 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIEVE: Towards Verifiable Certification for Code-datasets
Oct 02, 2025


Code agents and empirical software engineering rely on public code datasets, yet these datasets lack verifiable quality guarantees. Static 'dataset cards' inform, but they are neither auditable nor do they offer statistical guarantees, making it difficult to attest to dataset quality. Teams build isolated, ad-hoc cleaning pipelines. This fragments effort and raises cost. We present SIEVE, a community-driven framework. It turns per-property checks into Confidence Cards-machine-readable, verifiable certificates with anytime-valid statistical bounds. We outline a research plan to bring SIEVE to maturity, replacing narrative cards with anytime-verifiable certification. This shift is expected to lower quality-assurance costs and increase trust in code-datasets.
Investigating White-Box Attacks for On-Device Models
Feb 26, 2024



Numerous mobile apps have leveraged deep learning capabilities. However, on-device models are vulnerable to attacks as they can be easily extracted from their corresponding mobile apps. Existing on-device attacking approaches only generate black-box attacks, which are far less effective and efficient than white-box strategies. This is because mobile deep learning frameworks like TFLite do not support gradient computing, which is necessary for white-box attacking algorithms. Thus, we argue that existing findings may underestimate the harmfulness of on-device attacks. To this end, we conduct a study to answer this research question: Can on-device models be directly attacked via white-box strategies? We first systematically analyze the difficulties of transforming the on-device model to its debuggable version, and propose a Reverse Engineering framework for On-device Models (REOM), which automatically reverses the compiled on-device TFLite model to the debuggable model. Specifically, REOM first transforms compiled on-device models into Open Neural Network Exchange format, then removes the non-debuggable parts, and converts them to the debuggable DL models format that allows attackers to exploit in a white-box setting. Our experimental results show that our approach is effective in achieving automated transformation among 244 TFLite models. Compared with previous attacks using surrogate models, REOM enables attackers to achieve higher attack success rates with a hundred times smaller attack perturbations. In addition, because the ONNX platform has plenty of tools for model format exchanging, the proposed method based on the ONNX platform can be adapted to other model formats. Our findings emphasize the need for developers to carefully consider their model deployment strategies, and use white-box methods to evaluate the vulnerability of on-device models.
Multisensor fusion-based digital twin in additive manufacturing for in-situ quality monitoring and defect correction
Apr 12, 2023Early detection and correction of defects are critical in additive manufacturing (AM) to avoid build failures. In this paper, we present a multisensor fusion-based digital twin for in-situ quality monitoring and defect correction in a robotic laser direct energy deposition process. Multisensor fusion sources consist of an acoustic sensor, an infrared thermal camera, a coaxial vision camera, and a laser line scanner. The key novelty and contribution of this work are to develop a spatiotemporal data fusion method that synchronizes and registers the multisensor features within the part's 3D volume. The fused dataset can be used to predict location-specific quality using machine learning. On-the-fly identification of regions requiring material addition or removal is feasible. Robot toolpath and auto-tuned process parameters are generated for defecting correction. In contrast to traditional single-sensor-based monitoring, multisensor fusion allows for a more in-depth understanding of underlying process physics, such as pore formation and laser-material interactions. The proposed methods pave the way for self-adaptation AM with higher efficiency, less waste, and cleaner production.
App Review Driven Collaborative Bug Finding
Jan 23, 2023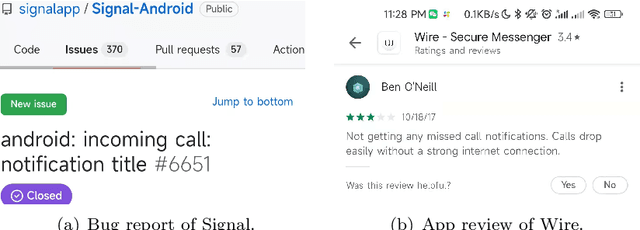
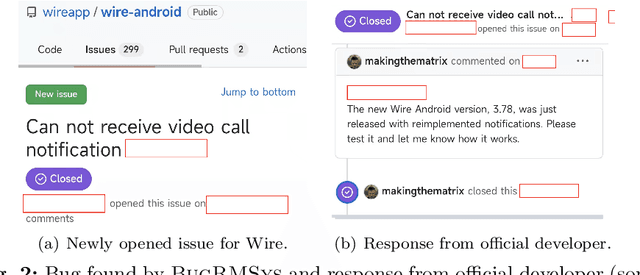


Software development teams generally welcome any effort to expose bugs in their code base. In this work, we build on the hypothesis that mobile apps from the same category (e.g., two web browser apps) may be affected by similar bugs in their evolution process. It is therefore possible to transfer the experience of one historical app to quickly find bugs in its new counterparts. This has been referred to as collaborative bug finding in the literature. Our novelty is that we guide the bug finding process by considering that existing bugs have been hinted within app reviews. Concretely, we design the BugRMSys approach to recommend bug reports for a target app by matching historical bug reports from apps in the same category with user app reviews of the target app. We experimentally show that this approach enables us to quickly expose and report dozens of bugs for targeted apps such as Brave (web browser app). BugRMSys's implementation relies on DistilBERT to produce natural language text embeddings. Our pipeline considers similarities between bug reports and app reviews to identify relevant bugs. We then focus on the app review as well as potential reproduction steps in the historical bug report (from a same-category app) to reproduce the bugs. Overall, after applying BugRMSys to six popular apps, we were able to identify, reproduce and report 20 new bugs: among these, 9 reports have been already triaged, 6 were confirmed, and 4 have been fixed by official development teams, respectively.
Is this Change the Answer to that Problem? Correlating Descriptions of Bug and Code Changes for Evaluating Patch Correctness
Aug 08, 2022
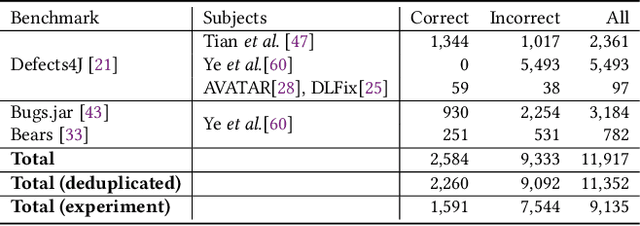
In this work, we propose a novel perspective to the problem of patch correctness assessment: a correct patch implements changes that "answer" to a problem posed by buggy behaviour. Concretely, we turn the patch correctness assessment into a Question Answering problem. To tackle this problem, our intuition is that natural language processing can provide the necessary representations and models for assessing the semantic correlation between a bug (question) and a patch (answer). Specifically, we consider as inputs the bug reports as well as the natural language description of the generated patches. Our approach, Quatrain, first considers state of the art commit message generation models to produce the relevant inputs associated to each generated patch. Then we leverage a neural network architecture to learn the semantic correlation between bug reports and commit messages. Experiments on a large dataset of 9135 patches generated for three bug datasets (Defects4j, Bugs.jar and Bears) show that Quatrain can achieve an AUC of 0.886 on predicting patch correctness, and recalling 93% correct patches while filtering out 62% incorrect patches. Our experimental results further demonstrate the influence of inputs quality on prediction performance. We further perform experiments to highlight that the model indeed learns the relationship between bug reports and code change descriptions for the prediction. Finally, we compare against prior work and discuss the benefits of our approach.
Checking Patch Behaviour against Test Specification
Jul 28, 2021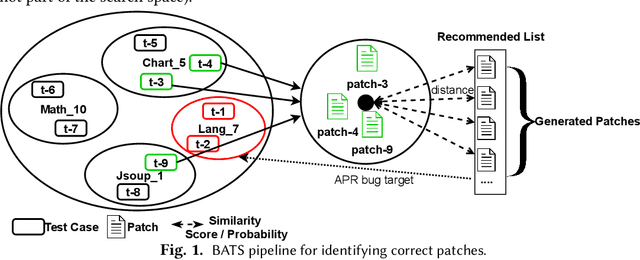
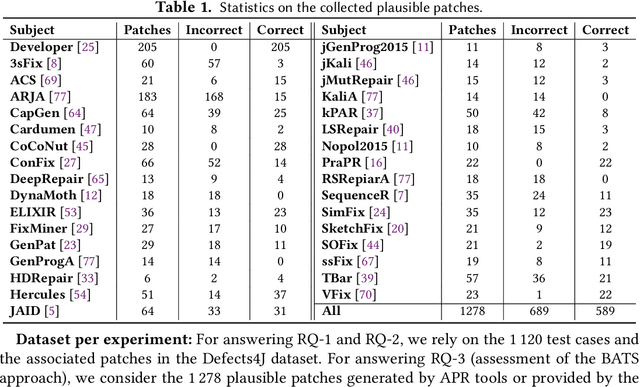
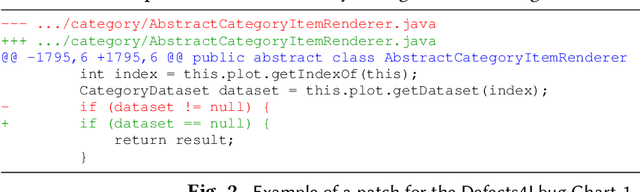

Towards predicting patch correctness in APR, we propose a simple, but novel hypothesis on how the link between the patch behaviour and failing test specifications can be drawn: similar failing test cases should require similar patches. We then propose BATS, an unsupervised learning-based system to predict patch correctness by checking patch Behaviour Against failing Test Specification. BATS exploits deep representation learning models for code and patches: for a given failing test case, the yielded embedding is used to compute similarity metrics in the search for historical similar test cases in order to identify the associated applied patches, which are then used as a proxy for assessing generated patch correctness. Experimentally, we first validate our hypothesis by assessing whether ground-truth developer patches cluster together in the same way that their associated failing test cases are clustered. Then, after collecting a large dataset of 1278 plausible patches (written by developers or generated by some 32 APR tools), we use BATS to predict correctness: BATS achieves an AUC between 0.557 to 0.718 and a recall between 0.562 and 0.854 in identifying correct patches. Compared against previous work, we demonstrate that our approach outperforms state-of-the-art performance in patch correctness prediction, without the need for large labeled patch datasets in contrast with prior machine learning-based approaches. While BATS is constrained by the availability of similar test cases, we show that it can still be complementary to existing approaches: used in conjunction with a recent approach implementing supervised learning, BATS improves the overall recall in detecting correct patches. We finally show that BATS can be complementary to the state-of-the-art PATCH-SIM dynamic approach of identifying the correct patches for APR tools.
Neural Network Activation Quantization with Bitwise Information Bottlenecks
Jun 09, 2020
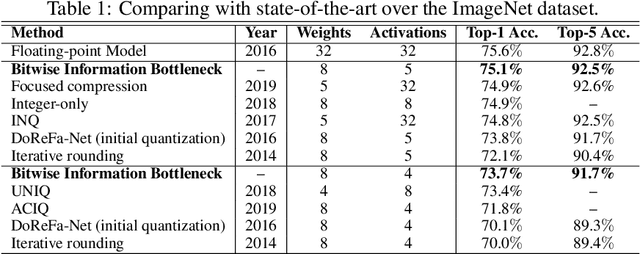


Recent researches on information bottleneck shed new light on the continuous attempts to open the black box of neural signal encoding. Inspired by the problem of lossy signal compression for wireless communication, this paper presents a Bitwise Information Bottleneck approach for quantizing and encoding neural network activations. Based on the rate-distortion theory, the Bitwise Information Bottleneck attempts to determine the most significant bits in activation representation by assigning and approximating the sparse coefficient associated with each bit. Given the constraint of a limited average code rate, the information bottleneck minimizes the rate-distortion for optimal activation quantization in a flexible layer-by-layer manner. Experiments over ImageNet and other datasets show that, by minimizing the quantization rate-distortion of each layer, the neural network with information bottlenecks achieves the state-of-the-art accuracy with low-precision activation. Meanwhile, by reducing the code rate, the proposed method can improve the memory and computational efficiency by over six times compared with the deep neural network with standard single-precision representation. Codes will be available on GitHub when the paper is accepted \url{https://github.com/BitBottleneck/PublicCode}.