 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUDD: Dataset Distillation via Mining Underutilized Regions
Aug 29, 2024



Dataset distillation synthesizes a small dataset such that a model trained on this set approximates the performance of the original dataset. Recent studies on dataset distillation focused primarily on the design of the optimization process, with methods such as gradient matching, feature alignment, and training trajectory matching. However, little attention has been given to the issue of underutilized regions in synthetic images. In this paper, we propose UDD, a novel approach to identify and exploit the underutilized regions to make them informative and discriminate, and thus improve the utilization of the synthetic dataset. Technically, UDD involves two underutilized regions searching policies for different conditions, i.e., response-based policy and data jittering-based policy. Compared with previous works, such two policies are utilization-sensitive, equipping with the ability to dynamically adjust the underutilized regions during the training process. Additionally, we analyze the current model optimization problem and design a category-wise feature contrastive loss, which can enhance the distinguishability of different categories and alleviate the shortcomings of the existing multi-formation methods. Experimentally, our method improves the utilization of the synthetic dataset and outperforms the state-of-the-art methods on various datasets, such as MNIST, FashionMNIST, SVHN, CIFAR-10, and CIFAR-100. For example, the improvements on CIFAR-10 and CIFAR-100 are 4.0\% and 3.7\% over the next best method with IPC=1, by mining the underutilized regions.
PSE-Net: Channel Pruning for Convolutional Neural Networks with Parallel-subnets Estimator
Aug 29, 2024



Channel Pruning is one of the most widespread techniques used to compress deep neural networks while maintaining their performances. Currently, a typical pruning algorithm leverages neural architecture search to directly find networks with a configurable width, the key step of which is to identify representative subnet for various pruning ratios by training a supernet. However, current methods mainly follow a serial training strategy to optimize supernet, which is very time-consuming. In this work, we introduce PSE-Net, a novel parallel-subnets estimator for efficient channel pruning. Specifically, we propose a parallel-subnets training algorithm that simulate the forward-backward pass of multiple subnets by droping extraneous features on batch dimension, thus various subnets could be trained in one round. Our proposed algorithm facilitates the efficiency of supernet training and equips the network with the ability to interpolate the accuracy of unsampled subnets, enabling PSE-Net to effectively evaluate and rank the subnets. Over the trained supernet, we develop a prior-distributed-based sampling algorithm to boost the performance of classical evolutionary search. Such algorithm utilizes the prior information of supernet training phase to assist in the search of optimal subnets while tackling the challenge of discovering samples that satisfy resource constraints due to the long-tail distribution of network configuration. Extensive experiments demonstrate PSE-Net outperforms previous state-of-the-art channel pruning methods on the ImageNet dataset while retaining superior supernet training efficiency. For example, under 300M FLOPs constraint, our pruned MobileNetV2 achieves 75.2% Top-1 accuracy on ImageNet dataset, exceeding the original MobileNetV2 by 2.6 units while only cost 30%/16% times than BCNet/AutoAlim.
Attention: A Big Surprise for Cross-Domain Person Re-Identification
May 30, 2019
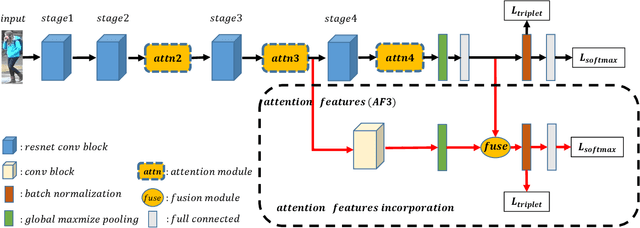
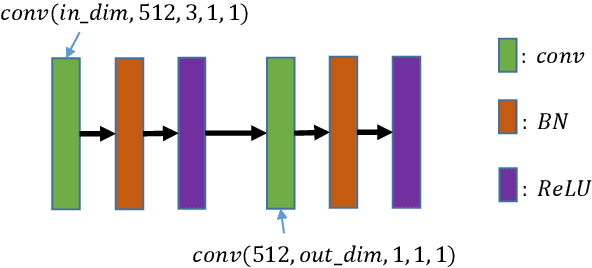
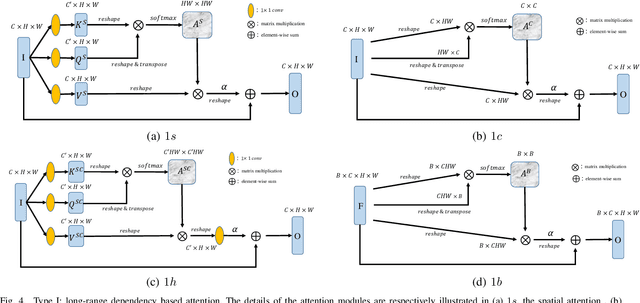
In this paper, we focus on model generalization and adaptation for cross-domain person re-identification (Re-ID). Unlike existing cross-domain Re-ID methods, leveraging the auxiliary information of those unlabeled target-domain data, we aim at enhancing the model generalization and adaptation by discriminative feature learning, and directly exploiting a pre-trained model to new domains (datasets) without any utilization of the information from target domains. To address the discriminative feature learning problem, we surprisingly find that simply introducing the attention mechanism to adaptively extract the person features for every domain is of great effectiveness. We adopt two popular type of attention mechanisms, long-range dependency based attention and direct generation based attention. Both of them can perform the attention via spatial or channel dimensions alone, even the combination of spatial and channel dimensions. The outline of different attentions are well illustrated. Moreover, we also incorporate the attention results into the final output of model through skip-connection to improve the features with both high and middle level semantic visual information. In the manner of directly exploiting a pre-trained model to new domains, the attention incorporation method truly could enhance the model generalization and adaptation to perform the cross-domain person Re-ID. We conduct extensive experiments between three large datasets, Market-1501, DukeMTMC-reID and MSMT17. Surprisingly, introducing only attention can achieve state-of-the-art performance, even much better than those cross-domain Re-ID methods utilizing auxiliary information from the target domain.
Temporal Action Detection by Joint Identification-Verification
Oct 19, 2018



Temporal action detection aims at not only recognizing action category but also detecting start time and end time for each action instance in an untrimmed video. The key challenge of this task is to accurately classify the action and determine the temporal boundaries of each action instance. In temporal action detection benchmark: THUMOS 2014, large variations exist in the same action category while many similarities exist in different action categories, which always limit the performance of temporal action detection. To address this problem, we propose to use joint Identification-Verification network to reduce the intra-action variations and enlarge inter-action differences. The joint Identification-Verification network is a siamese network based on 3D ConvNets, which can simultaneously predict the action categories and the similarity scores for the input pairs of video proposal segments. Extensive experimental results on the challenging THUMOS 2014 dataset demonstrate the effectiveness of our proposed method compared to the existing state-of-art methods for temporal action detection in untrimmed videos.
PCN: Part and Context Information for Pedestrian Detection with CNNs
Apr 12, 2018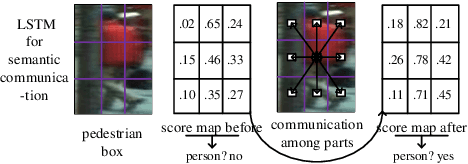


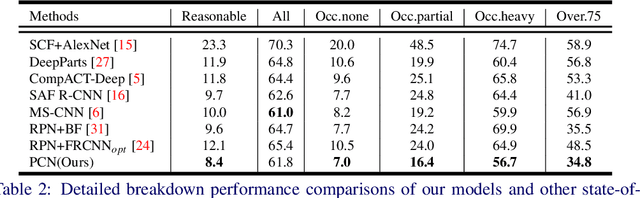
Pedestrian detection has achieved great improvements in recent years, while complex occlusion handling is still one of the most important problems. To take advantage of the body parts and context information for pedestrian detection, we propose the part and context network (PCN) in this work. PCN specially utilizes two branches which detect the pedestrians through body parts semantic and context information, respectively. In the Part Branch, the semantic information of body parts can communicate with each other via recurrent neural networks. In the Context Branch, we adopt a local competition mechanism for adaptive context scale selection. By combining the outputs of all branches, we develop a strong complementary pedestrian detector with a lower miss rate and better localization accuracy, especially for occlusion pedestrian. Comprehensive evaluations on two challenging pedestrian detection datasets (i.e. Caltech and INRIA) well demonstrated the effectiveness of the proposed PCN.