 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Non-Causal Factors are Out via Dataset Splitting for Domain Generalization Object Detection
Jan 27, 2026Open world object detection faces a significant challenge in domain-invariant representation, i.e., implicit non-causal factors. Most domain generalization (DG) methods based on domain adversarial learning (DAL) pay much attention to learn domain-invariant information, but often overlook the potential non-causal factors. We unveil two critical causes: 1) The domain discriminator-based DAL method is subject to the extremely sparse domain label, i.e., assigning only one domain label to each dataset, thus can only associate explicit non-causal factor, which is incredibly limited. 2) The non-causal factors, induced by unidentified data bias, are excessively implicit and cannot be solely discerned by conventional DAL paradigm. Based on these key findings, inspired by the Granular-Ball perspective, we propose an improved DAL method, i.e., GB-DAL. The proposed GB-DAL utilizes Prototype-based Granular Ball Splitting (PGBS) module to generate more dense domains from limited datasets, akin to more fine-grained granular balls, indicating more potential non-causal factors. Inspired by adversarial perturbations akin to non-causal factors, we propose a Simulated Non-causal Factors (SNF) module as a means of data augmentation to reduce the implicitness of non-causal factors, and facilitate the training of GB-DAL. Comparative experiments on numerous benchmarks demonstrate that our method achieves better generalization performance in novel circumstances.
Proxy Robustness in Vision Language Models is Effortlessly Transferable
Jan 19, 2026As a pivotal technique for improving the defense of deep models, adversarial robustness transfer via distillation has demonstrated remarkable success in conventional image classification tasks. However, this paradigm encounters critical challenges when applied to vision-language models (VLM) (e.g., CLIP): constructing adversarially robust teacher for large-scale multi-modal models demands prohibitively high computational resources. We bridge this gap by revealing an interesting phenomenon: vanilla CLIP (without adversarial training) exhibits intrinsic defensive capabilities against adversarial examples generated by another CLIP with different architectures. We formally define this as proxy adversarial robustness, and naturally propose a Heterogeneous Proxy Transfer (HPT) framework that establishes cross-architectural robustness distillation channels between CLIP variants, effortlessly enabling the VLM robustness transfer from proxy to target models. Yet, such proxy transfer paradigm easily induces severe overfitting, leading to a sharp degradation in zero-shot natural generalization. To resolve that, we design Generalization-Pivot Decoupling (GPD) by leveraging the difference in learning rate scheduling. This decouples the proxy transfer process into a generalization-anchored warm-up that maintains generalization and a generalization-pulled HPT that promotes adversarial robustness, to achieve an equilibrium between natural generalization and adversarial robustness. Extensive experiments on 15 zero-shot datasets demonstrate the effectiveness of our HPT-GPD method. The code is available at the website of github.com/fxw13/HPT-GPD.
Unsupervised Robust Domain Adaptation: Paradigm, Theory and Algorithm
Nov 14, 2025Unsupervised domain adaptation (UDA) aims to transfer knowledge from a label-rich source domain to an unlabeled target domain by addressing domain shifts. Most UDA approaches emphasize transfer ability, but often overlook robustness against adversarial attacks. Although vanilla adversarial training (VAT) improves the robustness of deep neural networks, it has little effect on UDA. This paper focuses on answering three key questions: 1) Why does VAT, known for its defensive effectiveness, fail in the UDA paradigm? 2) What is the generalization bound theory under attacks and how does it evolve from classical UDA theory? 3) How can we implement a robustification training procedure without complex modifications? Specifically, we explore and reveal the inherent entanglement challenge in general UDA+VAT paradigm, and propose an unsupervised robust domain adaptation (URDA) paradigm. We further derive the generalization bound theory of the URDA paradigm so that it can resist adversarial noise and domain shift. To the best of our knowledge, this is the first time to establish the URDA paradigm and theory. We further introduce a simple, novel yet effective URDA algorithm called Disentangled Adversarial Robustness Training (DART), a two-step training procedure that ensures both transferability and robustness. DART first pre-trains an arbitrary UDA model, and then applies an instantaneous robustification post-training step via disentangled distillation.Experiments on four benchmark datasets with/without attacks show that DART effectively enhances robustness while maintaining domain adaptability, and validate the URDA paradigm and theory.
A Survey of Multimodal Composite Editing and Retrieval
Sep 11, 2024In the real world, where information is abundant and diverse across different modalities, understanding and utilizing various data types to improve retrieval systems is a key focus of research. Multimodal composite retrieval integrates diverse modalities such as text, image and audio, etc. to provide more accurate, personalized, and contextually relevant results. To facilitate a deeper understanding of this promising direction, this survey explores multimodal composite editing and retrieval in depth, covering image-text composite editing, image-text composite retrieval, and other multimodal composite retrieval. In this survey, we systematically organize the application scenarios, methods, benchmarks, experiments, and future directions. Multimodal learning is a hot topic in large model era, and have also witnessed some surveys in multimodal learning and vision-language models with transformers published in the PAMI journal. To the best of our knowledge, this survey is the first comprehensive review of the literature on multimodal composite retrieval, which is a timely complement of multimodal fusion to existing reviews. To help readers' quickly track this field, we build the project page for this survey, which can be found at https://github.com/fuxianghuang1/Multimodal-Composite-Editing-and-Retrieval.
Gradient Harmonization in Unsupervised Domain Adaptation
Aug 01, 2024Unsupervised domain adaptation (UDA) intends to transfer knowledge from a labeled source domain to an unlabeled target domain. Many current methods focus on learning feature representations that are both discriminative for classification and invariant across domains by simultaneously optimizing domain alignment and classification tasks. However, these methods often overlook a crucial challenge: the inherent conflict between these two tasks during gradient-based optimization. In this paper, we delve into this issue and introduce two effective solutions known as Gradient Harmonization, including GH and GH++, to mitigate the conflict between domain alignment and classification tasks. GH operates by altering the gradient angle between different tasks from an obtuse angle to an acute angle, thus resolving the conflict and trade-offing the two tasks in a coordinated manner. Yet, this would cause both tasks to deviate from their original optimization directions. We thus further propose an improved version, GH++, which adjusts the gradient angle between tasks from an obtuse angle to a vertical angle. This not only eliminates the conflict but also minimizes deviation from the original gradient directions. Finally, for optimization convenience and efficiency, we evolve the gradient harmonization strategies into a dynamically weighted loss function using an integral operator on the harmonized gradient. Notably, GH/GH++ are orthogonal to UDA and can be seamlessly integrated into most existing UDA models. Theoretical insights and experimental analyses demonstrate that the proposed approaches not only enhance popular UDA baselines but also improve recent state-of-the-art models.
Foundation Model for Advancing Healthcare: Challenges, Opportunities, and Future Directions
Apr 04, 2024



Foundation model, which is pre-trained on broad data and is able to adapt to a wide range of tasks, is advancing healthcare. It promotes the development of healthcare artificial intelligence (AI) models, breaking the contradiction between limited AI models and diverse healthcare practices. Much more widespread healthcare scenarios will benefit from the development of a healthcare foundation model (HFM), improving their advanced intelligent healthcare services. Despite the impending widespread deployment of HFMs, there is currently a lack of clear understanding about how they work in the healthcare field, their current challenges, and where they are headed in the future. To answer these questions, a comprehensive and deep survey of the challenges, opportunities, and future directions of HFMs is presented in this survey. It first conducted a comprehensive overview of the HFM including the methods, data, and applications for a quick grasp of the current progress. Then, it made an in-depth exploration of the challenges present in data, algorithms, and computing infrastructures for constructing and widespread application of foundation models in healthcare. This survey also identifies emerging and promising directions in this field for future development. We believe that this survey will enhance the community's comprehension of the current progress of HFM and serve as a valuable source of guidance for future development in this field. The latest HFM papers and related resources are maintained on our website: https://github.com/YutingHe-list/Awesome-Foundation-Models-for-Advancing-Healthcare.
An Open-World, Diverse, Cross-Spatial-Temporal Benchmark for Dynamic Wild Person Re-Identification
Mar 22, 2024Person re-identification (ReID) has made great strides thanks to the data-driven deep learning techniques. However, the existing benchmark datasets lack diversity, and models trained on these data cannot generalize well to dynamic wild scenarios. To meet the goal of improving the explicit generalization of ReID models, we develop a new Open-World, Diverse, Cross-Spatial-Temporal dataset named OWD with several distinct features. 1) Diverse collection scenes: multiple independent open-world and highly dynamic collecting scenes, including streets, intersections, shopping malls, etc. 2) Diverse lighting variations: long time spans from daytime to nighttime with abundant illumination changes. 3) Diverse person status: multiple camera networks in all seasons with normal/adverse weather conditions and diverse pedestrian appearances (e.g., clothes, personal belongings, poses, etc.). 4) Protected privacy: invisible faces for privacy critical applications. To improve the implicit generalization of ReID, we further propose a Latent Domain Expansion (LDE) method to develop the potential of source data, which decouples discriminative identity-relevant and trustworthy domain-relevant features and implicitly enforces domain-randomized identity feature space expansion with richer domain diversity to facilitate domain invariant representations. Our comprehensive evaluations with most benchmark datasets in the community are crucial for progress, although this work is far from the grand goal toward open-world and dynamic wild applications.
Dynamic Weighted Combiner for Mixed-Modal Image Retrieval
Dec 11, 2023Mixed-Modal Image Retrieval (MMIR) as a flexible search paradigm has attracted wide attention. However, previous approaches always achieve limited performance, due to two critical factors are seriously overlooked. 1) The contribution of image and text modalities is different, but incorrectly treated equally. 2) There exist inherent labeling noises in describing users' intentions with text in web datasets from diverse real-world scenarios, giving rise to overfitting. We propose a Dynamic Weighted Combiner (DWC) to tackle the above challenges, which includes three merits. First, we propose an Editable Modality De-equalizer (EMD) by taking into account the contribution disparity between modalities, containing two modality feature editors and an adaptive weighted combiner. Second, to alleviate labeling noises and data bias, we propose a dynamic soft-similarity label generator (SSG) to implicitly improve noisy supervision. Finally, to bridge modality gaps and facilitate similarity learning, we propose a CLIP-based mutual enhancement module alternately trained by a mixed-modality contrastive loss. Extensive experiments verify that our proposed model significantly outperforms state-of-the-art methods on real-world datasets. The source code is available at \url{https://github.com/fuxianghuang1/DWC}.
Language Guided Local Infiltration for Interactive Image Retrieval
Apr 16, 2023Interactive Image Retrieval (IIR) aims to retrieve images that are generally similar to the reference image but under the requested text modification. The existing methods usually concatenate or sum the features of image and text simply and roughly, which, however, is difficult to precisely change the local semantics of the image that the text intends to modify. To solve this problem, we propose a Language Guided Local Infiltration (LGLI) system, which fully utilizes the text information and penetrates text features into image features as much as possible. Specifically, we first propose a Language Prompt Visual Localization (LPVL) module to generate a localization mask which explicitly locates the region (semantics) intended to be modified. Then we introduce a Text Infiltration with Local Awareness (TILA) module, which is deployed in the network to precisely modify the reference image and generate image-text infiltrated representation. Extensive experiments on various benchmark databases validate that our method outperforms most state-of-the-art IIR approaches.
Probability Weighted Compact Feature for Domain Adaptive Retrieval
Mar 06, 2020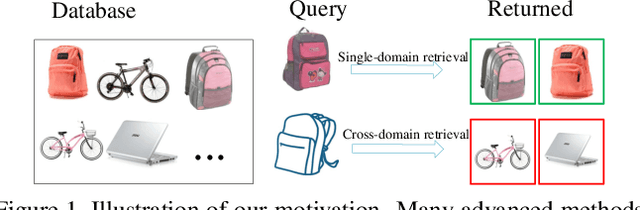


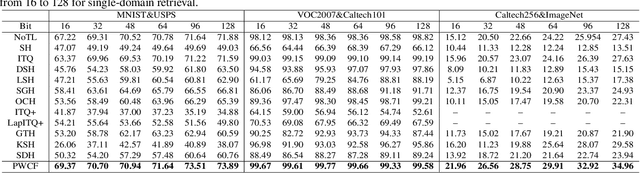
Domain adaptive image retrieval includes single-domain retrieval and cross-domain retrieval. Most of the existing image retrieval methods only focus on single-domain retrieval, which assumes that the distributions of retrieval databases and queries are similar. However, in practical application, the discrepancies between retrieval databases often taken in ideal illumination/pose/background/camera conditions and queries usually obtained in uncontrolled conditions are very large. In this paper, considering the practical application, we focus on challenging cross-domain retrieval. To address the problem, we propose an effective method named Probability Weighted Compact Feature Learning (PWCF), which provides inter-domain correlation guidance to promote cross-domain retrieval accuracy and learns a series of compact binary codes to improve the retrieval speed. First, we derive our loss function through the Maximum A Posteriori Estimation (MAP): Bayesian Perspective (BP) induced focal-triplet loss, BP induced quantization loss and BP induced classification loss. Second, we propose a common manifold structure between domains to explore the potential correlation across domains. Considering the original feature representation is biased due to the inter-domain discrepancy, the manifold structure is difficult to be constructed. Therefore, we propose a new feature named Histogram Feature of Neighbors (HFON) from the sample statistics perspective. Extensive experiments on various benchmark databases validate that our method outperforms many state-of-the-art image retrieval methods for domain adaptive image retrieval. The source code is available at https://github.com/fuxianghuang1/PWCF