 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoHIL: Robust Human-in-the-Loop Robotic Reinforcement Learning Against Illumination Variations
May 19, 2026Human-in-the-loop reinforcement learning systems achieve near-perfect success on the workstation where they are trained, but collapse when the same robot is moved to a workstation a few meters away due to shifts in the visual input distribution caused by new lamp positions and window light. Re-collecting demonstrations and re-running HIL on every workstation is incompatible with deployment, and naively fine-tuning on shifted-light data triggers catastrophic forgetting of the source workstation. To close this cross-domain gap, we present RoHIL, an offline fine-tuning framework that uses no extra real-robot interaction. RoHIL combines (i) a world-model-based image relighter that re-synthesises the visual stream of source-workstation trajectories under multiple virtual HDRI environments, leaving actions and rewards real; (ii) Illumination-Retention Replay (IRR), a data-level anti-forgetting mechanism that interleaves relit adaptation transitions with original-light retention transitions to preserve source-workstation Bellman coverage; and (iii) an anchored Bellman-actor regulariser that constrains representation and policy drift from the original source-workstation policy. Across four real-robot manipulation tasks under significant cross-workstation illumination variations, RoHIL substantially improves shifted-light performance where standard HIL-RL collapses, while preserving source-workstation performance, eliminating the need to re-collect data and retrain for every new workstation and environment. Project page: https://anonymous4365.github.io/RoHIL/
Progressive Fine-to-Coarse Reconstruction for Accurate Low-Bit Post-Training Quantization in Vision Transformers
Dec 19, 2024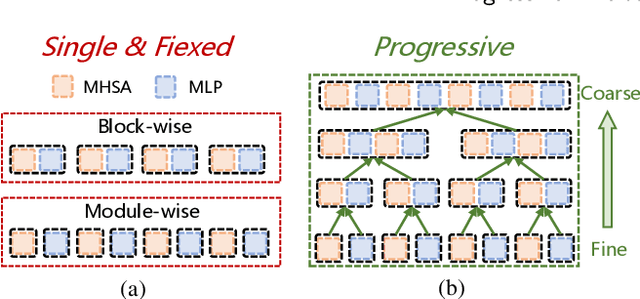
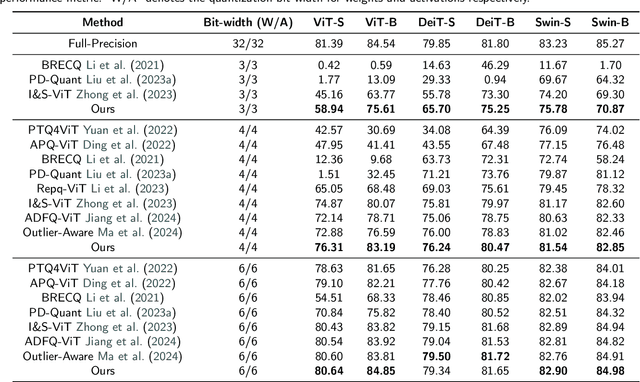
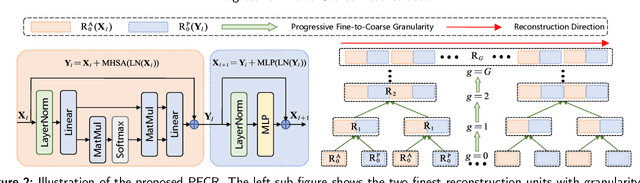
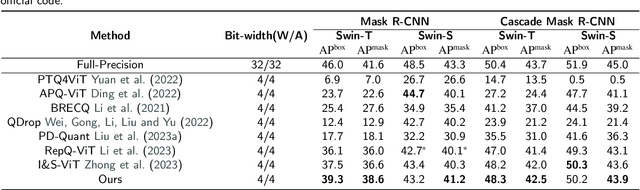
Due to its efficiency, Post-Training Quantization (PTQ) has been widely adopted for compressing Vision Transformers (ViTs). However, when quantized into low-bit representations, there is often a significant performance drop compared to their full-precision counterparts. To address this issue, reconstruction methods have been incorporated into the PTQ framework to improve performance in low-bit quantization settings. Nevertheless, existing related methods predefine the reconstruction granularity and seldom explore the progressive relationships between different reconstruction granularities, which leads to sub-optimal quantization results in ViTs. To this end, in this paper, we propose a Progressive Fine-to-Coarse Reconstruction (PFCR) method for accurate PTQ, which significantly improves the performance of low-bit quantized vision transformers. Specifically, we define multi-head self-attention and multi-layer perceptron modules along with their shortcuts as the finest reconstruction units. After reconstructing these two fine-grained units, we combine them to form coarser blocks and reconstruct them at a coarser granularity level. We iteratively perform this combination and reconstruction process, achieving progressive fine-to-coarse reconstruction. Additionally, we introduce a Progressive Optimization Strategy (POS) for PFCR to alleviate the difficulty of training, thereby further enhancing model performance. Experimental results on the ImageNet dataset demonstrate that our proposed method achieves the best Top-1 accuracy among state-of-the-art methods, particularly attaining 75.61% for 3-bit quantized ViT-B in PTQ. Besides, quantization results on the COCO dataset reveal the effectiveness and generalization of our proposed method on other computer vision tasks like object detection and instance segmentation.
STOP: Spatiotemporal Orthogonal Propagation for Weight-Threshold-Leakage Synergistic Training of Deep Spiking Neural Networks
Nov 17, 2024



The prevailing of artificial intelligence-of-things calls for higher energy-efficient edge computing paradigms, such as neuromorphic agents leveraging brain-inspired spiking neural network (SNN) models based on spatiotemporally sparse binary activations. However, the lack of efficient and high-accuracy deep SNN learning algorithms prevents them from practical edge deployments with a strictly bounded cost. In this paper, we propose a spatiotemporal orthogonal propagation (STOP) algorithm to tack this challenge. Our algorithm enables fully synergistic learning of synaptic weights as well as firing thresholds and leakage factors in spiking neurons to improve SNN accuracy, while under a unified temporally-forward trace-based framework to mitigate the huge memory requirement for storing neural states of all time-steps in the forward pass. Characteristically, the spatially-backward neuronal errors and temporally-forward traces propagate orthogonally to and independently of each other, substantially reducing computational overhead. Our STOP algorithm obtained high recognition accuracies of 99.53%, 94.84%, 74.92%, 98.26% and 77.10% on the MNIST, CIFAR-10, CIFAR-100, DVS-Gesture and DVS-CIFAR10 datasets with adequate SNNs of intermediate scales from LeNet-5 to ResNet-18. Compared with other deep SNN training works, our method is more plausible for edge intelligent scenarios where resources are limited but high-accuracy in-situ learning is desired.
EigenSR: Eigenimage-Bridged Pre-Trained RGB Learners for Single Hyperspectral Image Super-Resolution
Sep 06, 2024



Single hyperspectral image super-resolution (single-HSI-SR) aims to improve the resolution of a single input low-resolution HSI. Due to the bottleneck of data scarcity, the development of single-HSI-SR lags far behind that of RGB natural images. In recent years, research on RGB SR has shown that models pre-trained on large-scale benchmark datasets can greatly improve performance on unseen data, which may stand as a remedy for HSI. But how can we transfer the pre-trained RGB model to HSI, to overcome the data-scarcity bottleneck? Because of the significant difference in the channels between the pre-trained RGB model and the HSI, the model cannot focus on the correlation along the spectral dimension, thus limiting its ability to utilize on HSI. Inspired by the HSI spatial-spectral decoupling, we propose a new framework that first fine-tunes the pre-trained model with the spatial components (known as eigenimages), and then infers on unseen HSI using an iterative spectral regularization (ISR) to maintain the spectral correlation. The advantages of our method lie in: 1) we effectively inject the spatial texture processing capabilities of the pre-trained RGB model into HSI while keeping spectral fidelity, 2) learning in the spectral-decorrelated domain can improve the generalizability to spectral-agnostic data, and 3) our inference in the eigenimage domain naturally exploits the spectral low-rank property of HSI, thereby reducing the complexity. This work bridges the gap between pre-trained RGB models and HSI via eigenimages, addressing the issue of limited HSI training data, hence the name EigenSR. Extensive experiments show that EigenSR outperforms the state-of-the-art (SOTA) methods in both spatial and spectral metrics. Our code will be released.
BiGSeT: Binary Mask-Guided Separation Training for DNN-based Hyperspectral Anomaly Detection
Jul 14, 2023



Hyperspectral anomaly detection (HAD) aims to recognize a minority of anomalies that are spectrally different from their surrounding background without prior knowledge. Deep neural networks (DNNs), including autoencoders (AEs), convolutional neural networks (CNNs) and vision transformers (ViTs), have shown remarkable performance in this field due to their powerful ability to model the complicated background. However, for reconstruction tasks, DNNs tend to incorporate both background and anomalies into the estimated background, which is referred to as the identical mapping problem (IMP) and leads to significantly decreased performance. To address this limitation, we propose a model-independent binary mask-guided separation training strategy for DNNs, named BiGSeT. Our method introduces a separation training loss based on a latent binary mask to separately constrain the background and anomalies in the estimated image. The background is preserved, while the potential anomalies are suppressed by using an efficient second-order Laplacian of Gaussian (LoG) operator, generating a pure background estimate. In order to maintain separability during training, we periodically update the mask using a robust proportion threshold estimated before the training. In our experiments, We adopt a vanilla AE as the network to validate our training strategy on several real-world datasets. Our results show superior performance compared to some state-of-the-art methods. Specifically, we achieved a 90.67% AUC score on the HyMap Cooke City dataset. Additionally, we applied our training strategy to other deep network structures, achieving improved detection performance compared to their original versions, demonstrating its effective transferability. The code of our method will be available at https://github.com/enter-i-username/BiGSeT.
Strong but Simple Baseline with Dual-Granularity Triplet Loss for Visible-Thermal Person Re-Identification
Dec 09, 2020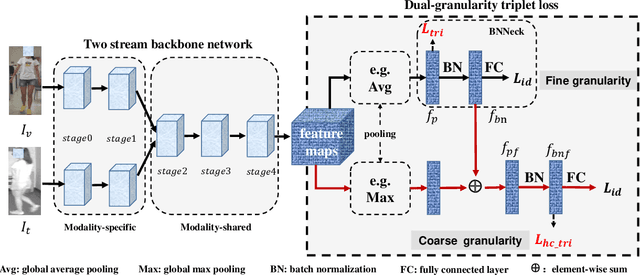
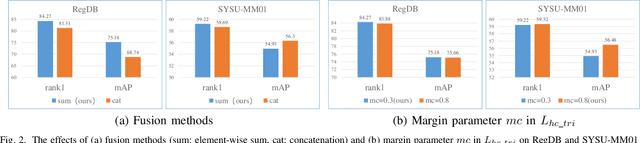
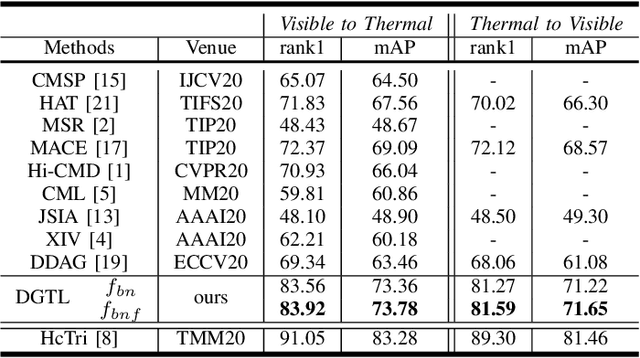
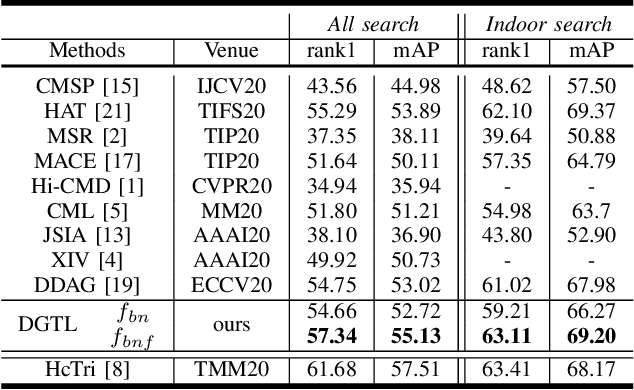
In this letter, we propose a conceptually simple and effective dual-granularity triplet loss for visible-thermal person re-identification (VT-ReID). In general, ReID models are always trained with the sample-based triplet loss and identification loss from the fine granularity level. It is possible when a center-based loss is introduced to encourage the intra-class compactness and inter-class discrimination from the coarse granularity level. Our proposed dual-granularity triplet loss well organizes the sample-based triplet loss and center-based triplet loss in a hierarchical fine to coarse granularity manner, just with some simple configurations of typical operations, such as pooling and batch normalization. Experiments on RegDB and SYSU-MM01 datasets show that with only the global features our dual-granularity triplet loss can improve the VT-ReID performance by a significant margin. It can be a strong VT-ReID baseline to boost future research with high quality.
MoNet3D: Towards Accurate Monocular 3D Object Localization in Real Time
Jun 29, 2020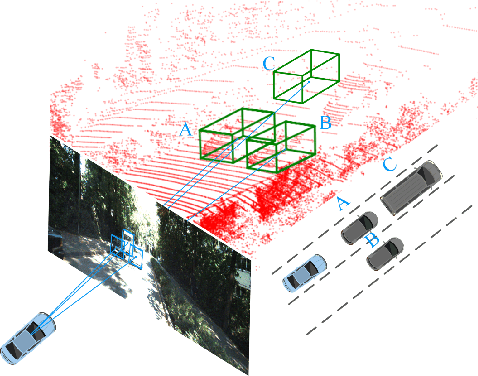
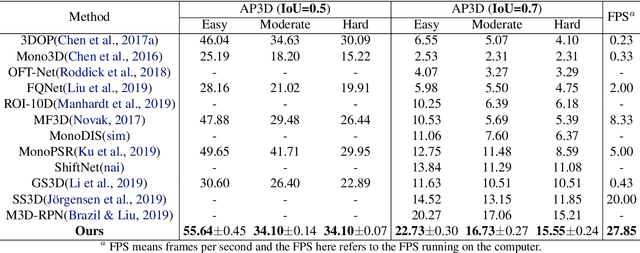
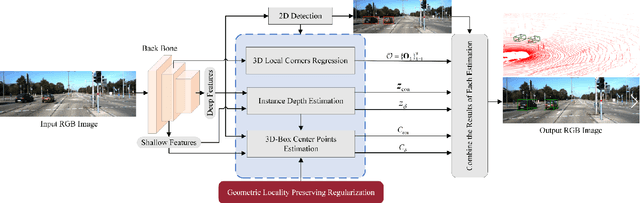
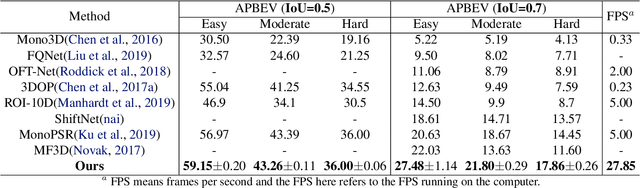
Monocular multi-object detection and localization in 3D space has been proven to be a challenging task. The MoNet3D algorithm is a novel and effective framework that can predict the 3D position of each object in a monocular image and draw a 3D bounding box for each object. The MoNet3D method incorporates prior knowledge of the spatial geometric correlation of neighbouring objects into the deep neural network training process to improve the accuracy of 3D object localization. Experiments on the KITTI dataset show that the accuracy for predicting the depth and horizontal coordinates of objects in 3D space can reach 96.25\% and 94.74\%, respectively. Moreover, the method can realize the real-time image processing at 27.85 FPS, showing promising potential for embedded advanced driving-assistance system applications. Our code is publicly available at https://github.com/CQUlearningsystemgroup/YicongPeng.
Neural Network Activation Quantization with Bitwise Information Bottlenecks
Jun 09, 2020
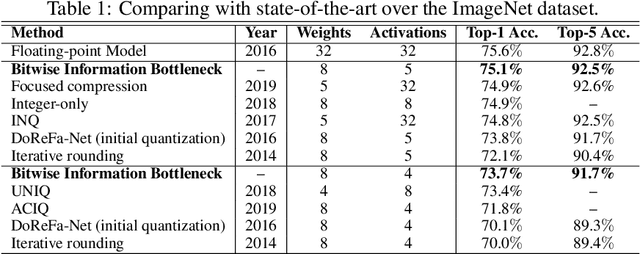


Recent researches on information bottleneck shed new light on the continuous attempts to open the black box of neural signal encoding. Inspired by the problem of lossy signal compression for wireless communication, this paper presents a Bitwise Information Bottleneck approach for quantizing and encoding neural network activations. Based on the rate-distortion theory, the Bitwise Information Bottleneck attempts to determine the most significant bits in activation representation by assigning and approximating the sparse coefficient associated with each bit. Given the constraint of a limited average code rate, the information bottleneck minimizes the rate-distortion for optimal activation quantization in a flexible layer-by-layer manner. Experiments over ImageNet and other datasets show that, by minimizing the quantization rate-distortion of each layer, the neural network with information bottlenecks achieves the state-of-the-art accuracy with low-precision activation. Meanwhile, by reducing the code rate, the proposed method can improve the memory and computational efficiency by over six times compared with the deep neural network with standard single-precision representation. Codes will be available on GitHub when the paper is accepted \url{https://github.com/BitBottleneck/PublicCode}.
Probability Weighted Compact Feature for Domain Adaptive Retrieval
Mar 06, 2020


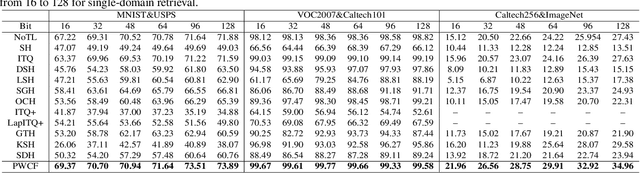
Domain adaptive image retrieval includes single-domain retrieval and cross-domain retrieval. Most of the existing image retrieval methods only focus on single-domain retrieval, which assumes that the distributions of retrieval databases and queries are similar. However, in practical application, the discrepancies between retrieval databases often taken in ideal illumination/pose/background/camera conditions and queries usually obtained in uncontrolled conditions are very large. In this paper, considering the practical application, we focus on challenging cross-domain retrieval. To address the problem, we propose an effective method named Probability Weighted Compact Feature Learning (PWCF), which provides inter-domain correlation guidance to promote cross-domain retrieval accuracy and learns a series of compact binary codes to improve the retrieval speed. First, we derive our loss function through the Maximum A Posteriori Estimation (MAP): Bayesian Perspective (BP) induced focal-triplet loss, BP induced quantization loss and BP induced classification loss. Second, we propose a common manifold structure between domains to explore the potential correlation across domains. Considering the original feature representation is biased due to the inter-domain discrepancy, the manifold structure is difficult to be constructed. Therefore, we propose a new feature named Histogram Feature of Neighbors (HFON) from the sample statistics perspective. Extensive experiments on various benchmark databases validate that our method outperforms many state-of-the-art image retrieval methods for domain adaptive image retrieval. The source code is available at https://github.com/fuxianghuang1/PWCF
Two-Phase Object-Based Deep Learning for Multi-temporal SAR Image Change Detection
Jan 17, 2020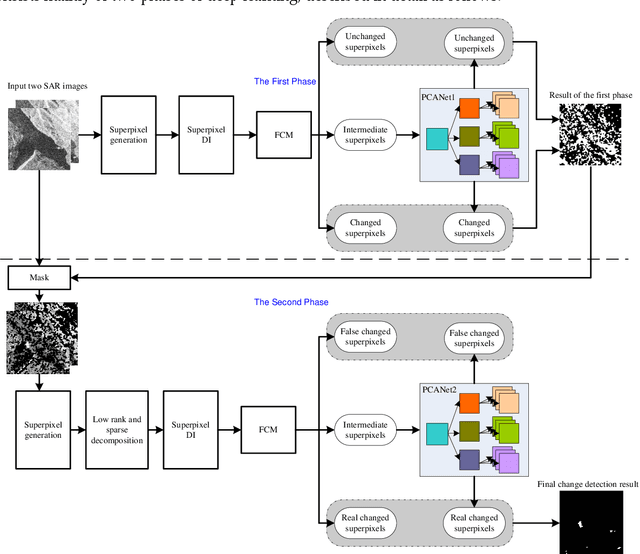
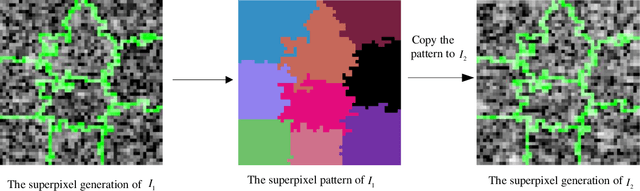
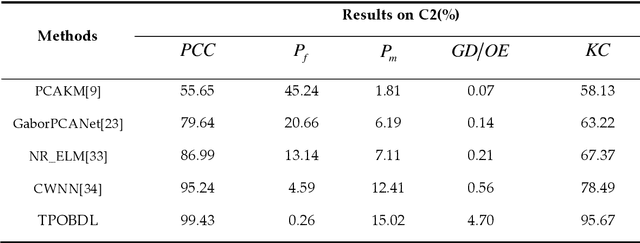
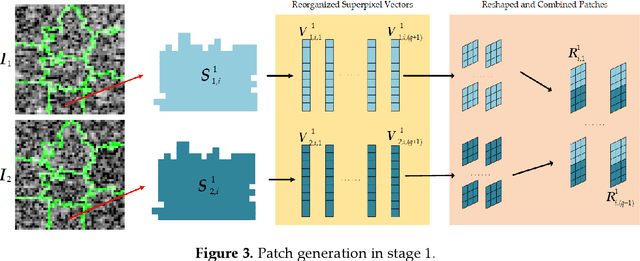
Change detection is one of the fundamental applications of synthetic aperture radar (SAR) images. However, speckle noise presented in SAR images has a much negative effect on change detection. In this research, a novel two-phase object-based deep learning approach is proposed for multi-temporal SAR image change detection. Compared with traditional methods, the proposed approach brings two main innovations. One is to classify all pixels into three categories rather than two categories: unchanged pixels, changed pixels caused by strong speckle (false changes), and changed pixels formed by real terrain variation (real changes). The other is to group neighboring pixels into segmented into superpixel objects (from pixels) such as to exploit local spatial context. Two phases are designed in the methodology: 1) Generate objects based on the simple linear iterative clustering algorithm, and discriminate these objects into changed and unchanged classes using fuzzy c-means (FCM) clustering and a deep PCANet. The prediction of this Phase is the set of changed and unchanged superpixels. 2) Deep learning on the pixel sets over the changed superpixels only, obtained in the first phase, to discriminate real changes from false changes. SLIC is employed again to achieve new superpixels in the second phase. Low rank and sparse decomposition are applied to these new superpixels to suppress speckle noise significantly. A further clustering step is applied to these new superpixels via FCM. A new PCANet is then trained to classify two kinds of changed superpixels to achieve the final change maps. Numerical experiments demonstrate that, compared with benchmark methods, the proposed approach can distinguish real changes from false changes effectively with significantly reduced false alarm rates, and achieve up to 99.71% change detection accuracy using multi-temporal SAR imagery.