 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGloTok: Global Perspective Tokenizer for Image Reconstruction and Generation
Nov 19, 2025Existing state-of-the-art image tokenization methods leverage diverse semantic features from pre-trained vision models for additional supervision, to expand the distribution of latent representations and thereby improve the quality of image reconstruction and generation. These methods employ a locally supervised approach for semantic supervision, which limits the uniformity of semantic distribution. However, VA-VAE proves that a more uniform feature distribution yields better generation performance. In this work, we introduce a Global Perspective Tokenizer (GloTok), which utilizes global relational information to model a more uniform semantic distribution of tokenized features. Specifically, a codebook-wise histogram relation learning method is proposed to transfer the semantics, which are modeled by pre-trained models on the entire dataset, to the semantic codebook. Then, we design a residual learning module that recovers the fine-grained details to minimize the reconstruction error caused by quantization. Through the above design, GloTok delivers more uniformly distributed semantic latent representations, which facilitates the training of autoregressive (AR) models for generating high-quality images without requiring direct access to pre-trained models during the training process. Experiments on the standard ImageNet-1k benchmark clearly show that our proposed method achieves state-of-the-art reconstruction performance and generation quality.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
UDD: Dataset Distillation via Mining Underutilized Regions
Aug 29, 2024



Dataset distillation synthesizes a small dataset such that a model trained on this set approximates the performance of the original dataset. Recent studies on dataset distillation focused primarily on the design of the optimization process, with methods such as gradient matching, feature alignment, and training trajectory matching. However, little attention has been given to the issue of underutilized regions in synthetic images. In this paper, we propose UDD, a novel approach to identify and exploit the underutilized regions to make them informative and discriminate, and thus improve the utilization of the synthetic dataset. Technically, UDD involves two underutilized regions searching policies for different conditions, i.e., response-based policy and data jittering-based policy. Compared with previous works, such two policies are utilization-sensitive, equipping with the ability to dynamically adjust the underutilized regions during the training process. Additionally, we analyze the current model optimization problem and design a category-wise feature contrastive loss, which can enhance the distinguishability of different categories and alleviate the shortcomings of the existing multi-formation methods. Experimentally, our method improves the utilization of the synthetic dataset and outperforms the state-of-the-art methods on various datasets, such as MNIST, FashionMNIST, SVHN, CIFAR-10, and CIFAR-100. For example, the improvements on CIFAR-10 and CIFAR-100 are 4.0\% and 3.7\% over the next best method with IPC=1, by mining the underutilized regions.
Distilling Object Detectors With Global Knowledge
Oct 17, 2022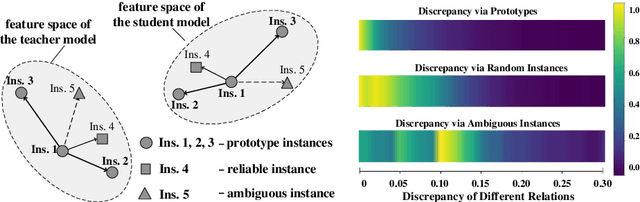
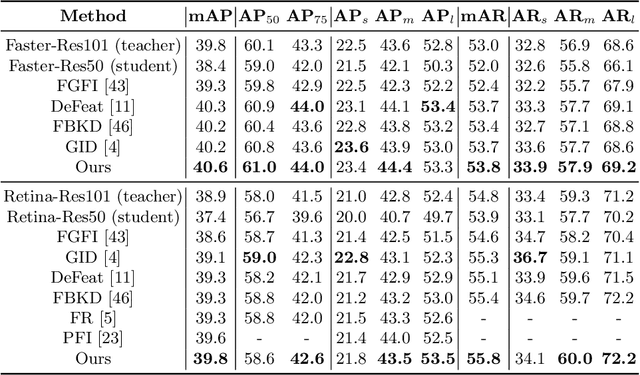
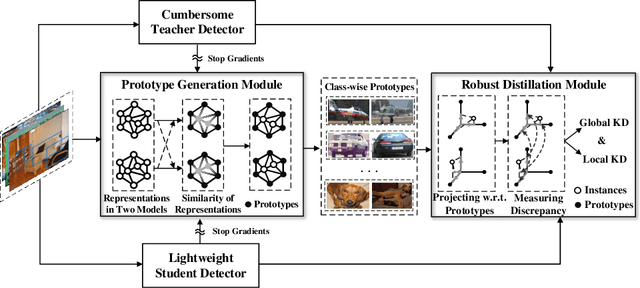
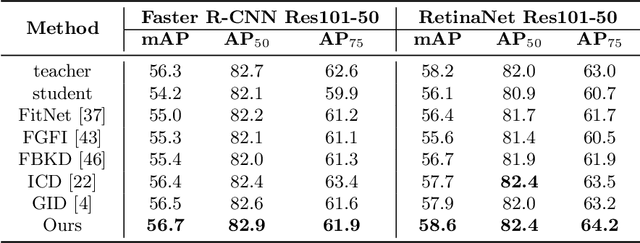
Knowledge distillation learns a lightweight student model that mimics a cumbersome teacher. Existing methods regard the knowledge as the feature of each instance or their relations, which is the instance-level knowledge only from the teacher model, i.e., the local knowledge. However, the empirical studies show that the local knowledge is much noisy in object detection tasks, especially on the blurred, occluded, or small instances. Thus, a more intrinsic approach is to measure the representations of instances w.r.t. a group of common basis vectors in the two feature spaces of the teacher and the student detectors, i.e., global knowledge. Then, the distilling algorithm can be applied as space alignment. To this end, a novel prototype generation module (PGM) is proposed to find the common basis vectors, dubbed prototypes, in the two feature spaces. Then, a robust distilling module (RDM) is applied to construct the global knowledge based on the prototypes and filtrate noisy global and local knowledge by measuring the discrepancy of the representations in two feature spaces. Experiments with Faster-RCNN and RetinaNet on PASCAL and COCO datasets show that our method achieves the best performance for distilling object detectors with various backbones, which even surpasses the performance of the teacher model. We also show that the existing methods can be easily combined with global knowledge and obtain further improvement. Code is available: https://github.com/hikvision-research/DAVAR-Lab-ML.