 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExecuting as You Generate: Hiding Execution Latency in LLM Code Generation
Apr 01, 2026Current LLM-based coding agents follow a serial execution paradigm: the model first generates the complete code, then invokes an interpreter to execute it. This sequential workflow leaves the executor idle during generation and the generator idle during execution, resulting in unnecessary end-to-end latency. We observe that, unlike human developers, LLMs produce code tokens sequentially without revision, making it possible to execute code as it is being generated. We formalize this parallel execution paradigm, modeling it as a three-stage pipeline of generation, detection, and execution, and derive closed-form latency bounds that characterize its speedup potential and operating regimes. We then present Eager, a concrete implementation featuring AST-based chunking, dynamic batching with gated execution, and early error interruption. We evaluate Eager across four benchmarks, seven LLMs, and three execution environments. Results show that Eager reduces the non-overlapped execution latency by up to 99.9% and the end-to-end latency by up to 55% across seven LLMs and four benchmarks.
Privacy Protection Against Personalized Text-to-Image Synthesis via Cross-image Consistency Constraints
Apr 17, 2025The rapid advancement of diffusion models and personalization techniques has made it possible to recreate individual portraits from just a few publicly available images. While such capabilities empower various creative applications, they also introduce serious privacy concerns, as adversaries can exploit them to generate highly realistic impersonations. To counter these threats, anti-personalization methods have been proposed, which add adversarial perturbations to published images to disrupt the training of personalization models. However, existing approaches largely overlook the intrinsic multi-image nature of personalization and instead adopt a naive strategy of applying perturbations independently, as commonly done in single-image settings. This neglects the opportunity to leverage inter-image relationships for stronger privacy protection. Therefore, we advocate for a group-level perspective on privacy protection against personalization. Specifically, we introduce Cross-image Anti-Personalization (CAP), a novel framework that enhances resistance to personalization by enforcing style consistency across perturbed images. Furthermore, we develop a dynamic ratio adjustment strategy that adaptively balances the impact of the consistency loss throughout the attack iterations. Extensive experiments on the classical CelebHQ and VGGFace2 benchmarks show that CAP substantially improves existing methods.
PathSeeker: Exploring LLM Security Vulnerabilities with a Reinforcement Learning-Based Jailbreak Approach
Sep 21, 2024



In recent years, Large Language Models (LLMs) have gained widespread use, accompanied by increasing concerns over their security. Traditional jailbreak attacks rely on internal model details or have limitations when exploring the unsafe behavior of the victim model, limiting their generalizability. In this paper, we introduce PathSeeker, a novel black-box jailbreak method inspired by the concept of escaping a security maze. This work is inspired by the game of rats escaping a maze. We think that each LLM has its unique "security maze", and attackers attempt to find the exit learning from the received feedback and their accumulated experience to compromise the target LLM's security defences. Our approach leverages multi-agent reinforcement learning, where smaller models collaborate to guide the main LLM in performing mutation operations to achieve the attack objectives. By progressively modifying inputs based on the model's feedback, our system induces richer, harmful responses. During our manual attempts to perform jailbreak attacks, we found that the vocabulary of the response of the target model gradually became richer and eventually produced harmful responses. Based on the observation, we also introduce a reward mechanism that exploits the expansion of vocabulary richness in LLM responses to weaken security constraints. Our method outperforms five state-of-the-art attack techniques when tested across 13 commercial and open-source LLMs, achieving high attack success rates, especially in strongly aligned commercial models like GPT-4o-mini, Claude-3.5, and GLM-4-air with strong safety alignment. This study aims to improve the understanding of LLM security vulnerabilities and we hope that this sturdy can contribute to the development of more robust defenses.
Investigating White-Box Attacks for On-Device Models
Feb 26, 2024



Numerous mobile apps have leveraged deep learning capabilities. However, on-device models are vulnerable to attacks as they can be easily extracted from their corresponding mobile apps. Existing on-device attacking approaches only generate black-box attacks, which are far less effective and efficient than white-box strategies. This is because mobile deep learning frameworks like TFLite do not support gradient computing, which is necessary for white-box attacking algorithms. Thus, we argue that existing findings may underestimate the harmfulness of on-device attacks. To this end, we conduct a study to answer this research question: Can on-device models be directly attacked via white-box strategies? We first systematically analyze the difficulties of transforming the on-device model to its debuggable version, and propose a Reverse Engineering framework for On-device Models (REOM), which automatically reverses the compiled on-device TFLite model to the debuggable model. Specifically, REOM first transforms compiled on-device models into Open Neural Network Exchange format, then removes the non-debuggable parts, and converts them to the debuggable DL models format that allows attackers to exploit in a white-box setting. Our experimental results show that our approach is effective in achieving automated transformation among 244 TFLite models. Compared with previous attacks using surrogate models, REOM enables attackers to achieve higher attack success rates with a hundred times smaller attack perturbations. In addition, because the ONNX platform has plenty of tools for model format exchanging, the proposed method based on the ONNX platform can be adapted to other model formats. Our findings emphasize the need for developers to carefully consider their model deployment strategies, and use white-box methods to evaluate the vulnerability of on-device models.
Defense against Privacy Leakage in Federated Learning
Sep 13, 2022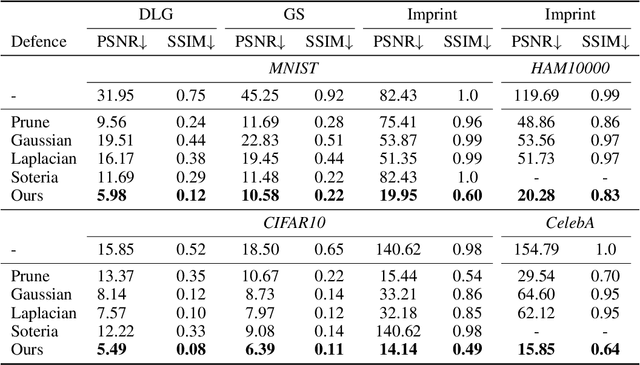
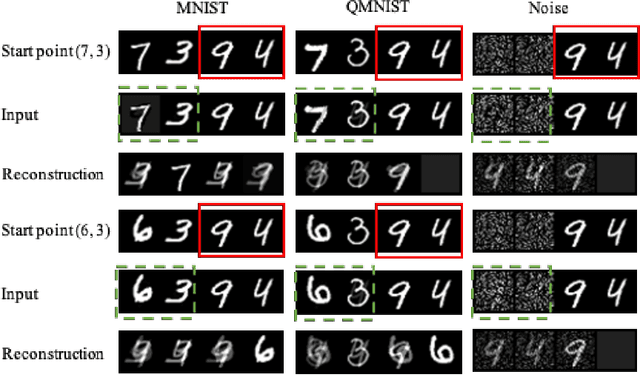


Federated Learning (FL) provides a promising distributed learning paradigm, since it seeks to protect users privacy by not sharing their private training data. Recent research has demonstrated, however, that FL is susceptible to model inversion attacks, which can reconstruct users' private data by eavesdropping on shared gradients. Existing defense solutions cannot survive stronger attacks and exhibit a poor trade-off between privacy and performance. In this paper, we present a straightforward yet effective defense strategy based on obfuscating the gradients of sensitive data with concealing data. Specifically, we alter a few samples within a mini batch to mimic the sensitive data at the gradient levels. Using a gradient projection technique, our method seeks to obscure sensitive data without sacrificing FL performance. Our extensive evaluations demonstrate that, compared to other defenses, our technique offers the highest level of protection while preserving FL performance. Our source code is located in the repository.
Performance Evaluation of Adversarial Attacks: Discrepancies and Solutions
Apr 22, 2021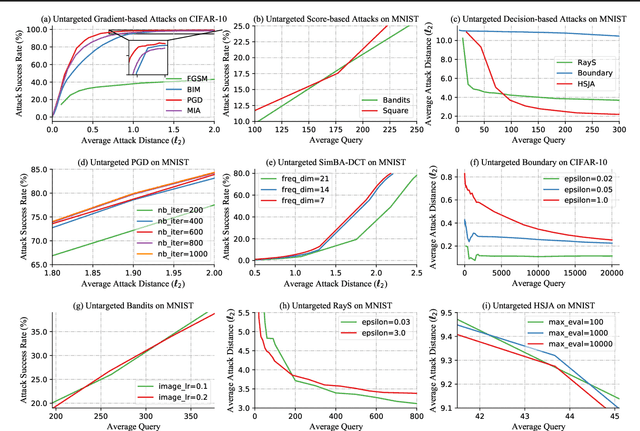

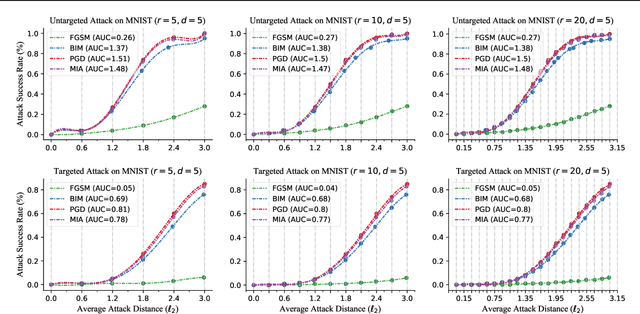
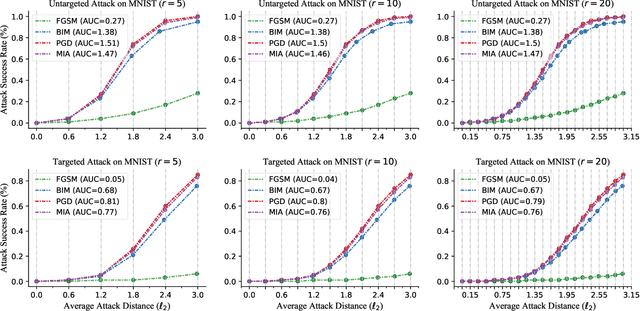
Recently, adversarial attack methods have been developed to challenge the robustness of machine learning models. However, mainstream evaluation criteria experience limitations, even yielding discrepancies among results under different settings. By examining various attack algorithms, including gradient-based and query-based attacks, we notice the lack of a consensus on a uniform standard for unbiased performance evaluation. Accordingly, we propose a Piece-wise Sampling Curving (PSC) toolkit to effectively address the aforementioned discrepancy, by generating a comprehensive comparison among adversaries in a given range. In addition, the PSC toolkit offers options for balancing the computational cost and evaluation effectiveness. Experimental results demonstrate our PSC toolkit presents comprehensive comparisons of attack algorithms, significantly reducing discrepancies in practice.
Decision-based Universal Adversarial Attack
Sep 17, 2020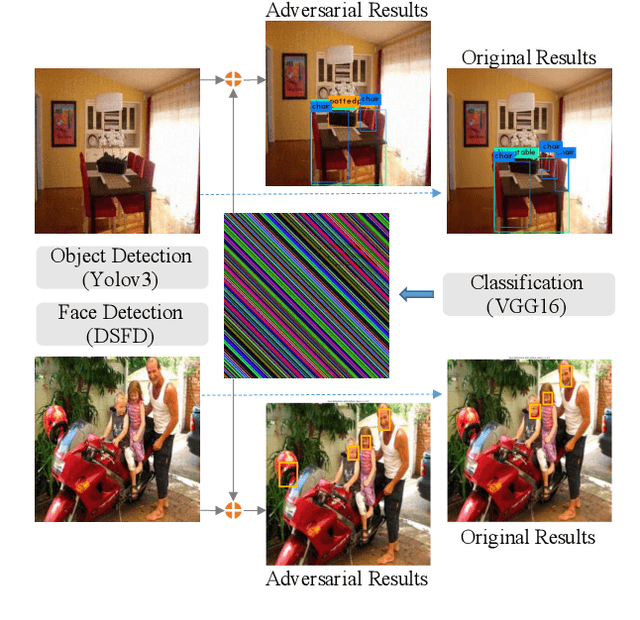



A single perturbation can pose the most natural images to be misclassified by classifiers. In black-box setting, current universal adversarial attack methods utilize substitute models to generate the perturbation, then apply the perturbation to the attacked model. However, this transfer often produces inferior results. In this study, we directly work in the black-box setting to generate the universal adversarial perturbation. Besides, we aim to design an adversary generating a single perturbation having texture like stripes based on orthogonal matrix, as the top convolutional layers are sensitive to stripes. To this end, we propose an efficient Decision-based Universal Attack (DUAttack). With few data, the proposed adversary computes the perturbation based solely on the final inferred labels, but good transferability has been realized not only across models but also span different vision tasks. The effectiveness of DUAttack is validated through comparisons with other state-of-the-art attacks. The efficiency of DUAttack is also demonstrated on real world settings including the Microsoft Azure. In addition, several representative defense methods are struggling with DUAttack, indicating the practicability of the proposed method.
ProbaNet: Proposal-balanced Network for Object Detection
May 27, 2020



Candidate object proposals generated by object detectors based on convolutional neural network (CNN) encounter easy-hard samples imbalance problem, which can affect overall performance. In this study, we propose a Proposal-balanced Network (ProbaNet) for alleviating the imbalance problem. Firstly, ProbaNet increases the probability of choosing hard samples for training by discarding easy samples through threshold truncation. Secondly, ProbaNet emphasizes foreground proposals by increasing their weights. To evaluate the effectiveness of ProbaNet, we train models based on different benchmarks. Mean Average Precision (mAP) of the model using ProbaNet achieves 1.2$\%$ higher than the baseline on PASCAL VOC 2007. Furthermore, it is compatible with existing two-stage detectors and offers a very small amount of additional computational cost.
DaST: Data-free Substitute Training for Adversarial Attacks
Mar 31, 2020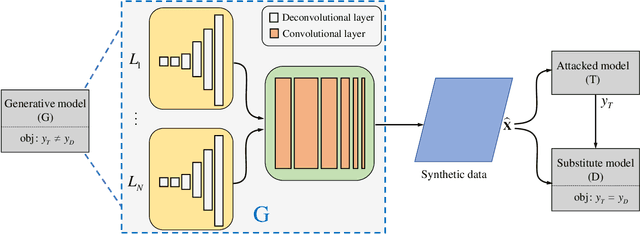
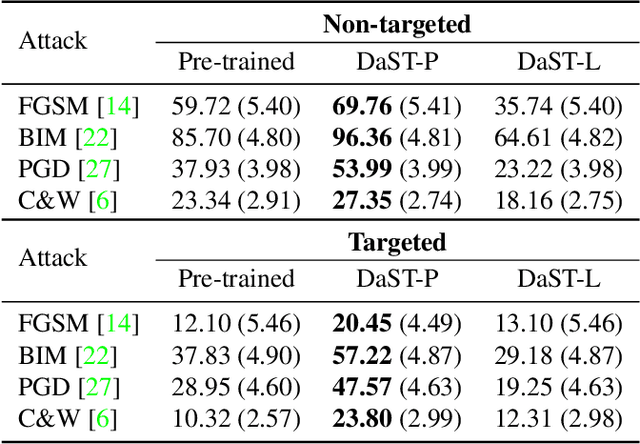
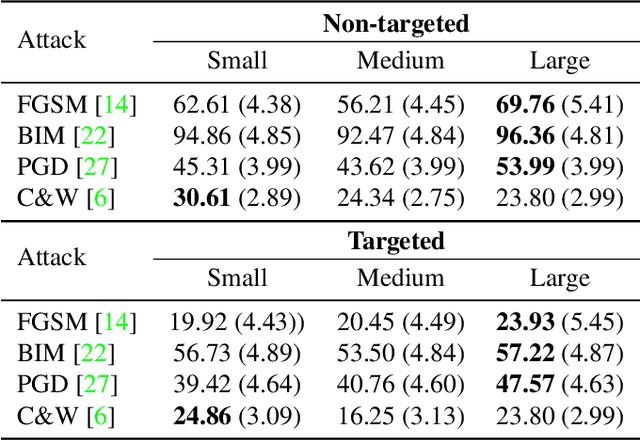

Machine learning models are vulnerable to adversarial examples. For the black-box setting, current substitute attacks need pre-trained models to generate adversarial examples. However, pre-trained models are hard to obtain in real-world tasks. In this paper, we propose a data-free substitute training method (DaST) to obtain substitute models for adversarial black-box attacks without the requirement of any real data. To achieve this, DaST utilizes specially designed generative adversarial networks (GANs) to train the substitute models. In particular, we design a multi-branch architecture and label-control loss for the generative model to deal with the uneven distribution of synthetic samples. The substitute model is then trained by the synthetic samples generated by the generative model, which are labeled by the attacked model subsequently. The experiments demonstrate the substitute models produced by DaST can achieve competitive performance compared with the baseline models which are trained by the same train set with attacked models. Additionally, to evaluate the practicability of the proposed method on the real-world task, we attack an online machine learning model on the Microsoft Azure platform. The remote model misclassifies 98.35% of the adversarial examples crafted by our method. To the best of our knowledge, we are the first to train a substitute model for adversarial attacks without any real data.
Adversarial Imitation Attack
Mar 31, 2020
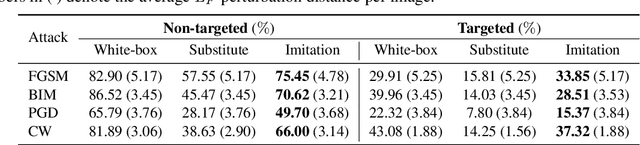
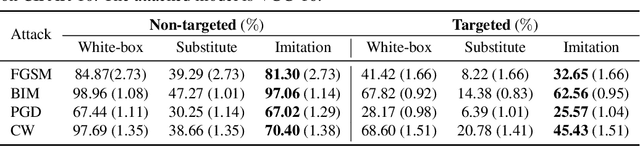

Deep learning models are known to be vulnerable to adversarial examples. A practical adversarial attack should require as little as possible knowledge of attacked models. Current substitute attacks need pre-trained models to generate adversarial examples and their attack success rates heavily rely on the transferability of adversarial examples. Current score-based and decision-based attacks require lots of queries for the attacked models. In this study, we propose a novel adversarial imitation attack. First, it produces a replica of the attacked model by a two-player game like the generative adversarial networks (GANs). The objective of the generative model is to generate examples that lead the imitation model returning different outputs with the attacked model. The objective of the imitation model is to output the same labels with the attacked model under the same inputs. Then, the adversarial examples generated by the imitation model are utilized to fool the attacked model. Compared with the current substitute attacks, imitation attacks can use less training data to produce a replica of the attacked model and improve the transferability of adversarial examples. Experiments demonstrate that our imitation attack requires less training data than the black-box substitute attacks, but achieves an attack success rate close to the white-box attack on unseen data with no query.