 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Fine-to-Coarse Reconstruction for Accurate Low-Bit Post-Training Quantization in Vision Transformers
Paper and Code
Dec 19, 2024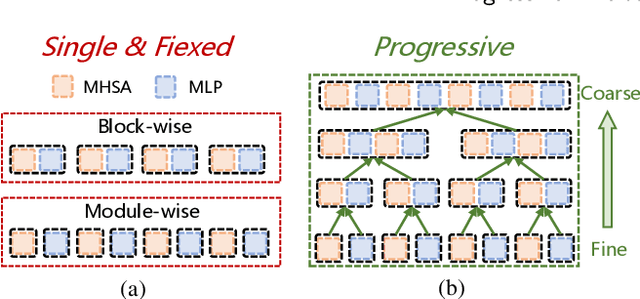
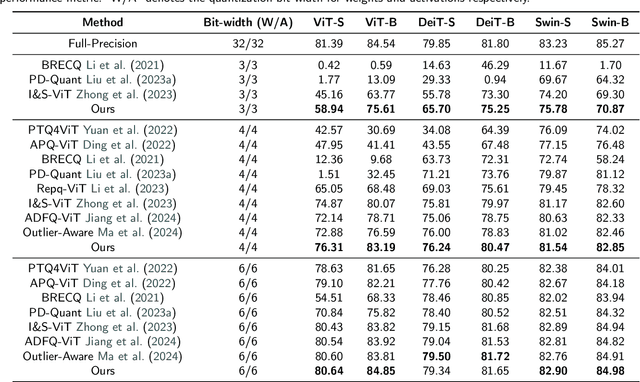
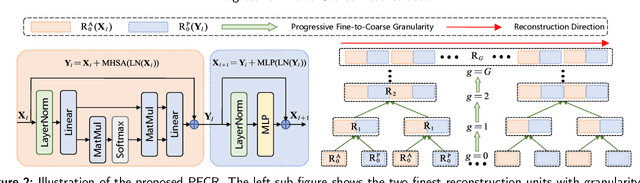
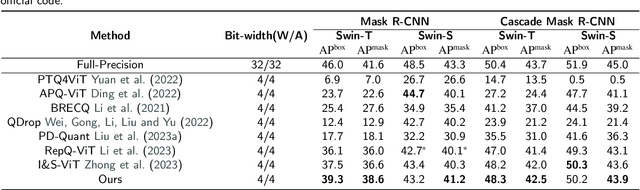
Due to its efficiency, Post-Training Quantization (PTQ) has been widely adopted for compressing Vision Transformers (ViTs). However, when quantized into low-bit representations, there is often a significant performance drop compared to their full-precision counterparts. To address this issue, reconstruction methods have been incorporated into the PTQ framework to improve performance in low-bit quantization settings. Nevertheless, existing related methods predefine the reconstruction granularity and seldom explore the progressive relationships between different reconstruction granularities, which leads to sub-optimal quantization results in ViTs. To this end, in this paper, we propose a Progressive Fine-to-Coarse Reconstruction (PFCR) method for accurate PTQ, which significantly improves the performance of low-bit quantized vision transformers. Specifically, we define multi-head self-attention and multi-layer perceptron modules along with their shortcuts as the finest reconstruction units. After reconstructing these two fine-grained units, we combine them to form coarser blocks and reconstruct them at a coarser granularity level. We iteratively perform this combination and reconstruction process, achieving progressive fine-to-coarse reconstruction. Additionally, we introduce a Progressive Optimization Strategy (POS) for PFCR to alleviate the difficulty of training, thereby further enhancing model performance. Experimental results on the ImageNet dataset demonstrate that our proposed method achieves the best Top-1 accuracy among state-of-the-art methods, particularly attaining 75.61% for 3-bit quantized ViT-B in PTQ. Besides, quantization results on the COCO dataset reveal the effectiveness and generalization of our proposed method on other computer vision tasks like object detection and instance segmentation.