 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepNuParc: A Novel Deep Clustering Framework for Fine-scale Parcellation of Brain Nuclei Using Diffusion MRI Tractography
Mar 10, 2025



Brain nuclei are clusters of anatomically distinct neurons that serve as important hubs for processing and relaying information in various neural circuits. Fine-scale parcellation of the brain nuclei is vital for a comprehensive understanding of its anatomico-functional correlations. Diffusion MRI tractography is an advanced imaging technique that can estimate the brain's white matter structural connectivity to potentially reveal the topography of the nuclei of interest for studying its subdivisions. In this work, we present a deep clustering pipeline, namely DeepNuParc, to perform automated, fine-scale parcellation of brain nuclei using diffusion MRI tractography. First, we incorporate a newly proposed deep learning approach to enable accurate segmentation of the nuclei of interest directly on the dMRI data. Next, we design a novel streamline clustering-based structural connectivity feature for a robust representation of voxels within the nuclei. Finally, we improve the popular joint dimensionality reduction and k-means clustering approach to enable nuclei parcellation at a finer scale. We demonstrate DeepNuParc on two important brain structures, i.e. the amygdala and the thalamus, that are known to have multiple anatomically and functionally distinct nuclei subdivisions. Experimental results show that DeepNuParc enables consistent parcellation of the nuclei into multiple parcels across multiple subjects and achieves good correspondence with the widely used coarse-scale atlases. Our codes are available at https://github.com/HarlandZZC/deep_nuclei_parcellation.
Differentiable Low-computation Global Correlation Loss for Monotonicity Evaluation in Quality Assessment
Jan 26, 2025In this paper, we propose a global monotonicity consistency training strategy for quality assessment, which includes a differentiable, low-computation monotonicity evaluation loss function and a global perception training mechanism. Specifically, unlike conventional ranking loss and linear programming approaches that indirectly implement the Spearman rank-order correlation coefficient (SROCC) function, our method directly converts SROCC into a loss function by making the sorting operation within SROCC differentiable and functional. Furthermore, to mitigate the discrepancies between batch optimization during network training and global evaluation of SROCC, we introduce a memory bank mechanism. This mechanism stores gradient-free predicted results from previous batches and uses them in the current batch's training to prevent abrupt gradient changes. We evaluate the performance of the proposed method on both images and point clouds quality assessment tasks, demonstrating performance gains in both cases.
Learnable Scaled Gradient Descent for Guaranteed Robust Tensor PCA
Jan 08, 2025



Robust tensor principal component analysis (RTPCA) aims to separate the low-rank and sparse components from multi-dimensional data, making it an essential technique in the signal processing and computer vision fields. Recently emerging tensor singular value decomposition (t-SVD) has gained considerable attention for its ability to better capture the low-rank structure of tensors compared to traditional matrix SVD. However, existing methods often rely on the computationally expensive tensor nuclear norm (TNN), which limits their scalability for real-world tensors. To address this issue, we explore an efficient scaled gradient descent (SGD) approach within the t-SVD framework for the first time, and propose the RTPCA-SGD method. Theoretically, we rigorously establish the recovery guarantees of RTPCA-SGD under mild assumptions, demonstrating that with appropriate parameter selection, it achieves linear convergence to the true low-rank tensor at a constant rate, independent of the condition number. To enhance its practical applicability, we further propose a learnable self-supervised deep unfolding model, which enables effective parameter learning. Numerical experiments on both synthetic and real-world datasets demonstrate the superior performance of the proposed methods while maintaining competitive computational efficiency, especially consuming less time than RTPCA-TNN.
BCDNet: A Convolutional Neural Network For Breast Cancer Detection
Aug 27, 2024



Previous research has established that breast cancer is a prevalent cancer type, with Invasive Ductal Carcinoma (IDC) being the most common subtype. The incidence of this dangerous cancer continues to rise, making accurate and rapid diagnosis, particularly in the early stages, critically important. While modern Computer-Aided Diagnosis (CAD) systems can address most cases, medical professionals still face challenges in using them in the field without powerful computing resources. In this paper, we propose a novel CNN model called BCDNet, which effectively detects IDC in histopathological images with an accuracy of up to 89.5% and reduces training time effectively.
DA-Flow: Dual Attention Normalizing Flow for Skeleton-based Video Anomaly Detection
Jun 05, 2024



Cooperation between temporal convolutional networks (TCN) and graph convolutional networks (GCN) as a processing module has shown promising results in skeleton-based video anomaly detection (SVAD). However, to maintain a lightweight model with low computational and storage complexity, shallow GCN and TCN blocks are constrained by small receptive fields and a lack of cross-dimension interaction capture. To tackle this limitation, we propose a lightweight module called the Dual Attention Module (DAM) for capturing cross-dimension interaction relationships in spatio-temporal skeletal data. It employs the frame attention mechanism to identify the most significant frames and the skeleton attention mechanism to capture broader relationships across fixed partitions with minimal parameters and flops. Furthermore, the proposed Dual Attention Normalizing Flow (DA-Flow) integrates the DAM as a post-processing unit after GCN within the normalizing flow framework. Simulations show that the proposed model is robust against noise and negative samples. Experimental results show that DA-Flow reaches competitive or better performance than the existing state-of-the-art (SOTA) methods in terms of the micro AUC metric with the fewest number of parameters. Moreover, we found that even without training, simply using random projection without dimensionality reduction on skeleton data enables substantial anomaly detection capabilities.
Tensor Polynomial Additive Model
Jun 05, 2024



Additive models can be used for interpretable machine learning for their clarity and simplicity. However, In the classical models for high-order data, the vectorization operation disrupts the data structure, which may lead to degenerated accuracy and increased computational complexity. To deal with these problems, we propose the tensor polynomial addition model (TPAM). It retains the multidimensional structure information of high-order inputs with tensor representation. The model parameter compression is achieved using a hierarchical and low-order symmetric tensor approximation. In this way, complex high-order feature interactions can be captured with fewer parameters. Moreover, The TPAM preserves the inherent interpretability of additive models, facilitating transparent decision-making and the extraction of meaningful feature values. Additionally, leveraging TPAM's transparency and ability to handle higher-order features, it is used as a post-processing module for other interpretation models by introducing two variants for class activation maps. Experimental results on a series of datasets demonstrate that TPAM can enhance accuracy by up to 30\%, and compression rate by up to 5 times, while maintaining a good interpretability.
HOIN: High-Order Implicit Neural Representations
Apr 23, 2024



Implicit neural representations (INR) suffer from worsening spectral bias, which results in overly smooth solutions to the inverse problem. To deal with this problem, we propose a universal framework for processing inverse problems called \textbf{High-Order Implicit Neural Representations (HOIN)}. By refining the traditional cascade structure to foster high-order interactions among features, HOIN enhances the model's expressive power and mitigates spectral bias through its neural tangent kernel's (NTK) strong diagonal properties, accelerating and optimizing inverse problem resolution. By analyzing the model's expression space, high-order derivatives, and the NTK matrix, we theoretically validate the feasibility of HOIN. HOIN realizes 1 to 3 dB improvements in most inverse problems, establishing a new state-of-the-art recovery quality and training efficiency, thus providing a new general paradigm for INR and paving the way for it to solve the inverse problem.
Deep unfolding Network for Hyperspectral Image Super-Resolution with Automatic Exposure Correction
Mar 14, 2024In recent years, the fusion of high spatial resolution multispectral image (HR-MSI) and low spatial resolution hyperspectral image (LR-HSI) has been recognized as an effective method for HSI super-resolution (HSI-SR). However, both HSI and MSI may be acquired under extreme conditions such as night or poorly illuminating scenarios, which may cause different exposure levels, thereby seriously downgrading the yielded HSISR. In contrast to most existing methods based on respective low-light enhancements (LLIE) of MSI and HSI followed by their fusion, a deep Unfolding HSI Super-Resolution with Automatic Exposure Correction (UHSR-AEC) is proposed, that can effectively generate a high-quality fused HSI-SR (in texture and features) even under very imbalanced exposures, thanks to the correlation between LLIE and HSI-SR taken into account. Extensive experiments are provided to demonstrate the state-of-the-art overall performance of the proposed UHSR-AEC, including comparison with some benchmark peer methods.
S^2MVTC: a Simple yet Efficient Scalable Multi-View Tensor Clustering
Mar 14, 2024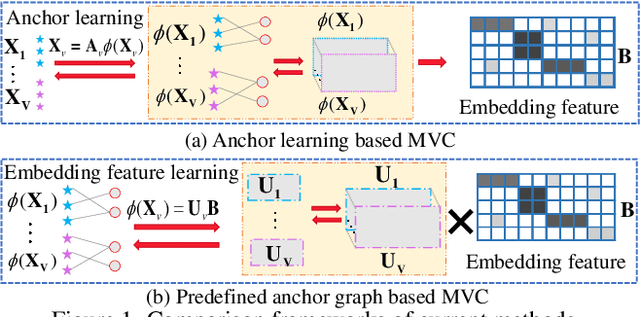

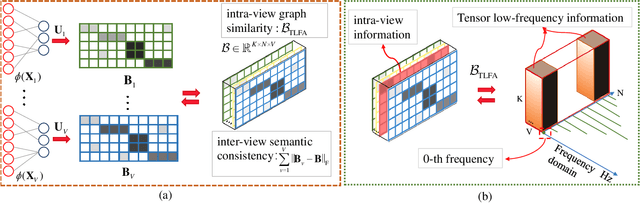
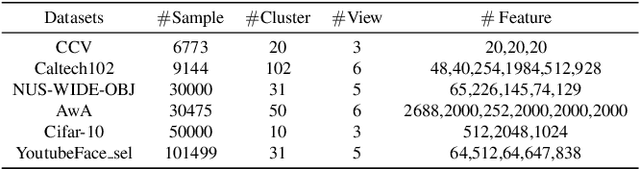
Anchor-based large-scale multi-view clustering has attracted considerable attention for its effectiveness in handling massive datasets. However, current methods mainly seek the consensus embedding feature for clustering by exploring global correlations between anchor graphs or projection matrices.In this paper, we propose a simple yet efficient scalable multi-view tensor clustering (S^2MVTC) approach, where our focus is on learning correlations of embedding features within and across views. Specifically, we first construct the embedding feature tensor by stacking the embedding features of different views into a tensor and rotating it. Additionally, we build a novel tensor low-frequency approximation (TLFA) operator, which incorporates graph similarity into embedding feature learning, efficiently achieving smooth representation of embedding features within different views. Furthermore, consensus constraints are applied to embedding features to ensure inter-view semantic consistency. Experimental results on six large-scale multi-view datasets demonstrate that S^2MVTC significantly outperforms state-of-the-art algorithms in terms of clustering performance and CPU execution time, especially when handling massive data. The code of S^2MVTC is publicly available at https://github.com/longzhen520/S2MVTC.
Inverse-Free Fast Natural Gradient Descent Method for Deep Learning
Mar 06, 2024



Second-order methods can converge much faster than first-order methods by incorporating second-order derivates or statistics, but they are far less prevalent in deep learning due to their computational inefficiency. To handle this, many of the existing solutions focus on reducing the size of the matrix to be inverted. However, it is still needed to perform the inverse operator in each iteration. In this paper, we present a fast natural gradient descent (FNGD) method, which only requires computing the inverse during the first epoch. Firstly, we reformulate the gradient preconditioning formula in the natural gradient descent (NGD) as a weighted sum of per-sample gradients using the Sherman-Morrison-Woodbury formula. Building upon this, to avoid the iterative inverse operation involved in computing coefficients, the weighted coefficients are shared across epochs without affecting the empirical performance. FNGD approximates the NGD as a fixed-coefficient weighted sum, akin to the average sum in first-order methods. Consequently, the computational complexity of FNGD can approach that of first-order methods. To demonstrate the efficiency of the proposed FNGD, we perform empirical evaluations on image classification and machine translation tasks. For training ResNet-18 on the CIFAR-100 dataset, FNGD can achieve a speedup of 2.05$\times$ compared with KFAC. For training Transformer on Multi30K, FNGD outperforms AdamW by 24 BLEU score while requiring almost the same training time.