 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Molecular Embeddings in QSAR Modeling: Does it Make a Difference?
Mar 20, 2021
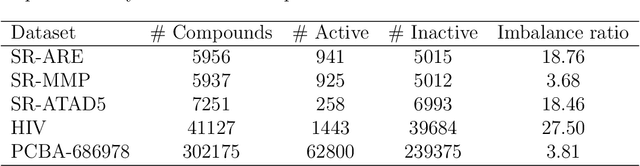
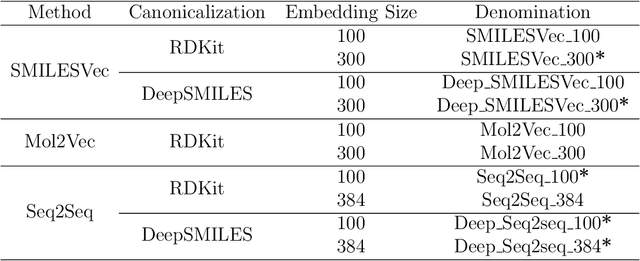
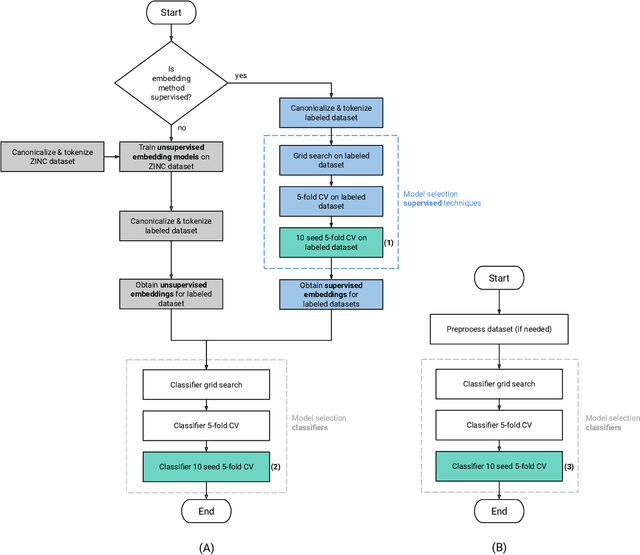
Several novel algorithms for learning molecular representations have been proposed recently with the consolidation of deep learning in computer-aided drug design. Learned molecular embeddings allow attaining rich representations of the molecular structure and physical-chemical properties while overcoming several limitations of traditional molecular representations. Despite their theoretical benefits, it is not clear how molecular embeddings compare with each other and with traditional representations, which in turn hinders the process of choosing a suitable embedding algorithm for QSAR modeling. A reason for this lack of consensus is that a fair and thorough comparison of different approaches is not straightforward. To close this gap, we reproduced three unsupervised and two supervised molecular embedding techniques recently proposed in the literature. Through a thorough experimental setup, we compared the molecular representations of these five methods concerning their performance in QSAR scenarios using five different datasets with varying class imbalance levels. We also compared these representations to traditional molecular representations, namely molecular descriptors and fingerprints. Our results show that molecular embeddings did not significantly surpass baseline results obtained using traditional molecular representations. While supervised techniques yielded competitive results compared to those obtained by traditional molecular representations, unsupervised techniques did not match the baseline results. Our results motivate a discussion about the usefulness of molecular embeddings in QSAR modeling and their potential in other drug design areas, such as similarity analysis and de novo drug design.
Statistical Learning for OCR Text Correction
Nov 21, 2016

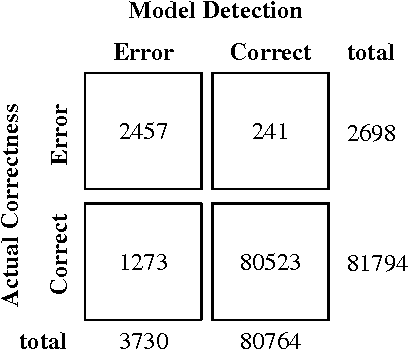

The accuracy of Optical Character Recognition (OCR) is crucial to the success of subsequent applications used in text analyzing pipeline. Recent models of OCR post-processing significantly improve the quality of OCR-generated text, but are still prone to suggest correction candidates from limited observations while insufficiently accounting for the characteristics of OCR errors. In this paper, we show how to enlarge candidate suggestion space by using external corpus and integrating OCR-specific features in a regression approach to correct OCR-generated errors. The evaluation results show that our model can correct 61.5% of the OCR-errors (considering the top 1 suggestion) and 71.5% of the OCR-errors (considering the top 3 suggestions), for cases where the theoretical correction upper-bound is 78%.