 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Fine-to-Coarse Reconstruction for Accurate Low-Bit Post-Training Quantization in Vision Transformers
Dec 19, 2024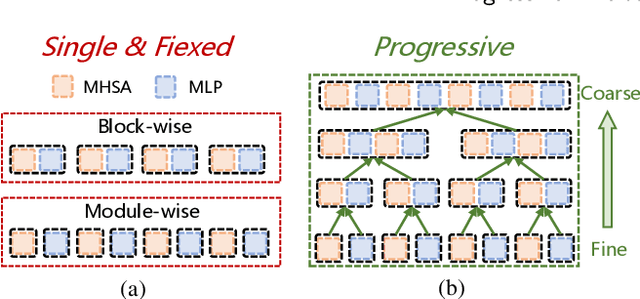
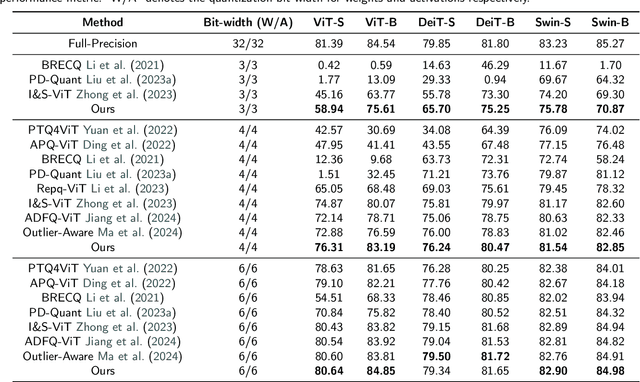
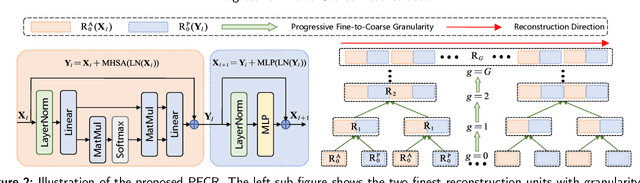
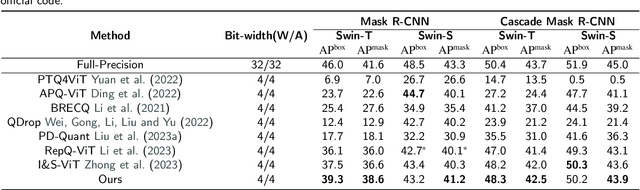
Due to its efficiency, Post-Training Quantization (PTQ) has been widely adopted for compressing Vision Transformers (ViTs). However, when quantized into low-bit representations, there is often a significant performance drop compared to their full-precision counterparts. To address this issue, reconstruction methods have been incorporated into the PTQ framework to improve performance in low-bit quantization settings. Nevertheless, existing related methods predefine the reconstruction granularity and seldom explore the progressive relationships between different reconstruction granularities, which leads to sub-optimal quantization results in ViTs. To this end, in this paper, we propose a Progressive Fine-to-Coarse Reconstruction (PFCR) method for accurate PTQ, which significantly improves the performance of low-bit quantized vision transformers. Specifically, we define multi-head self-attention and multi-layer perceptron modules along with their shortcuts as the finest reconstruction units. After reconstructing these two fine-grained units, we combine them to form coarser blocks and reconstruct them at a coarser granularity level. We iteratively perform this combination and reconstruction process, achieving progressive fine-to-coarse reconstruction. Additionally, we introduce a Progressive Optimization Strategy (POS) for PFCR to alleviate the difficulty of training, thereby further enhancing model performance. Experimental results on the ImageNet dataset demonstrate that our proposed method achieves the best Top-1 accuracy among state-of-the-art methods, particularly attaining 75.61% for 3-bit quantized ViT-B in PTQ. Besides, quantization results on the COCO dataset reveal the effectiveness and generalization of our proposed method on other computer vision tasks like object detection and instance segmentation.
MambaSOD: Dual Mamba-Driven Cross-Modal Fusion Network for RGB-D Salient Object Detection
Oct 19, 2024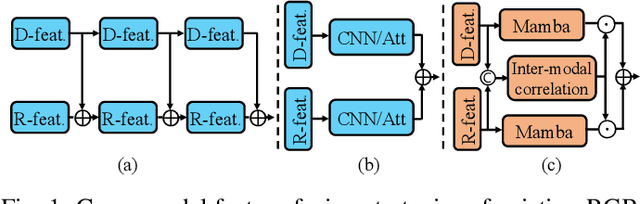
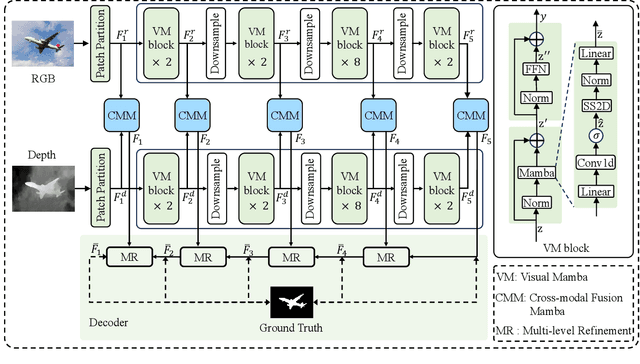
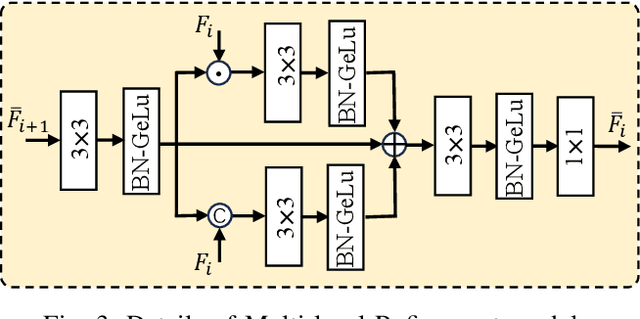
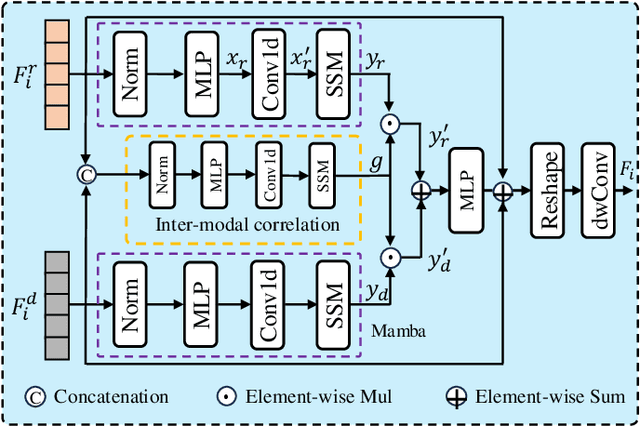
The purpose of RGB-D Salient Object Detection (SOD) is to pinpoint the most visually conspicuous areas within images accurately. While conventional deep models heavily rely on CNN extractors and overlook the long-range contextual dependencies, subsequent transformer-based models have addressed the issue to some extent but introduce high computational complexity. Moreover, incorporating spatial information from depth maps has been proven effective for this task. A primary challenge of this issue is how to fuse the complementary information from RGB and depth effectively. In this paper, we propose a dual Mamba-driven cross-modal fusion network for RGB-D SOD, named MambaSOD. Specifically, we first employ a dual Mamba-driven feature extractor for both RGB and depth to model the long-range dependencies in multiple modality inputs with linear complexity. Then, we design a cross-modal fusion Mamba for the captured multi-modal features to fully utilize the complementary information between the RGB and depth features. To the best of our knowledge, this work is the first attempt to explore the potential of the Mamba in the RGB-D SOD task, offering a novel perspective. Numerous experiments conducted on six prevailing datasets demonstrate our method's superiority over sixteen state-of-the-art RGB-D SOD models. The source code will be released at https://github.com/YueZhan721/MambaSOD.
EigenSR: Eigenimage-Bridged Pre-Trained RGB Learners for Single Hyperspectral Image Super-Resolution
Sep 06, 2024



Single hyperspectral image super-resolution (single-HSI-SR) aims to improve the resolution of a single input low-resolution HSI. Due to the bottleneck of data scarcity, the development of single-HSI-SR lags far behind that of RGB natural images. In recent years, research on RGB SR has shown that models pre-trained on large-scale benchmark datasets can greatly improve performance on unseen data, which may stand as a remedy for HSI. But how can we transfer the pre-trained RGB model to HSI, to overcome the data-scarcity bottleneck? Because of the significant difference in the channels between the pre-trained RGB model and the HSI, the model cannot focus on the correlation along the spectral dimension, thus limiting its ability to utilize on HSI. Inspired by the HSI spatial-spectral decoupling, we propose a new framework that first fine-tunes the pre-trained model with the spatial components (known as eigenimages), and then infers on unseen HSI using an iterative spectral regularization (ISR) to maintain the spectral correlation. The advantages of our method lie in: 1) we effectively inject the spatial texture processing capabilities of the pre-trained RGB model into HSI while keeping spectral fidelity, 2) learning in the spectral-decorrelated domain can improve the generalizability to spectral-agnostic data, and 3) our inference in the eigenimage domain naturally exploits the spectral low-rank property of HSI, thereby reducing the complexity. This work bridges the gap between pre-trained RGB models and HSI via eigenimages, addressing the issue of limited HSI training data, hence the name EigenSR. Extensive experiments show that EigenSR outperforms the state-of-the-art (SOTA) methods in both spatial and spectral metrics. Our code will be released.
PSE-Net: Channel Pruning for Convolutional Neural Networks with Parallel-subnets Estimator
Aug 29, 2024



Channel Pruning is one of the most widespread techniques used to compress deep neural networks while maintaining their performances. Currently, a typical pruning algorithm leverages neural architecture search to directly find networks with a configurable width, the key step of which is to identify representative subnet for various pruning ratios by training a supernet. However, current methods mainly follow a serial training strategy to optimize supernet, which is very time-consuming. In this work, we introduce PSE-Net, a novel parallel-subnets estimator for efficient channel pruning. Specifically, we propose a parallel-subnets training algorithm that simulate the forward-backward pass of multiple subnets by droping extraneous features on batch dimension, thus various subnets could be trained in one round. Our proposed algorithm facilitates the efficiency of supernet training and equips the network with the ability to interpolate the accuracy of unsampled subnets, enabling PSE-Net to effectively evaluate and rank the subnets. Over the trained supernet, we develop a prior-distributed-based sampling algorithm to boost the performance of classical evolutionary search. Such algorithm utilizes the prior information of supernet training phase to assist in the search of optimal subnets while tackling the challenge of discovering samples that satisfy resource constraints due to the long-tail distribution of network configuration. Extensive experiments demonstrate PSE-Net outperforms previous state-of-the-art channel pruning methods on the ImageNet dataset while retaining superior supernet training efficiency. For example, under 300M FLOPs constraint, our pruned MobileNetV2 achieves 75.2% Top-1 accuracy on ImageNet dataset, exceeding the original MobileNetV2 by 2.6 units while only cost 30%/16% times than BCNet/AutoAlim.
BiGSeT: Binary Mask-Guided Separation Training for DNN-based Hyperspectral Anomaly Detection
Jul 14, 2023



Hyperspectral anomaly detection (HAD) aims to recognize a minority of anomalies that are spectrally different from their surrounding background without prior knowledge. Deep neural networks (DNNs), including autoencoders (AEs), convolutional neural networks (CNNs) and vision transformers (ViTs), have shown remarkable performance in this field due to their powerful ability to model the complicated background. However, for reconstruction tasks, DNNs tend to incorporate both background and anomalies into the estimated background, which is referred to as the identical mapping problem (IMP) and leads to significantly decreased performance. To address this limitation, we propose a model-independent binary mask-guided separation training strategy for DNNs, named BiGSeT. Our method introduces a separation training loss based on a latent binary mask to separately constrain the background and anomalies in the estimated image. The background is preserved, while the potential anomalies are suppressed by using an efficient second-order Laplacian of Gaussian (LoG) operator, generating a pure background estimate. In order to maintain separability during training, we periodically update the mask using a robust proportion threshold estimated before the training. In our experiments, We adopt a vanilla AE as the network to validate our training strategy on several real-world datasets. Our results show superior performance compared to some state-of-the-art methods. Specifically, we achieved a 90.67% AUC score on the HyMap Cooke City dataset. Additionally, we applied our training strategy to other deep network structures, achieving improved detection performance compared to their original versions, demonstrating its effective transferability. The code of our method will be available at https://github.com/enter-i-username/BiGSeT.
IntraLoss: Further Margin via Gradient-Enhancing Term for Deep Face Recognition
Jul 07, 2021
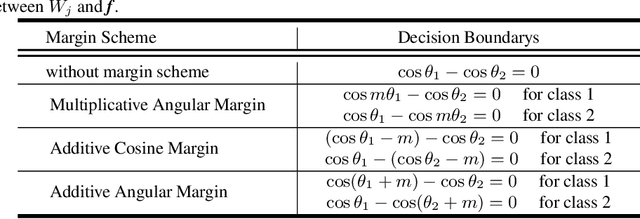
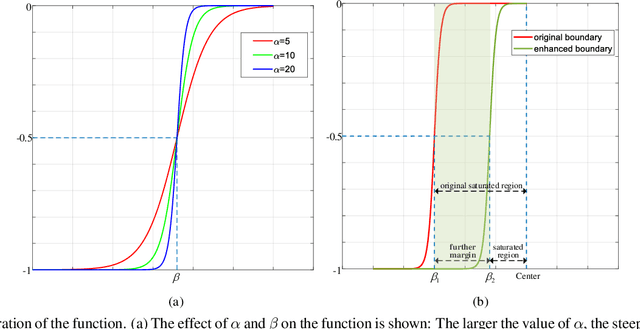

Existing classification-based face recognition methods have achieved remarkable progress, introducing large margin into hypersphere manifold to learn discriminative facial representations. However, the feature distribution is ignored. Poor feature distribution will wipe out the performance improvement brought about by margin scheme. Recent studies focus on the unbalanced inter-class distribution and form a equidistributed feature representations by penalizing the angle between identity and its nearest neighbor. But the problem is more than that, we also found the anisotropy of intra-class distribution. In this paper, we propose the `gradient-enhancing term' that concentrates on the distribution characteristics within the class. This method, named IntraLoss, explicitly performs gradient enhancement in the anisotropic region so that the intra-class distribution continues to shrink, resulting in isotropic and more compact intra-class distribution and further margin between identities. The experimental results on LFW, YTF and CFP-FP show that our outperforms state-of-the-art methods by gradient enhancement, demonstrating the superiority of our method. In addition, our method has intuitive geometric interpretation and can be easily combined with existing methods to solve the previously ignored problems.
Strong but Simple Baseline with Dual-Granularity Triplet Loss for Visible-Thermal Person Re-Identification
Dec 09, 2020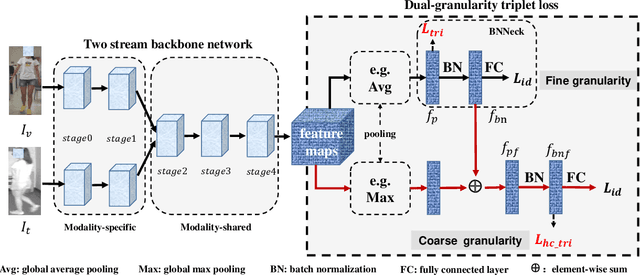
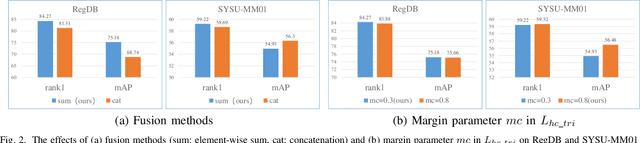
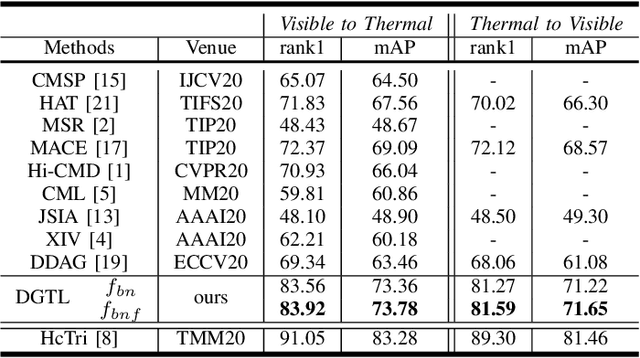
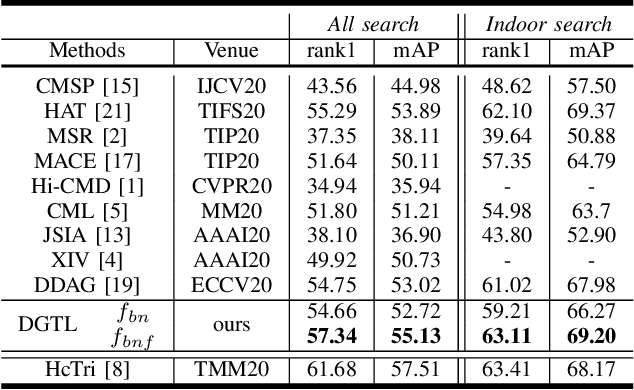
In this letter, we propose a conceptually simple and effective dual-granularity triplet loss for visible-thermal person re-identification (VT-ReID). In general, ReID models are always trained with the sample-based triplet loss and identification loss from the fine granularity level. It is possible when a center-based loss is introduced to encourage the intra-class compactness and inter-class discrimination from the coarse granularity level. Our proposed dual-granularity triplet loss well organizes the sample-based triplet loss and center-based triplet loss in a hierarchical fine to coarse granularity manner, just with some simple configurations of typical operations, such as pooling and batch normalization. Experiments on RegDB and SYSU-MM01 datasets show that with only the global features our dual-granularity triplet loss can improve the VT-ReID performance by a significant margin. It can be a strong VT-ReID baseline to boost future research with high quality.
Parameters Sharing Exploration and Hetero-Center based Triplet Loss for Visible-Thermal Person Re-Identification
Aug 14, 2020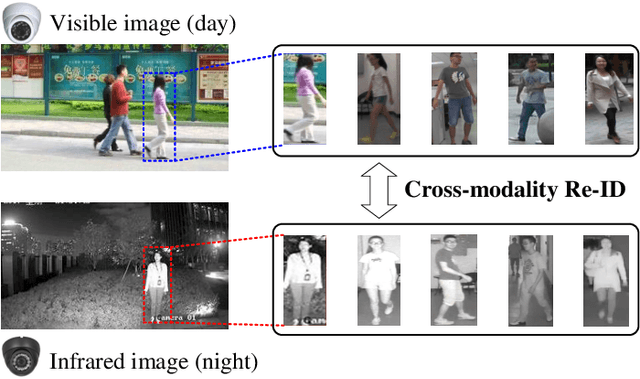
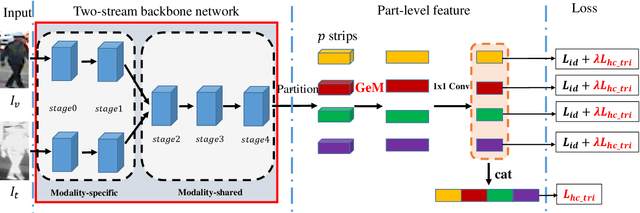
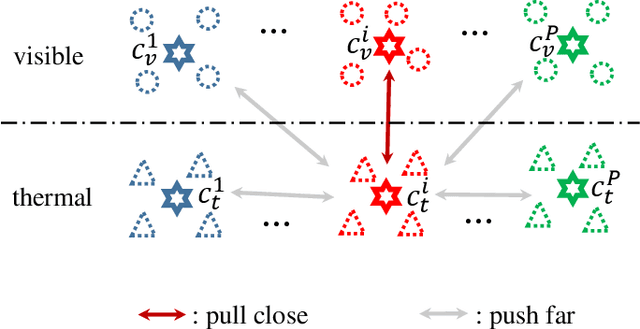
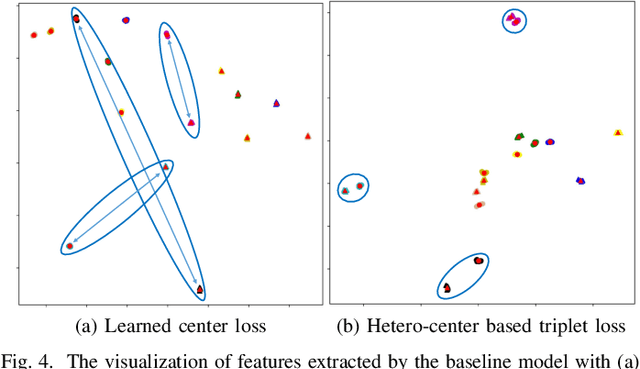
This paper focuses on the visible-thermal cross-modality person re-identification (VT Re-ID) task, whose goal is to match person images between the daytime visible modality and the nighttime thermal modality. The two-stream network is usually adopted to address the cross-modality discrepancy, the most challenging problem for VT Re-ID, by learning the multi-modality person features. In this paper, we explore how many parameters of two-stream network should share, which is still not well investigated in the existing literature. By well splitting the ResNet50 model to construct the modality-specific feature extracting network and modality-sharing feature embedding network, we experimentally demonstrate the effect of parameters sharing of two-stream network for VT Re-ID. Moreover, in the framework of part-level person feature learning, we propose the hetero-center based triplet loss to relax the strict constraint of traditional triplet loss through replacing the comparison of anchor to all the other samples by anchor center to all the other centers. With the extremely simple means, the proposed method can significantly improve the VT Re-ID performance. The experimental results on two datasets show that our proposed method distinctly outperforms the state-of-the-art methods by large margins, especially on RegDB dataset achieving superior performance, rank1/mAP/mINP 91.05%/83.28%/68.84%. It can be a new baseline for VT Re-ID, with simple but effective strategy.
Neural Network Activation Quantization with Bitwise Information Bottlenecks
Jun 09, 2020
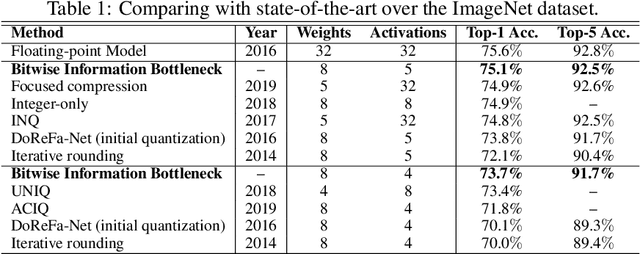


Recent researches on information bottleneck shed new light on the continuous attempts to open the black box of neural signal encoding. Inspired by the problem of lossy signal compression for wireless communication, this paper presents a Bitwise Information Bottleneck approach for quantizing and encoding neural network activations. Based on the rate-distortion theory, the Bitwise Information Bottleneck attempts to determine the most significant bits in activation representation by assigning and approximating the sparse coefficient associated with each bit. Given the constraint of a limited average code rate, the information bottleneck minimizes the rate-distortion for optimal activation quantization in a flexible layer-by-layer manner. Experiments over ImageNet and other datasets show that, by minimizing the quantization rate-distortion of each layer, the neural network with information bottlenecks achieves the state-of-the-art accuracy with low-precision activation. Meanwhile, by reducing the code rate, the proposed method can improve the memory and computational efficiency by over six times compared with the deep neural network with standard single-precision representation. Codes will be available on GitHub when the paper is accepted \url{https://github.com/BitBottleneck/PublicCode}.
Enhancing the Discriminative Feature Learning for Visible-Thermal Cross-Modality Person Re-Identification
Jul 23, 2019



Existing person re-identification has achieved great progress in the visible domain, capturing all the person images with visible cameras. However, in a 24-hour intelligent surveillance system, the visible cameras may be noneffective at night. In this situation, thermal cameras are the best supplemental components, which capture images without depending on visible light. Therefore, in this paper, we investigate the visible-thermal cross-modality person re-identification (VT Re-ID) problem. In VT Re-ID, there are two knotty problems should be well handled, cross-modality discrepancy and intra-modality variations. To address these two issues, we propose focusing on enhancing the discriminative feature learning (EDFL) with two extreme simple means from two core aspects, (1) skip-connection for mid-level features incorporation to improve the person features with more discriminability and robustness, and (2) dual-modality triplet loss to guide the training procedures by simultaneously considering the cross-modality discrepancy and intra-modality variations. Additionally, the two-stream CNN structure is adopted to learn the multi-modality sharable person features. The experimental results on two datasets show that our proposed EDFL approach distinctly outperforms state-of-the-art methods by large margins, demonstrating the effectiveness of our EDFL to enhance the discriminative feature learning for VT Re-ID.