 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Evaluation of Adversarial Attacks: Discrepancies and Solutions
Paper and Code
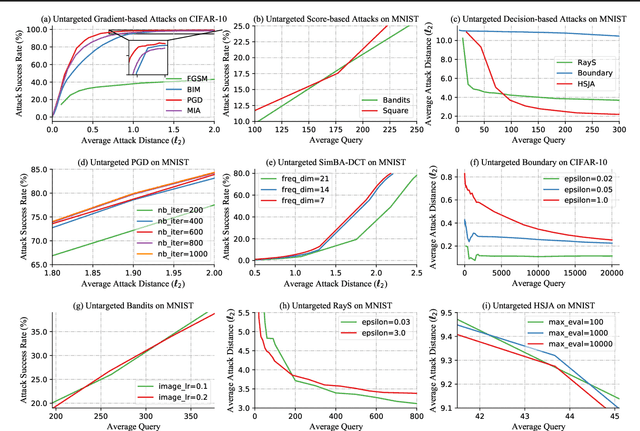

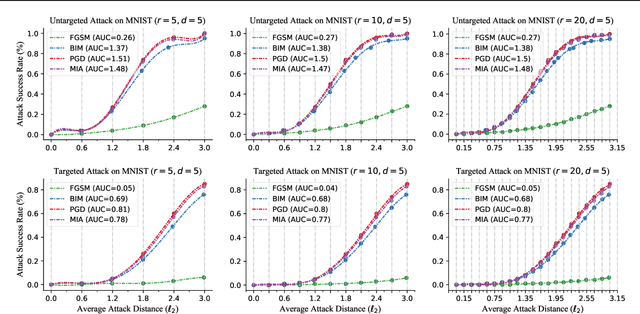
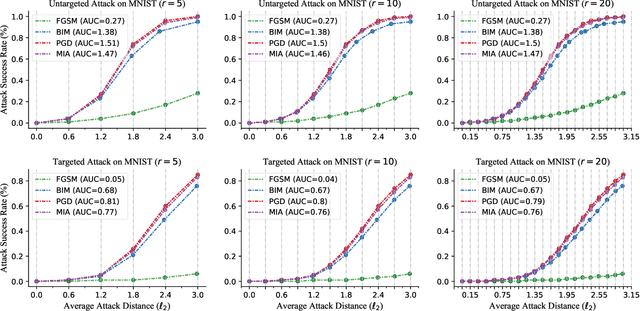
Recently, adversarial attack methods have been developed to challenge the robustness of machine learning models. However, mainstream evaluation criteria experience limitations, even yielding discrepancies among results under different settings. By examining various attack algorithms, including gradient-based and query-based attacks, we notice the lack of a consensus on a uniform standard for unbiased performance evaluation. Accordingly, we propose a Piece-wise Sampling Curving (PSC) toolkit to effectively address the aforementioned discrepancy, by generating a comprehensive comparison among adversaries in a given range. In addition, the PSC toolkit offers options for balancing the computational cost and evaluation effectiveness. Experimental results demonstrate our PSC toolkit presents comprehensive comparisons of attack algorithms, significantly reducing discrepancies in practice.