 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummarization of Multimodal Presentations with Vision-Language Models: Study of the Effect of Modalities and Structure
Apr 14, 2025Vision-Language Models (VLMs) can process visual and textual information in multiple formats: texts, images, interleaved texts and images, or even hour-long videos. In this work, we conduct fine-grained quantitative and qualitative analyses of automatic summarization of multimodal presentations using VLMs with various representations as input. From these experiments, we suggest cost-effective strategies for generating summaries from text-heavy multimodal documents under different input-length budgets using VLMs. We show that slides extracted from the video stream can be beneficially used as input against the raw video, and that a structured representation from interleaved slides and transcript provides the best performance. Finally, we reflect and comment on the nature of cross-modal interactions in multimodal presentations and share suggestions to improve the capabilities of VLMs to understand documents of this nature.
Mitigating the Impact of Reference Quality on Evaluation of Summarization Systems with Reference-Free Metrics
Oct 08, 2024



Automatic metrics are used as proxies to evaluate abstractive summarization systems when human annotations are too expensive. To be useful, these metrics should be fine-grained, show a high correlation with human annotations, and ideally be independent of reference quality; however, most standard evaluation metrics for summarization are reference-based, and existing reference-free metrics correlate poorly with relevance, especially on summaries of longer documents. In this paper, we introduce a reference-free metric that correlates well with human evaluated relevance, while being very cheap to compute. We show that this metric can also be used alongside reference-based metrics to improve their robustness in low quality reference settings.
DA-Flow: Dual Attention Normalizing Flow for Skeleton-based Video Anomaly Detection
Jun 05, 2024



Cooperation between temporal convolutional networks (TCN) and graph convolutional networks (GCN) as a processing module has shown promising results in skeleton-based video anomaly detection (SVAD). However, to maintain a lightweight model with low computational and storage complexity, shallow GCN and TCN blocks are constrained by small receptive fields and a lack of cross-dimension interaction capture. To tackle this limitation, we propose a lightweight module called the Dual Attention Module (DAM) for capturing cross-dimension interaction relationships in spatio-temporal skeletal data. It employs the frame attention mechanism to identify the most significant frames and the skeleton attention mechanism to capture broader relationships across fixed partitions with minimal parameters and flops. Furthermore, the proposed Dual Attention Normalizing Flow (DA-Flow) integrates the DAM as a post-processing unit after GCN within the normalizing flow framework. Simulations show that the proposed model is robust against noise and negative samples. Experimental results show that DA-Flow reaches competitive or better performance than the existing state-of-the-art (SOTA) methods in terms of the micro AUC metric with the fewest number of parameters. Moreover, we found that even without training, simply using random projection without dimensionality reduction on skeleton data enables substantial anomaly detection capabilities.
A Global Appearance and Local Coding Distortion based Fusion Framework for CNN based Filtering in Video Coding
Jun 24, 2021

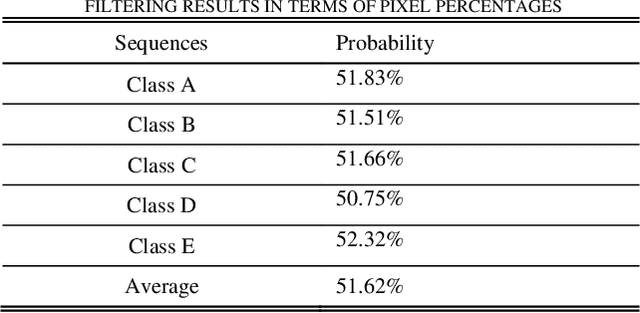
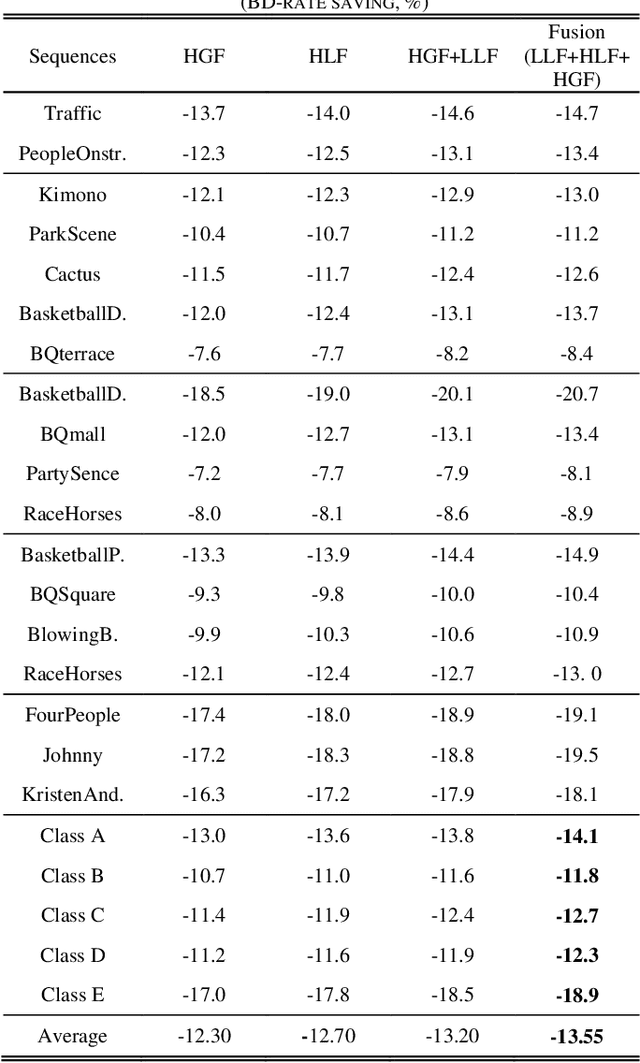
In-loop filtering is used in video coding to process the reconstructed frame in order to remove blocking artifacts. With the development of convolutional neural networks (CNNs), CNNs have been explored for in-loop filtering considering it can be treated as an image de-noising task. However, in addition to being a distorted image, the reconstructed frame is also obtained by a fixed line of block based encoding operations in video coding. It carries coding-unit based coding distortion of some similar characteristics. Therefore, in this paper, we address the filtering problem from two aspects, global appearance restoration for disrupted texture and local coding distortion restoration caused by fixed pipeline of coding. Accordingly, a three-stream global appearance and local coding distortion based fusion network is developed with a high-level global feature stream, a high-level local feature stream and a low-level local feature stream. Ablation study is conducted to validate the necessity of different features, demonstrating that the global features and local features can complement each other in filtering and achieve better performance when combined. To the best of our knowledge, we are the first one that clearly characterizes the video filtering process from the above global appearance and local coding distortion restoration aspects with experimental verification, providing a clear pathway to developing filter techniques. Experimental results demonstrate that the proposed method significantly outperforms the existing single-frame based methods and achieves 13.5%, 11.3%, 11.7% BD-Rate saving on average for AI, LDP and RA configurations, respectively, compared with the HEVC reference software.