 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Object Detectors With Global Knowledge
Paper and Code
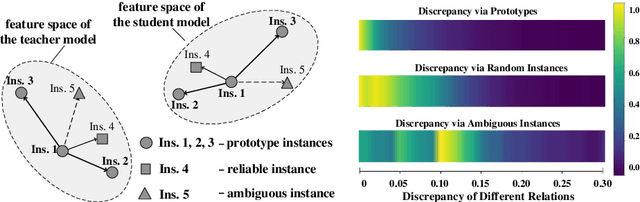
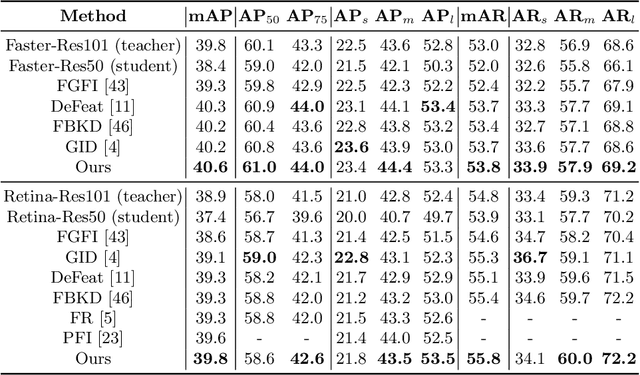
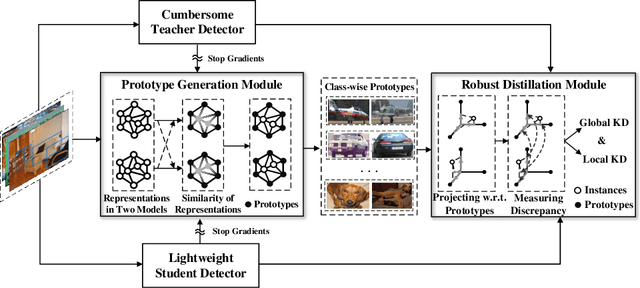
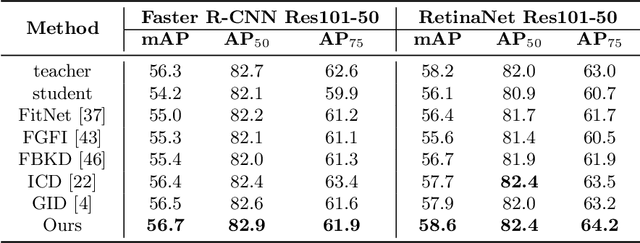
Knowledge distillation learns a lightweight student model that mimics a cumbersome teacher. Existing methods regard the knowledge as the feature of each instance or their relations, which is the instance-level knowledge only from the teacher model, i.e., the local knowledge. However, the empirical studies show that the local knowledge is much noisy in object detection tasks, especially on the blurred, occluded, or small instances. Thus, a more intrinsic approach is to measure the representations of instances w.r.t. a group of common basis vectors in the two feature spaces of the teacher and the student detectors, i.e., global knowledge. Then, the distilling algorithm can be applied as space alignment. To this end, a novel prototype generation module (PGM) is proposed to find the common basis vectors, dubbed prototypes, in the two feature spaces. Then, a robust distilling module (RDM) is applied to construct the global knowledge based on the prototypes and filtrate noisy global and local knowledge by measuring the discrepancy of the representations in two feature spaces. Experiments with Faster-RCNN and RetinaNet on PASCAL and COCO datasets show that our method achieves the best performance for distilling object detectors with various backbones, which even surpasses the performance of the teacher model. We also show that the existing methods can be easily combined with global knowledge and obtain further improvement. Code is available: https://github.com/hikvision-research/DAVAR-Lab-ML.