 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoNet3D: Towards Accurate Monocular 3D Object Localization in Real Time
Jun 29, 2020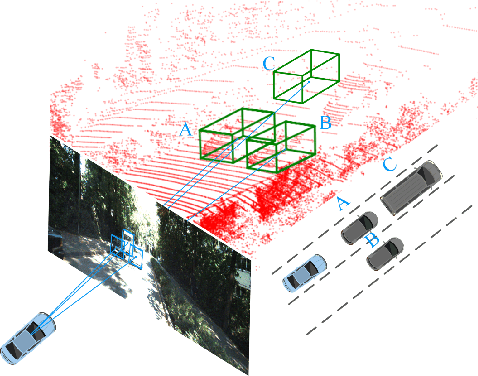
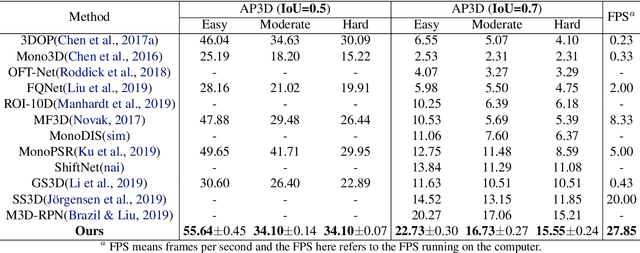
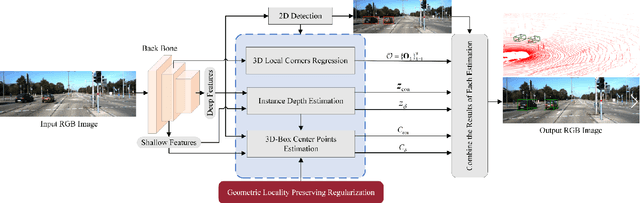
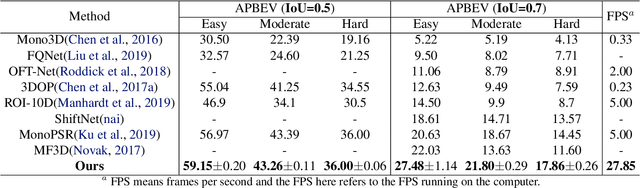
Monocular multi-object detection and localization in 3D space has been proven to be a challenging task. The MoNet3D algorithm is a novel and effective framework that can predict the 3D position of each object in a monocular image and draw a 3D bounding box for each object. The MoNet3D method incorporates prior knowledge of the spatial geometric correlation of neighbouring objects into the deep neural network training process to improve the accuracy of 3D object localization. Experiments on the KITTI dataset show that the accuracy for predicting the depth and horizontal coordinates of objects in 3D space can reach 96.25\% and 94.74\%, respectively. Moreover, the method can realize the real-time image processing at 27.85 FPS, showing promising potential for embedded advanced driving-assistance system applications. Our code is publicly available at https://github.com/CQUlearningsystemgroup/YicongPeng.