 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMambaSOD: Dual Mamba-Driven Cross-Modal Fusion Network for RGB-D Salient Object Detection
Oct 19, 2024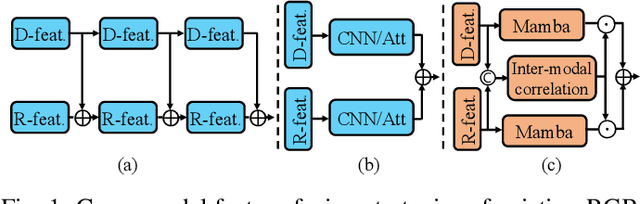
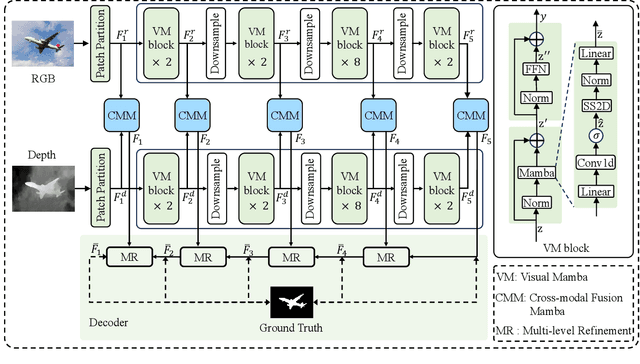
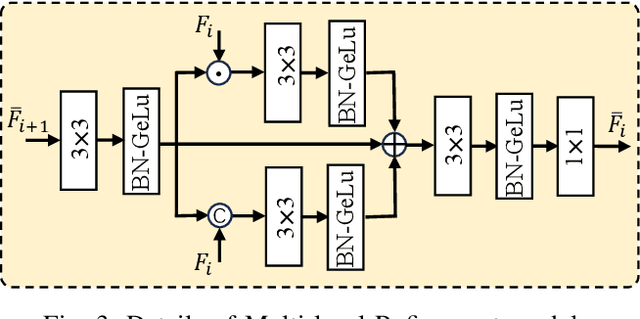
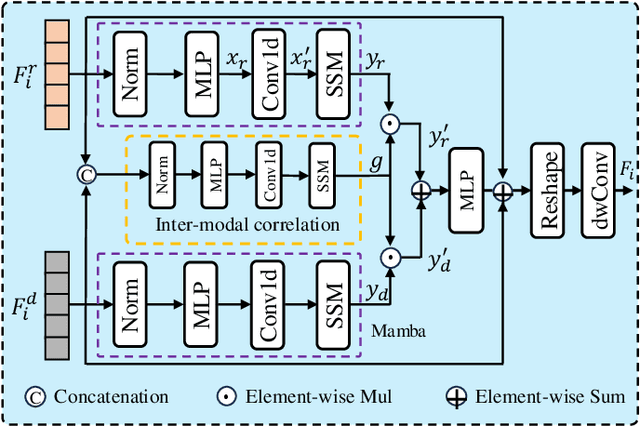
The purpose of RGB-D Salient Object Detection (SOD) is to pinpoint the most visually conspicuous areas within images accurately. While conventional deep models heavily rely on CNN extractors and overlook the long-range contextual dependencies, subsequent transformer-based models have addressed the issue to some extent but introduce high computational complexity. Moreover, incorporating spatial information from depth maps has been proven effective for this task. A primary challenge of this issue is how to fuse the complementary information from RGB and depth effectively. In this paper, we propose a dual Mamba-driven cross-modal fusion network for RGB-D SOD, named MambaSOD. Specifically, we first employ a dual Mamba-driven feature extractor for both RGB and depth to model the long-range dependencies in multiple modality inputs with linear complexity. Then, we design a cross-modal fusion Mamba for the captured multi-modal features to fully utilize the complementary information between the RGB and depth features. To the best of our knowledge, this work is the first attempt to explore the potential of the Mamba in the RGB-D SOD task, offering a novel perspective. Numerous experiments conducted on six prevailing datasets demonstrate our method's superiority over sixteen state-of-the-art RGB-D SOD models. The source code will be released at https://github.com/YueZhan721/MambaSOD.