 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurning Black Box into White Box: Dataset Distillation Leaks
Mar 01, 2026Dataset distillation compresses a large real dataset into a small synthetic one, enabling models trained on the synthetic data to achieve performance comparable to those trained on the real data. Although synthetic datasets are assumed to be privacy-preserving, we show that existing distillation methods can cause severe privacy leakage because synthetic datasets implicitly encode the weight trajectories of the distilled model, they become over-informative and exploitable by adversaries. To expose this risk, we introduce the Information Revelation Attack (IRA) against state-of-the-art distillation techniques. Experiments show that IRA accurately predicts both the distillation algorithm and model architecture, and can successfully infer membership and recover sensitive samples from the real dataset.
Rethinking Bias in Generative Data Augmentation for Medical AI: a Frequency Recalibration Method
Nov 15, 2025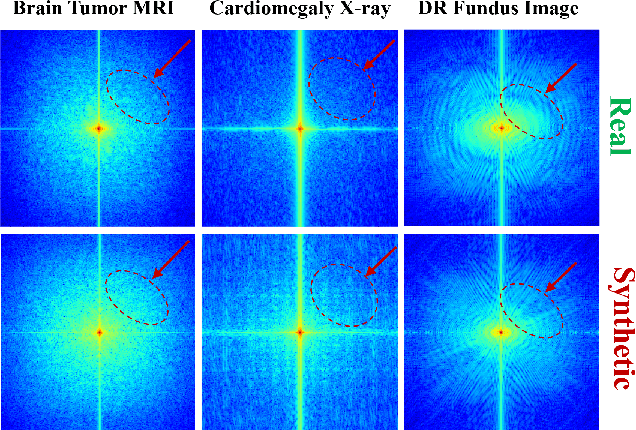

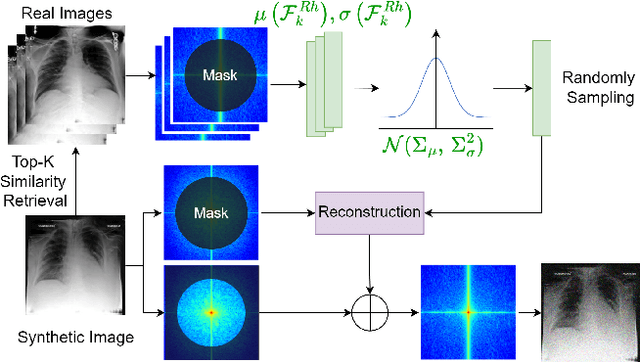
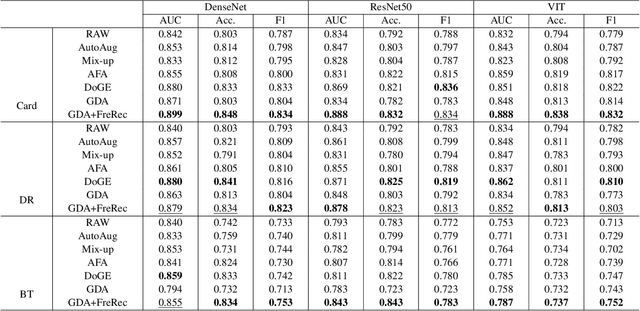
Developing Medical AI relies on large datasets and easily suffers from data scarcity. Generative data augmentation (GDA) using AI generative models offers a solution to synthesize realistic medical images. However, the bias in GDA is often underestimated in medical domains, with concerns about the risk of introducing detrimental features generated by AI and harming downstream tasks. This paper identifies the frequency misalignment between real and synthesized images as one of the key factors underlying unreliable GDA and proposes the Frequency Recalibration (FreRec) method to reduce the frequency distributional discrepancy and thus improve GDA. FreRec involves (1) Statistical High-frequency Replacement (SHR) to roughly align high-frequency components and (2) Reconstructive High-frequency Mapping (RHM) to enhance image quality and reconstruct high-frequency details. Extensive experiments were conducted in various medical datasets, including brain MRIs, chest X-rays, and fundus images. The results show that FreRec significantly improves downstream medical image classification performance compared to uncalibrated AI-synthesized samples. FreRec is a standalone post-processing step that is compatible with any generative model and can integrate seamlessly with common medical GDA pipelines.
Causal Fingerprints of AI Generative Models
Sep 18, 2025AI generative models leave implicit traces in their generated images, which are commonly referred to as model fingerprints and are exploited for source attribution. Prior methods rely on model-specific cues or synthesis artifacts, yielding limited fingerprints that may generalize poorly across different generative models. We argue that a complete model fingerprint should reflect the causality between image provenance and model traces, a direction largely unexplored. To this end, we conceptualize the \emph{causal fingerprint} of generative models, and propose a causality-decoupling framework that disentangles it from image-specific content and style in a semantic-invariant latent space derived from pre-trained diffusion reconstruction residual. We further enhance fingerprint granularity with diverse feature representations. We validate causality by assessing attribution performance across representative GANs and diffusion models and by achieving source anonymization using counterfactual examples generated from causal fingerprints. Experiments show our approach outperforms existing methods in model attribution, indicating strong potential for forgery detection, model copyright tracing, and identity protection.
A Self-attention Residual Convolutional Neural Network for Health Condition Classification of Cow Teat Images
Sep 30, 2024



Milk is a highly important consumer for Americans and the health of the cows' teats directly affects the quality of the milk. Traditionally, veterinarians manually assessed teat health by visually inspecting teat-end hyperkeratosis during the milking process which is limited in time, usually only tens of seconds, and weakens the accuracy of the health assessment of cows' teats. Convolutional neural networks (CNNs) have been used for cows' teat-end health assessment. However, there are challenges in using CNNs for cows' teat-end health assessment, such as complex environments, changing positions and postures of cows' teats, and difficulty in identifying cows' teats from images. To address these challenges, this paper proposes a cows' teats self-attention residual convolutional neural network (CTSAR-CNN) model that combines residual connectivity and self-attention mechanisms to assist commercial farms in the health assessment of cows' teats by classifying the magnitude of teat-end hyperkeratosis using digital images. The results showed that upon integrating residual connectivity and self-attention mechanisms, the accuracy of CTSAR-CNN has been improved. This research illustrates that CTSAR-CNN can be more adaptable and speedy to assist veterinarians in assessing the health of cows' teats and ultimately benefit the dairy industry.
Supervised Learning Model for Key Frame Identification from Cow Teat Videos
Sep 26, 2024


This paper proposes a method for improving the accuracy of mastitis risk assessment in cows using neural networks and video analysis. Mastitis, an infection of the udder tissue, is a critical health problem for cows and can be detected by examining the cow's teat. Traditionally, veterinarians assess the health of a cow's teat during the milking process, but this process is limited in time and can weaken the accuracy of the assessment. In commercial farms, cows are recorded by cameras when they are milked in the milking parlor. This paper uses a neural network to identify key frames in the recorded video where the cow's udder appears intact. These key frames allow veterinarians to have more flexible time to perform health assessments on the teat, increasing their efficiency and accuracy. However, there are challenges in using cow teat video for mastitis risk assessment, such as complex environments, changing cow positions and postures, and difficulty in identifying the udder from the video. To address these challenges, a fusion distance and an ensemble model are proposed to improve the performance (F-score) of identifying key frames from cow teat videos. The results show that these two approaches improve performance compared to using a single distance measure or model.
Federated Learning with Blockchain-Enhanced Machine Unlearning: A Trustworthy Approach
May 27, 2024



With the growing need to comply with privacy regulations and respond to user data deletion requests, integrating machine unlearning into IoT-based federated learning has become imperative. Traditional unlearning methods, however, often lack verifiable mechanisms, leading to challenges in establishing trust. This paper delves into the innovative integration of blockchain technology with federated learning to surmount these obstacles. Blockchain fortifies the unlearning process through its inherent qualities of immutability, transparency, and robust security. It facilitates verifiable certification, harmonizes security with privacy, and sustains system efficiency. We introduce a framework that melds blockchain with federated learning, thereby ensuring an immutable record of unlearning requests and actions. This strategy not only bolsters the trustworthiness and integrity of the federated learning model but also adeptly addresses efficiency and security challenges typical in IoT environments. Our key contributions encompass a certification mechanism for the unlearning process, the enhancement of data security and privacy, and the optimization of data management to ensure system responsiveness in IoT scenarios.
Detecting Anti-Semitic Hate Speech using Transformer-based Large Language Models
May 06, 2024

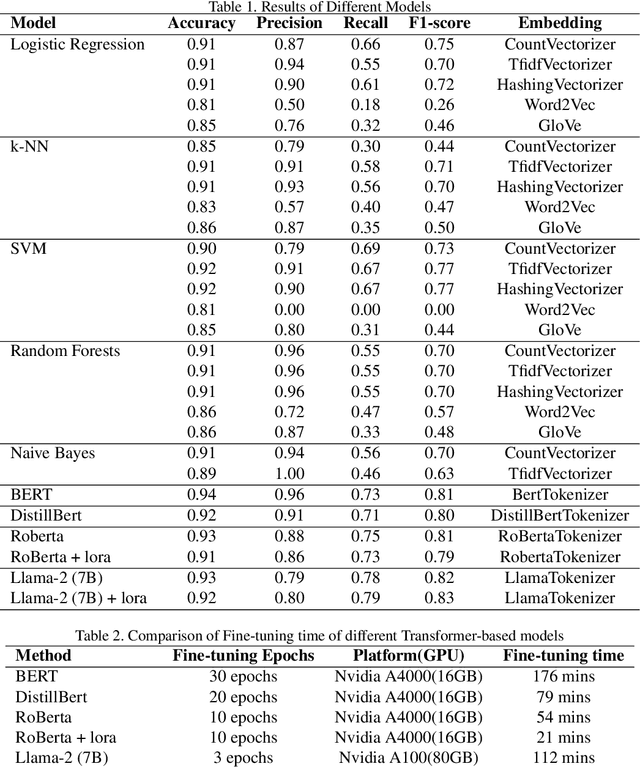
Academic researchers and social media entities grappling with the identification of hate speech face significant challenges, primarily due to the vast scale of data and the dynamic nature of hate speech. Given the ethical and practical limitations of large predictive models like ChatGPT in directly addressing such sensitive issues, our research has explored alternative advanced transformer-based and generative AI technologies since 2019. Specifically, we developed a new data labeling technique and established a proof of concept targeting anti-Semitic hate speech, utilizing a variety of transformer models such as BERT (arXiv:1810.04805), DistillBERT (arXiv:1910.01108), RoBERTa (arXiv:1907.11692), and LLaMA-2 (arXiv:2307.09288), complemented by the LoRA fine-tuning approach (arXiv:2106.09685). This paper delineates and evaluates the comparative efficacy of these cutting-edge methods in tackling the intricacies of hate speech detection, highlighting the need for responsible and carefully managed AI applications within sensitive contexts.
Foundation Model for Advancing Healthcare: Challenges, Opportunities, and Future Directions
Apr 04, 2024



Foundation model, which is pre-trained on broad data and is able to adapt to a wide range of tasks, is advancing healthcare. It promotes the development of healthcare artificial intelligence (AI) models, breaking the contradiction between limited AI models and diverse healthcare practices. Much more widespread healthcare scenarios will benefit from the development of a healthcare foundation model (HFM), improving their advanced intelligent healthcare services. Despite the impending widespread deployment of HFMs, there is currently a lack of clear understanding about how they work in the healthcare field, their current challenges, and where they are headed in the future. To answer these questions, a comprehensive and deep survey of the challenges, opportunities, and future directions of HFMs is presented in this survey. It first conducted a comprehensive overview of the HFM including the methods, data, and applications for a quick grasp of the current progress. Then, it made an in-depth exploration of the challenges present in data, algorithms, and computing infrastructures for constructing and widespread application of foundation models in healthcare. This survey also identifies emerging and promising directions in this field for future development. We believe that this survey will enhance the community's comprehension of the current progress of HFM and serve as a valuable source of guidance for future development in this field. The latest HFM papers and related resources are maintained on our website: https://github.com/YutingHe-list/Awesome-Foundation-Models-for-Advancing-Healthcare.
Medical Image Debiasing by Learning Adaptive Agreement from a Biased Council
Jan 22, 2024

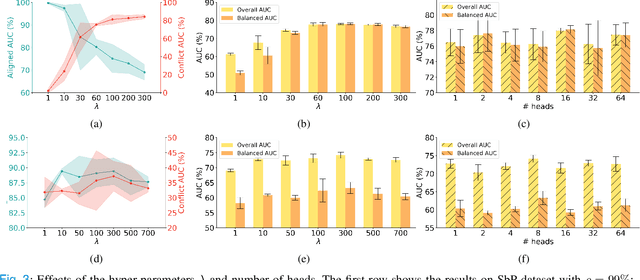
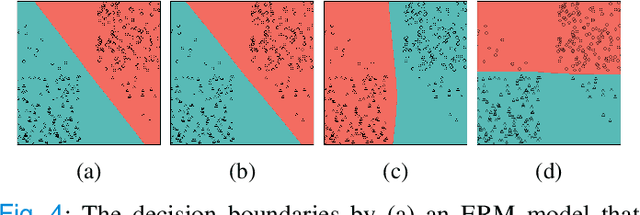
Deep learning could be prone to learning shortcuts raised by dataset bias and result in inaccurate, unreliable, and unfair models, which impedes its adoption in real-world clinical applications. Despite its significance, there is a dearth of research in the medical image classification domain to address dataset bias. Furthermore, the bias labels are often agnostic, as identifying biases can be laborious and depend on post-hoc interpretation. This paper proposes learning Adaptive Agreement from a Biased Council (Ada-ABC), a debiasing framework that does not rely on explicit bias labels to tackle dataset bias in medical images. Ada-ABC develops a biased council consisting of multiple classifiers optimized with generalized cross entropy loss to learn the dataset bias. A debiasing model is then simultaneously trained under the guidance of the biased council. Specifically, the debiasing model is required to learn adaptive agreement with the biased council by agreeing on the correctly predicted samples and disagreeing on the wrongly predicted samples by the biased council. In this way, the debiasing model could learn the target attribute on the samples without spurious correlations while also avoiding ignoring the rich information in samples with spurious correlations. We theoretically demonstrated that the debiasing model could learn the target features when the biased model successfully captures dataset bias. Moreover, to our best knowledge, we constructed the first medical debiasing benchmark from four datasets containing seven different bias scenarios. Our extensive experiments practically showed that our proposed Ada-ABC outperformed competitive approaches, verifying its effectiveness in mitigating dataset bias for medical image classification. The codes and organized benchmark datasets will be made publicly available.
MHSnet: Multi-head and Spatial Attention Network with False-Positive Reduction for Pulmonary Nodules Detection
Feb 16, 2022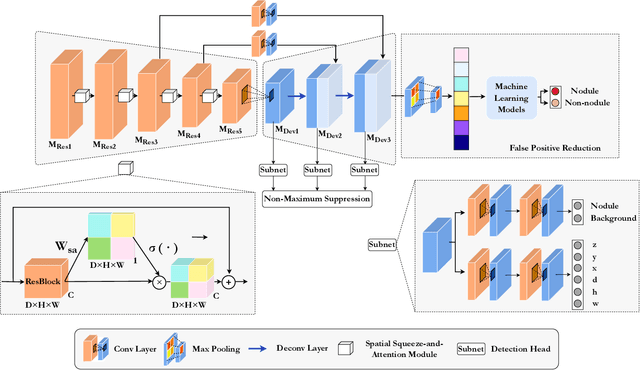
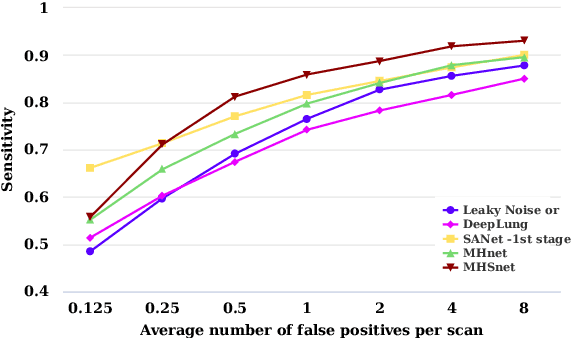
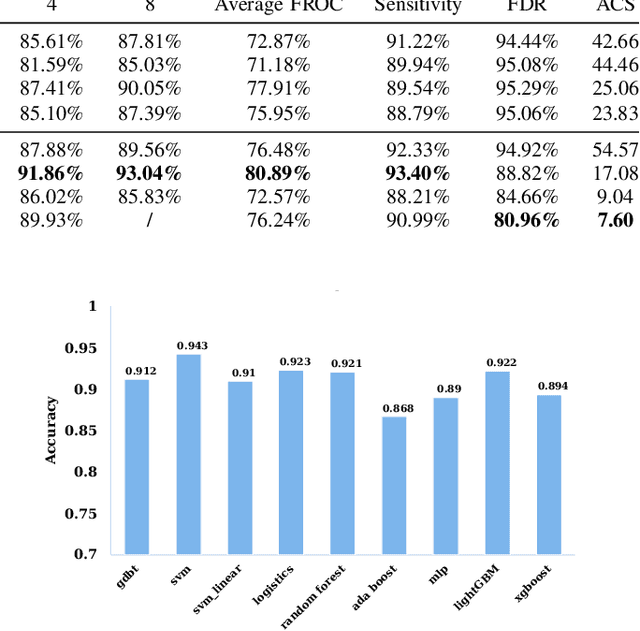
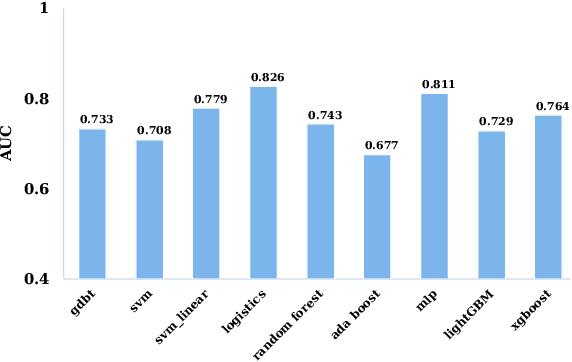
The mortality of lung cancer has ranked high among cancers for many years. Early detection of lung cancer is critical for disease prevention, cure, and mortality rate reduction. However, existing detection methods on pulmonary nodules introduce an excessive number of false positive proposals in order to achieve high sensitivity, which is not practical in clinical situations. In this paper, we propose the multi-head detection and spatial squeeze-and-attention network, MHSnet, to detect pulmonary nodules, in order to aid doctors in the early diagnosis of lung cancers. Specifically, we first introduce multi-head detectors and skip connections to customize for the variety of nodules in sizes, shapes and types and capture multi-scale features. Then, we implement a spatial attention module to enable the network to focus on different regions differently inspired by how experienced clinicians screen CT images, which results in fewer false positive proposals. Lastly, we present a lightweight but effective false positive reduction module with the Linear Regression model to cut down the number of false positive proposals, without any constraints on the front network. Extensive experimental results compared with the state-of-the-art models have shown the superiority of the MHSnet in terms of the average FROC, sensitivity and especially false discovery rate (2.98% and 2.18% improvement in terms of average FROC and sensitivity, 5.62% and 28.33% decrease in terms of false discovery rate and average candidates per scan). The false positive reduction module significantly decreases the average number of candidates generated per scan by 68.11% and the false discovery rate by 13.48%, which is promising to reduce distracted proposals for the downstream tasks based on the detection results.