 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMambaSOD: Dual Mamba-Driven Cross-Modal Fusion Network for RGB-D Salient Object Detection
Oct 19, 2024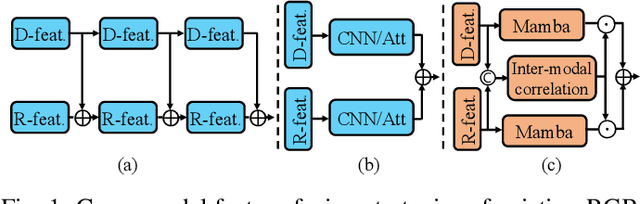
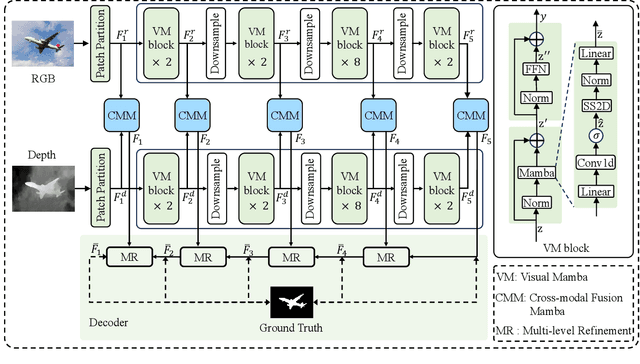
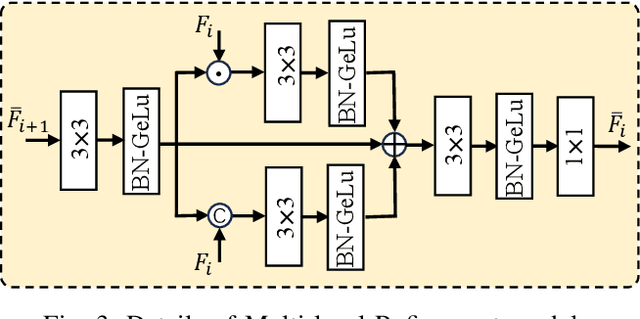
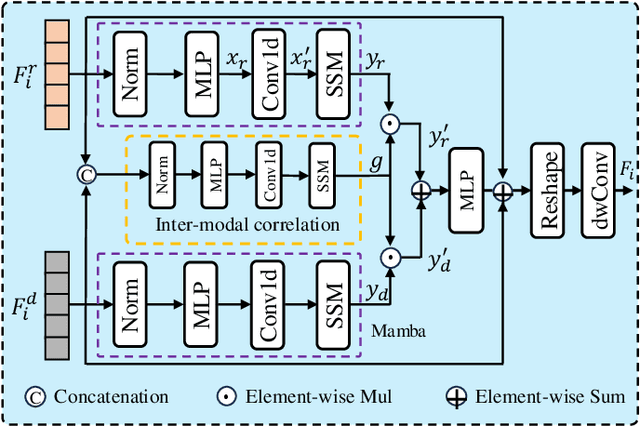
The purpose of RGB-D Salient Object Detection (SOD) is to pinpoint the most visually conspicuous areas within images accurately. While conventional deep models heavily rely on CNN extractors and overlook the long-range contextual dependencies, subsequent transformer-based models have addressed the issue to some extent but introduce high computational complexity. Moreover, incorporating spatial information from depth maps has been proven effective for this task. A primary challenge of this issue is how to fuse the complementary information from RGB and depth effectively. In this paper, we propose a dual Mamba-driven cross-modal fusion network for RGB-D SOD, named MambaSOD. Specifically, we first employ a dual Mamba-driven feature extractor for both RGB and depth to model the long-range dependencies in multiple modality inputs with linear complexity. Then, we design a cross-modal fusion Mamba for the captured multi-modal features to fully utilize the complementary information between the RGB and depth features. To the best of our knowledge, this work is the first attempt to explore the potential of the Mamba in the RGB-D SOD task, offering a novel perspective. Numerous experiments conducted on six prevailing datasets demonstrate our method's superiority over sixteen state-of-the-art RGB-D SOD models. The source code will be released at https://github.com/YueZhan721/MambaSOD.
AIM 2024 Challenge on Compressed Video Quality Assessment: Methods and Results
Aug 21, 2024
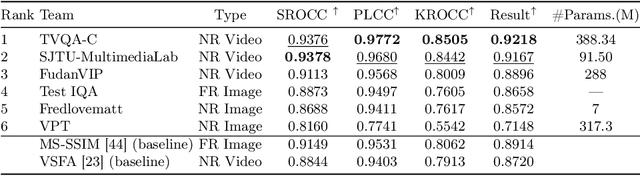
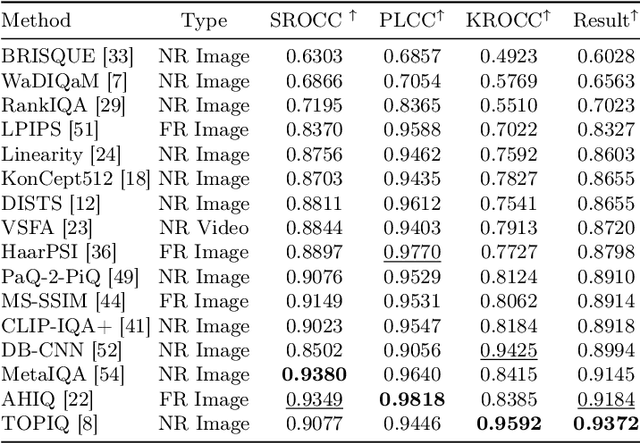
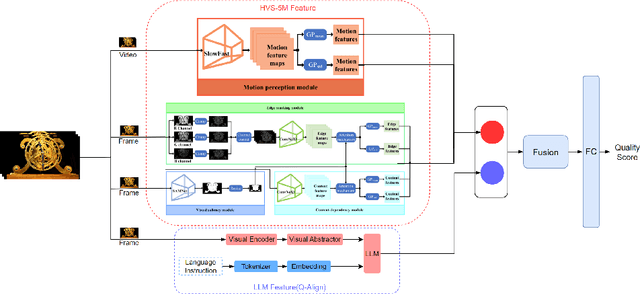
Video quality assessment (VQA) is a crucial task in the development of video compression standards, as it directly impacts the viewer experience. This paper presents the results of the Compressed Video Quality Assessment challenge, held in conjunction with the Advances in Image Manipulation (AIM) workshop at ECCV 2024. The challenge aimed to evaluate the performance of VQA methods on a diverse dataset of 459 videos, encoded with 14 codecs of various compression standards (AVC/H.264, HEVC/H.265, AV1, and VVC/H.266) and containing a comprehensive collection of compression artifacts. To measure the methods performance, we employed traditional correlation coefficients between their predictions and subjective scores, which were collected via large-scale crowdsourced pairwise human comparisons. For training purposes, participants were provided with the Compressed Video Quality Assessment Dataset (CVQAD), a previously developed dataset of 1022 videos. Up to 30 participating teams registered for the challenge, while we report the results of 6 teams, which submitted valid final solutions and code for reproducing the results. Moreover, we calculated and present the performance of state-of-the-art VQA methods on the developed dataset, providing a comprehensive benchmark for future research. The dataset, results, and online leaderboard are publicly available at https://challenges.videoprocessing.ai/challenges/compressed-video-quality-assessment.html.
Highly Efficient No-reference 4K Video Quality Assessment with Full-Pixel Covering Sampling and Training Strategy
Jul 30, 2024



Deep Video Quality Assessment (VQA) methods have shown impressive high-performance capabilities. Notably, no-reference (NR) VQA methods play a vital role in situations where obtaining reference videos is restricted or not feasible. Nevertheless, as more streaming videos are being created in ultra-high definition (e.g., 4K) to enrich viewers' experiences, the current deep VQA methods face unacceptable computational costs. Furthermore, the resizing, cropping, and local sampling techniques employed in these methods can compromise the details and content of original 4K videos, thereby negatively impacting quality assessment. In this paper, we propose a highly efficient and novel NR 4K VQA technology. Specifically, first, a novel data sampling and training strategy is proposed to tackle the problem of excessive resolution. This strategy allows the VQA Swin Transformer-based model to effectively train and make inferences using the full data of 4K videos on standard consumer-grade GPUs without compromising content or details. Second, a weighting and scoring scheme is developed to mimic the human subjective perception mode, which is achieved by considering the distinct impact of each sub-region within a 4K frame on the overall perception. Third, we incorporate the frequency domain information of video frames to better capture the details that affect video quality, consequently further improving the model's generalizability. To our knowledge, this is the first technology for the NR 4K VQA task. Thorough empirical studies demonstrate it not only significantly outperforms existing methods on a specialized 4K VQA dataset but also achieves state-of-the-art performance across multiple open-source NR video quality datasets.
Strong but Simple Baseline with Dual-Granularity Triplet Loss for Visible-Thermal Person Re-Identification
Dec 09, 2020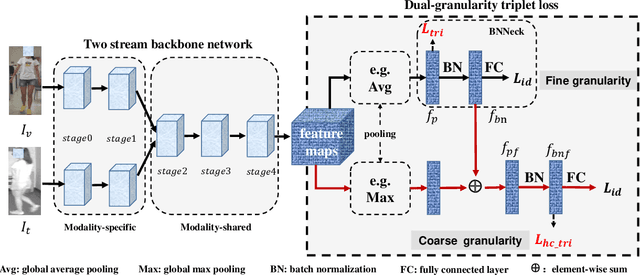
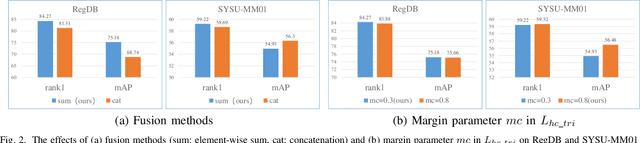
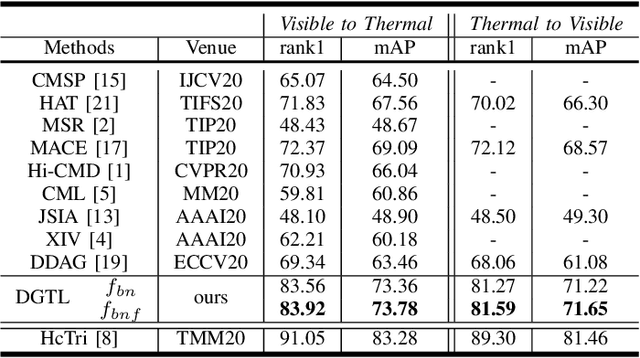
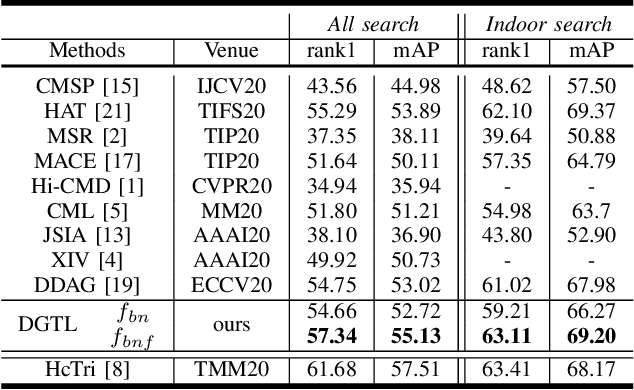
In this letter, we propose a conceptually simple and effective dual-granularity triplet loss for visible-thermal person re-identification (VT-ReID). In general, ReID models are always trained with the sample-based triplet loss and identification loss from the fine granularity level. It is possible when a center-based loss is introduced to encourage the intra-class compactness and inter-class discrimination from the coarse granularity level. Our proposed dual-granularity triplet loss well organizes the sample-based triplet loss and center-based triplet loss in a hierarchical fine to coarse granularity manner, just with some simple configurations of typical operations, such as pooling and batch normalization. Experiments on RegDB and SYSU-MM01 datasets show that with only the global features our dual-granularity triplet loss can improve the VT-ReID performance by a significant margin. It can be a strong VT-ReID baseline to boost future research with high quality.
Robust Unsupervised Small Area Change Detection from SAR Imagery Using Deep Learning
Nov 22, 2020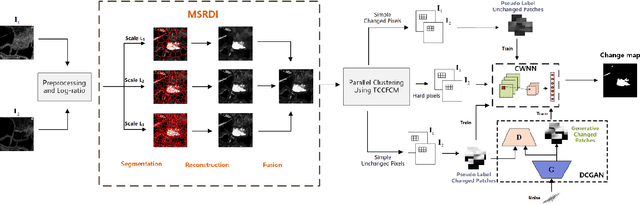
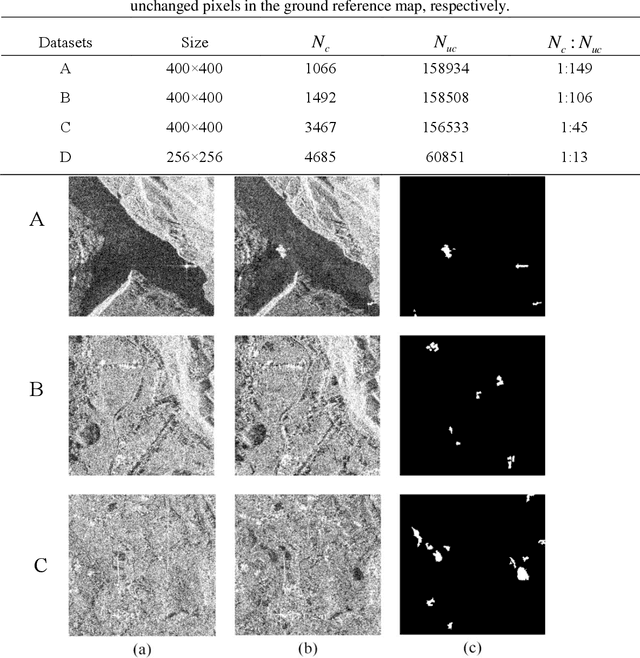
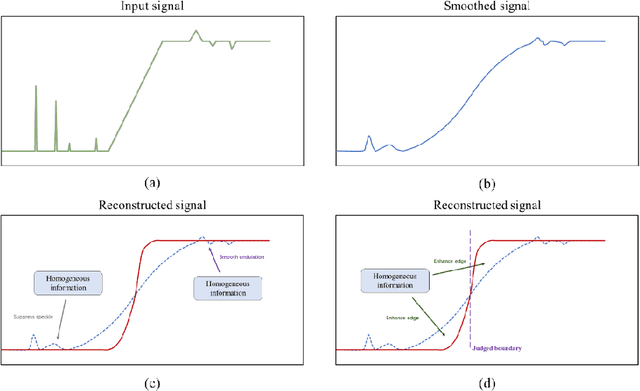
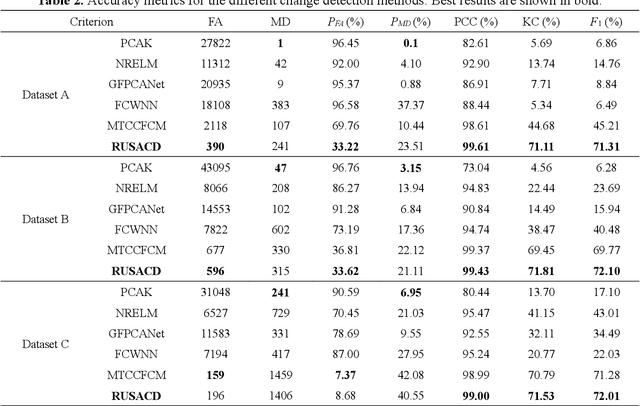
Small area change detection from synthetic aperture radar (SAR) is a highly challenging task. In this paper, a robust unsupervised approach is proposed for small area change detection from multi-temporal SAR images using deep learning. First, a multi-scale superpixel reconstruction method is developed to generate a difference image (DI), which can suppress the speckle noise effectively and enhance edges by exploiting local, spatially homogeneous information. Second, a two-stage centre-constrained fuzzy c-means clustering algorithm is proposed to divide the pixels of the DI into changed, unchanged and intermediate classes with a parallel clustering strategy. Image patches belonging to the first two classes are then constructed as pseudo-label training samples, and image patches of the intermediate class are treated as testing samples. Finally, a convolutional wavelet neural network (CWNN) is designed and trained to classify testing samples into changed or unchanged classes, coupled with a deep convolutional generative adversarial network (DCGAN) to increase the number of changed class within the pseudo-label training samples. Numerical experiments on four real SAR datasets demonstrate the validity and robustness of the proposed approach, achieving up to 99.61% accuracy for small area change detection.
Parameters Sharing Exploration and Hetero-Center based Triplet Loss for Visible-Thermal Person Re-Identification
Aug 14, 2020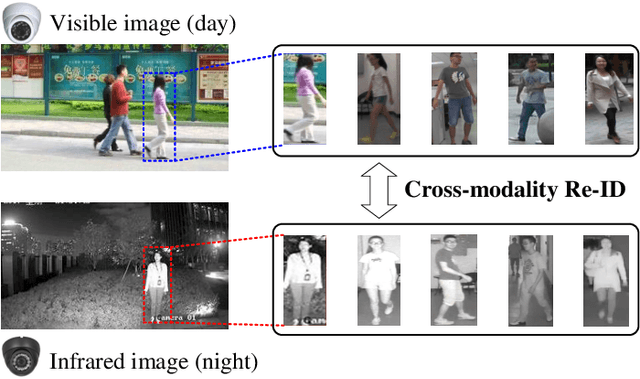
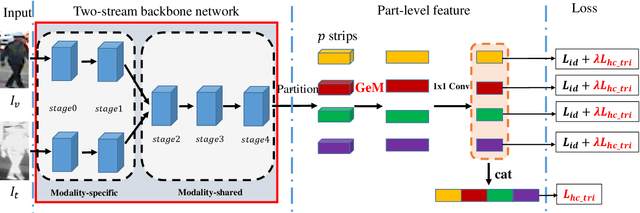
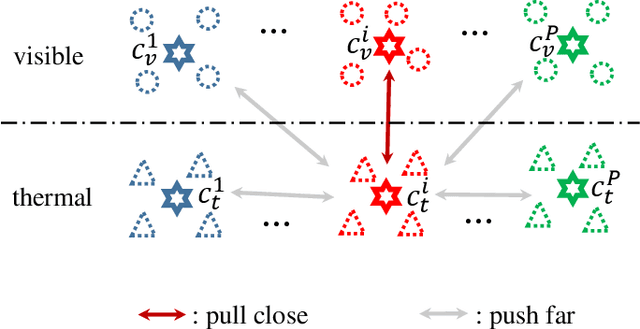
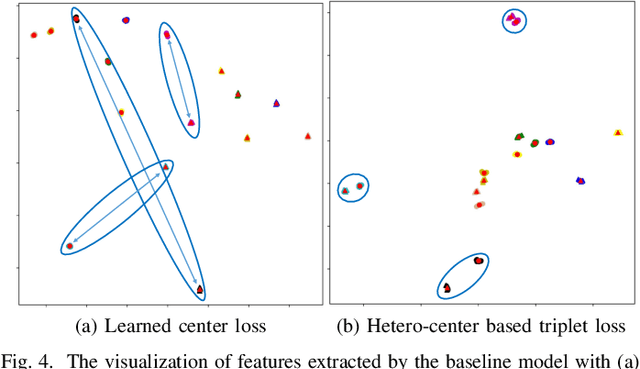
This paper focuses on the visible-thermal cross-modality person re-identification (VT Re-ID) task, whose goal is to match person images between the daytime visible modality and the nighttime thermal modality. The two-stream network is usually adopted to address the cross-modality discrepancy, the most challenging problem for VT Re-ID, by learning the multi-modality person features. In this paper, we explore how many parameters of two-stream network should share, which is still not well investigated in the existing literature. By well splitting the ResNet50 model to construct the modality-specific feature extracting network and modality-sharing feature embedding network, we experimentally demonstrate the effect of parameters sharing of two-stream network for VT Re-ID. Moreover, in the framework of part-level person feature learning, we propose the hetero-center based triplet loss to relax the strict constraint of traditional triplet loss through replacing the comparison of anchor to all the other samples by anchor center to all the other centers. With the extremely simple means, the proposed method can significantly improve the VT Re-ID performance. The experimental results on two datasets show that our proposed method distinctly outperforms the state-of-the-art methods by large margins, especially on RegDB dataset achieving superior performance, rank1/mAP/mINP 91.05%/83.28%/68.84%. It can be a new baseline for VT Re-ID, with simple but effective strategy.
A Robust Imbalanced SAR Image Change Detection Approach Based on Deep Difference Image and PCANet
Mar 03, 2020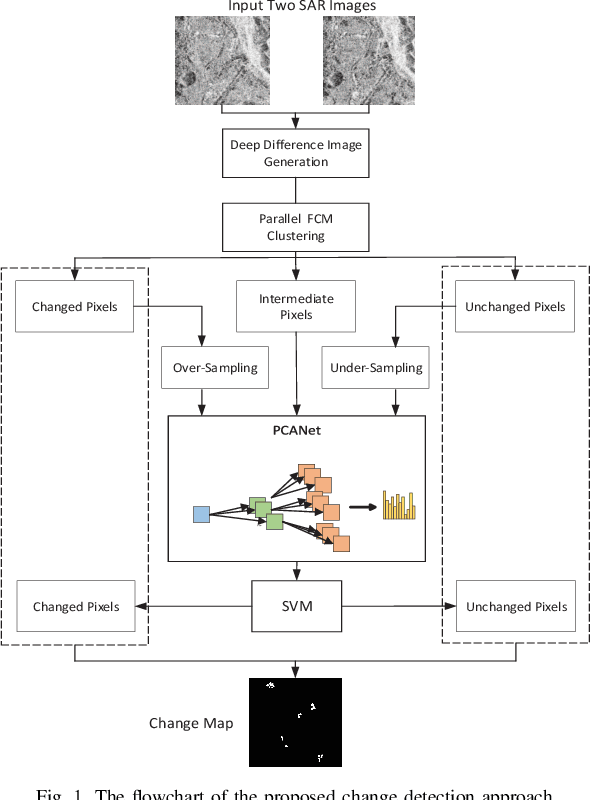
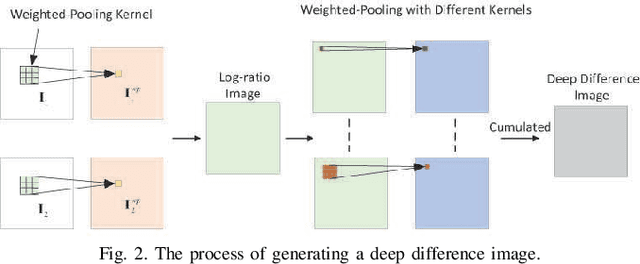

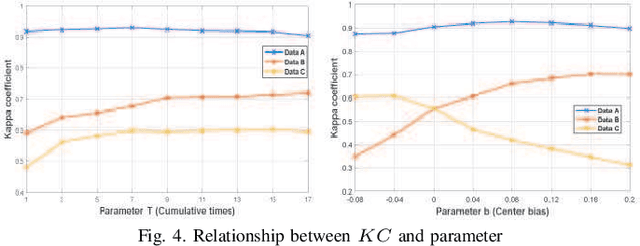
In this research, a novel robust change detection approach is presented for imbalanced multi-temporal synthetic aperture radar (SAR) image based on deep learning. Our main contribution is to develop a novel method for generating difference image and a parallel fuzzy c-means (FCM) clustering method. The main steps of our proposed approach are as follows: 1) Inspired by convolution and pooling in deep learning, a deep difference image (DDI) is obtained based on parameterized pooling leading to better speckle suppression and feature enhancement than traditional difference images. 2) Two different parameter Sigmoid nonlinear mapping are applied to the DDI to get two mapped DDIs. Parallel FCM are utilized on these two mapped DDIs to obtain three types of pseudo-label pixels, namely, changed pixels, unchanged pixels, and intermediate pixels. 3) A PCANet with support vector machine (SVM) are trained to classify intermediate pixels to be changed or unchanged. Three imbalanced multi-temporal SAR image sets are used for change detection experiments. The experimental results demonstrate that the proposed approach is effective and robust for imbalanced SAR data, and achieve up to 99.52% change detection accuracy superior to most state-of-the-art methods.
Classification Algorithm of Speech Data of Parkinsons Disease Based on Convolution Sparse Kernel Transfer Learning with Optimal Kernel and Parallel Sample Feature Selection
Feb 10, 2020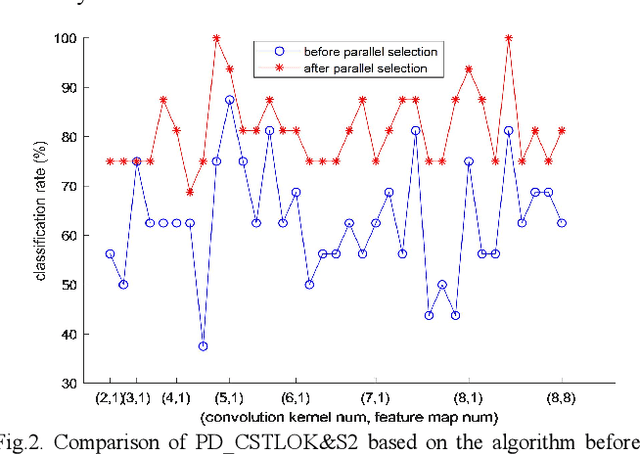
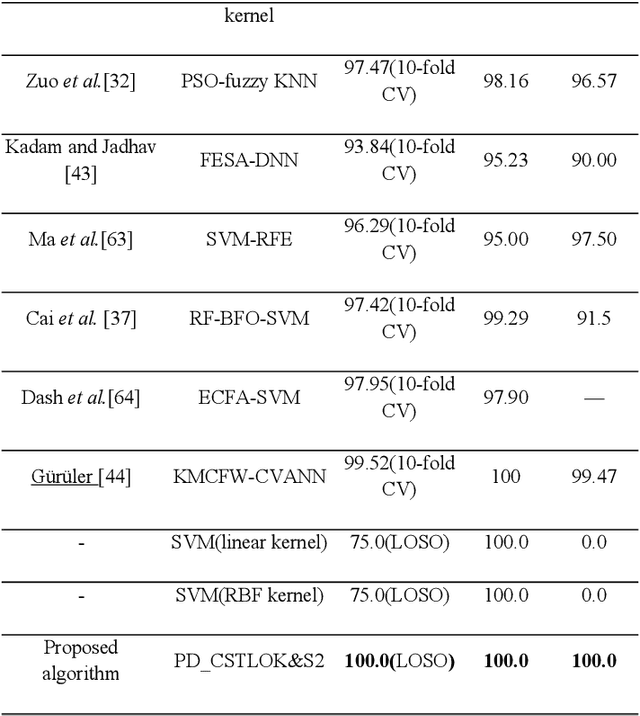
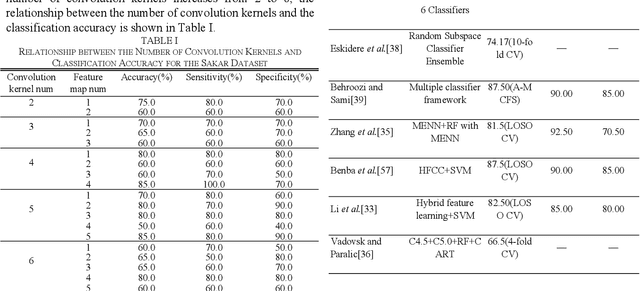

Labeled speech data from patients with Parkinsons disease (PD) are scarce, and the statistical distributions of training and test data differ significantly in the existing datasets. To solve these problems, dimensional reduction and sample augmentation must be considered. In this paper, a novel PD classification algorithm based on sparse kernel transfer learning combined with a parallel optimization of samples and features is proposed. Sparse transfer learning is used to extract effective structural information of PD speech features from public datasets as source domain data, and the fast ADDM iteration is improved to enhance the information extraction performance. To implement the parallel optimization, the potential relationships between samples and features are considered to obtain high-quality combined features. First, features are extracted from a specific public speech dataset to construct a feature dataset as the source domain. Then, the PD target domain, including the training and test datasets, is encoded by convolution sparse coding, which can extract more in-depth information. Next, parallel optimization is implemented. To further improve the classification performance, a convolution kernel optimization mechanism is designed. Using two representative public datasets and one self-constructed dataset, the experiments compare over thirty relevant algorithms. The results show that when taking the Sakar dataset, MaxLittle dataset and DNSH dataset as target domains, the proposed algorithm achieves obvious improvements in classification accuracy. The study also found large improvements in the algorithms in this paper compared with nontransfer learning approaches, demonstrating that transfer learning is both more effective and has a more acceptable time cost.
Two-Phase Object-Based Deep Learning for Multi-temporal SAR Image Change Detection
Jan 17, 2020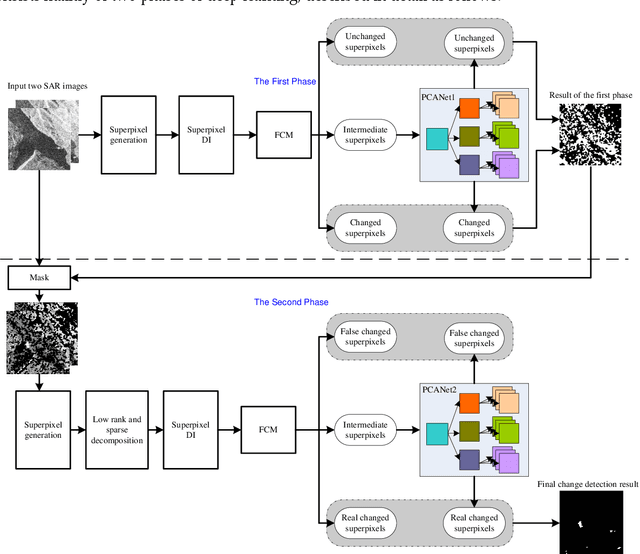
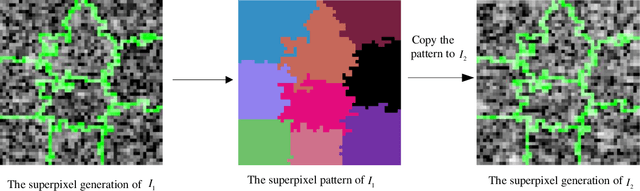
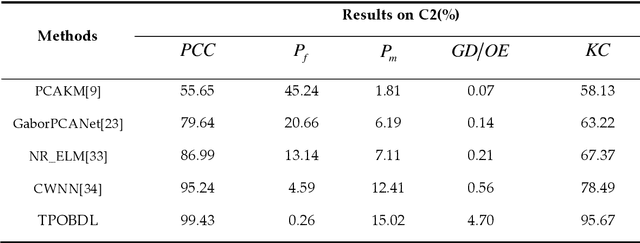
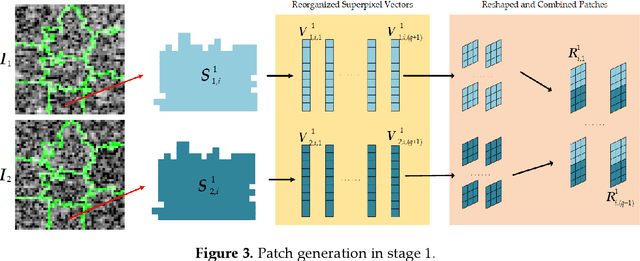
Change detection is one of the fundamental applications of synthetic aperture radar (SAR) images. However, speckle noise presented in SAR images has a much negative effect on change detection. In this research, a novel two-phase object-based deep learning approach is proposed for multi-temporal SAR image change detection. Compared with traditional methods, the proposed approach brings two main innovations. One is to classify all pixels into three categories rather than two categories: unchanged pixels, changed pixels caused by strong speckle (false changes), and changed pixels formed by real terrain variation (real changes). The other is to group neighboring pixels into segmented into superpixel objects (from pixels) such as to exploit local spatial context. Two phases are designed in the methodology: 1) Generate objects based on the simple linear iterative clustering algorithm, and discriminate these objects into changed and unchanged classes using fuzzy c-means (FCM) clustering and a deep PCANet. The prediction of this Phase is the set of changed and unchanged superpixels. 2) Deep learning on the pixel sets over the changed superpixels only, obtained in the first phase, to discriminate real changes from false changes. SLIC is employed again to achieve new superpixels in the second phase. Low rank and sparse decomposition are applied to these new superpixels to suppress speckle noise significantly. A further clustering step is applied to these new superpixels via FCM. A new PCANet is then trained to classify two kinds of changed superpixels to achieve the final change maps. Numerical experiments demonstrate that, compared with benchmark methods, the proposed approach can distinguish real changes from false changes effectively with significantly reduced false alarm rates, and achieve up to 99.71% change detection accuracy using multi-temporal SAR imagery.