encode the book sentences. We highlight the connection between this task and book genre identification by showing that embeddings that are good at capturing the separability of book genres are better for the book success prediction task. We also show that only the first 1K sentences are good enough to predict the successability of books. Our proposed model outperforms strong baselines on this task by as large as 6.4% F1-score.
Statistical Learning for OCR Text Correction
Nov 21, 2016

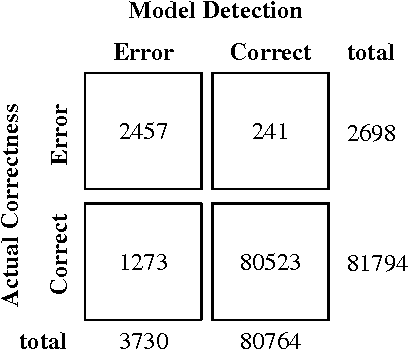

The accuracy of Optical Character Recognition (OCR) is crucial to the success of subsequent applications used in text analyzing pipeline. Recent models of OCR post-processing significantly improve the quality of OCR-generated text, but are still prone to suggest correction candidates from limited observations while insufficiently accounting for the characteristics of OCR errors. In this paper, we show how to enlarge candidate suggestion space by using external corpus and integrating OCR-specific features in a regression approach to correct OCR-generated errors. The evaluation results show that our model can correct 61.5% of the OCR-errors (considering the top 1 suggestion) and 71.5% of the OCR-errors (considering the top 3 suggestions), for cases where the theoretical correction upper-bound is 78%.