 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Cross-Architecture Knowledge Transfer for Large-Scale Online User Response Prediction
Feb 02, 2026Deploying new architectures in large-scale user response prediction systems incurs high model switching costs due to expensive retraining on massive historical data and performance degradation under data retention constraints. Existing knowledge distillation methods struggle with architectural heterogeneity and the prohibitive cost of transferring large embedding tables. We propose CrossAdapt, a two-stage framework for efficient cross-architecture knowledge transfer. The offline stage enables rapid embedding transfer via dimension-adaptive projections without iterative training, combined with progressive network distillation and strategic sampling to reduce computational cost. The online stage introduces asymmetric co-distillation, where students update frequently while teachers update infrequently, together with a distribution-aware adaptation mechanism that dynamically balances historical knowledge preservation and fast adaptation to evolving data. Experiments on three public datasets show that CrossAdapt achieves 0.27-0.43% AUC improvements while reducing training time by 43-71%. Large-scale deployment on Tencent WeChat Channels (~10M daily samples) further demonstrates its effectiveness, significantly mitigating AUC degradation, LogLoss increase, and prediction bias compared to standard distillation baselines.
Occlusion-Aware 3D Hand-Object Pose Estimation with Masked AutoEncoders
Jun 12, 2025Hand-object pose estimation from monocular RGB images remains a significant challenge mainly due to the severe occlusions inherent in hand-object interactions. Existing methods do not sufficiently explore global structural perception and reasoning, which limits their effectiveness in handling occluded hand-object interactions. To address this challenge, we propose an occlusion-aware hand-object pose estimation method based on masked autoencoders, termed as HOMAE. Specifically, we propose a target-focused masking strategy that imposes structured occlusion on regions of hand-object interaction, encouraging the model to learn context-aware features and reason about the occluded structures. We further integrate multi-scale features extracted from the decoder to predict a signed distance field (SDF), capturing both global context and fine-grained geometry. To enhance geometric perception, we combine the implicit SDF with an explicit point cloud derived from the SDF, leveraging the complementary strengths of both representations. This fusion enables more robust handling of occluded regions by combining the global context from the SDF with the precise local geometry provided by the point cloud. Extensive experiments on challenging DexYCB and HO3Dv2 benchmarks demonstrate that HOMAE achieves state-of-the-art performance in hand-object pose estimation. We will release our code and model.
Rebalancing Contrastive Alignment with Learnable Semantic Gaps in Text-Video Retrieval
May 18, 2025Recent advances in text-video retrieval have been largely driven by contrastive learning frameworks. However, existing methods overlook a key source of optimization tension: the separation between text and video distributions in the representation space (referred to as the modality gap), and the prevalence of false negatives in batch sampling. These factors lead to conflicting gradients under the InfoNCE loss, impeding stable alignment. To mitigate this, we propose GARE, a Gap-Aware Retrieval framework that introduces a learnable, pair-specific increment Delta_ij between text t_i and video v_j to offload the tension from the global anchor representation. We first derive the ideal form of Delta_ij via a coupled multivariate first-order Taylor approximation of the InfoNCE loss under a trust-region constraint, revealing it as a mechanism for resolving gradient conflicts by guiding updates along a locally optimal descent direction. Due to the high cost of directly computing Delta_ij, we introduce a lightweight neural module conditioned on the semantic gap between each video-text pair, enabling structure-aware correction guided by gradient supervision. To further stabilize learning and promote interpretability, we regularize Delta using three components: a trust-region constraint to prevent oscillation, a directional diversity term to promote semantic coverage, and an information bottleneck to limit redundancy. Experiments across four retrieval benchmarks show that GARE consistently improves alignment accuracy and robustness to noisy supervision, confirming the effectiveness of gap-aware tension mitigation.
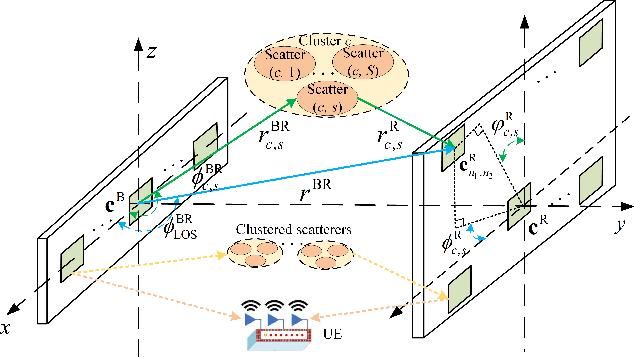
Channel Estimation for Pinching-Antenna Systems (PASS)
Mar 17, 2025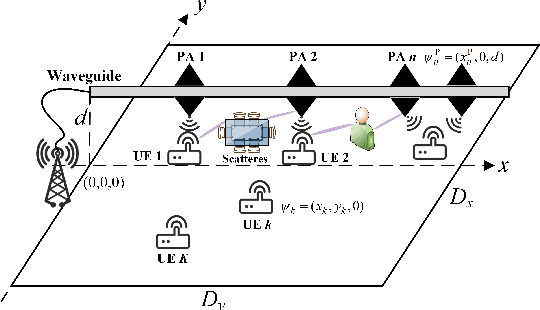
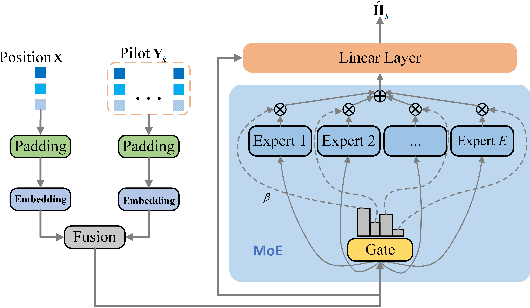
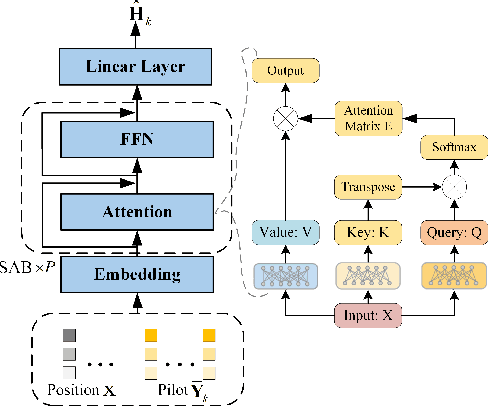
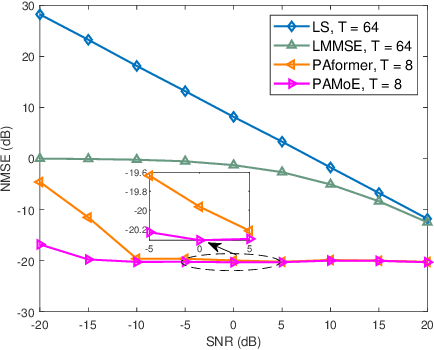
Pinching Antennas (PAs) represent a revolutionary flexible antenna technology that leverages dielectric waveguides and electromagnetic coupling to mitigate large-scale path loss. This letter is the first to explore channel estimation for Pinching-Antenna SyStems (PASS), addressing their uniquely ill-conditioned and underdetermined channel characteristics. In particular, two efficient deep learning-based channel estimators are proposed. 1) PAMoE: This estimator incorporates dynamic padding, feature embedding, fusion, and mixture of experts (MoE) modules, which effectively leverage the positional information of PAs and exploit expert diversity. 2) PAformer: This Transformer-style estimator employs the self-attention mechanism to predict channel coefficients in a per-antenna manner, which offers more flexibility to adaptively deal with dynamic numbers of PAs in practical deployment. Numerical results demonstrate that 1) the proposed deep learning-based channel estimators outperform conventional methods and exhibit excellent zero-shot learning capabilities, and 2) PAMoE delivers higher channel estimation accuracy via MoE specialization, while PAformer natively handles an arbitrary number of PAs, trading self-attention complexity for superior scalability.
Aerial Reliable Collaborative Communications for Terrestrial Mobile Users via Evolutionary Multi-Objective Deep Reinforcement Learning
Feb 09, 2025

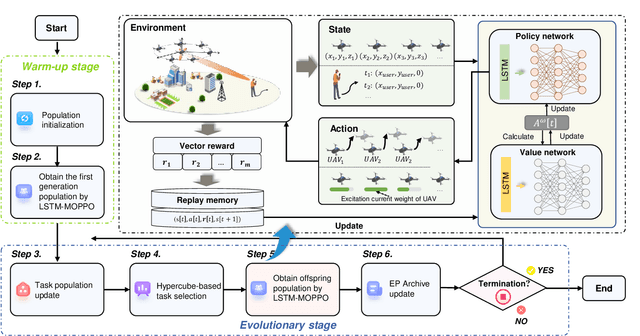

Unmanned aerial vehicles (UAVs) have emerged as the potential aerial base stations (BSs) to improve terrestrial communications. However, the limited onboard energy and antenna power of a UAV restrict its communication range and transmission capability. To address these limitations, this work employs collaborative beamforming through a UAV-enabled virtual antenna array to improve transmission performance from the UAV to terrestrial mobile users, under interference from non-associated BSs and dynamic channel conditions. Specifically, we introduce a memory-based random walk model to more accurately depict the mobility patterns of terrestrial mobile users. Following this, we formulate a multi-objective optimization problem (MOP) focused on maximizing the transmission rate while minimizing the flight energy consumption of the UAV swarm. Given the NP-hard nature of the formulated MOP and the highly dynamic environment, we transform this problem into a multi-objective Markov decision process and propose an improved evolutionary multi-objective reinforcement learning algorithm. Specifically, this algorithm introduces an evolutionary learning approach to obtain the approximate Pareto set for the formulated MOP. Moreover, the algorithm incorporates a long short-term memory network and hyper-sphere-based task selection method to discern the movement patterns of terrestrial mobile users and improve the diversity of the obtained Pareto set. Simulation results demonstrate that the proposed method effectively generates a diverse range of non-dominated policies and outperforms existing methods. Additional simulations demonstrate the scalability and robustness of the proposed CB-based method under different system parameters and various unexpected circumstances.
CAdam: Confidence-Based Optimization for Online Learning
Nov 29, 2024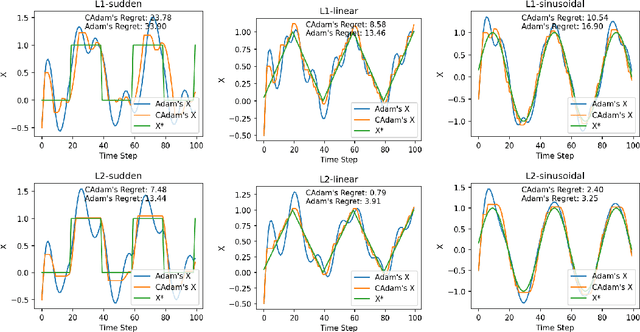

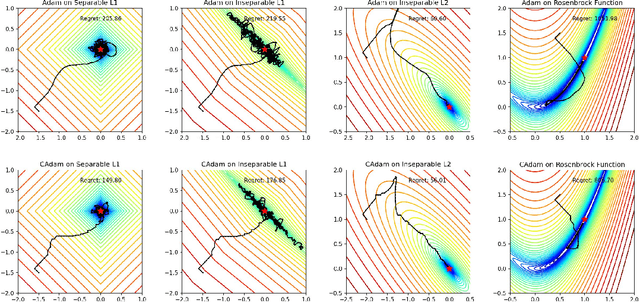

Modern recommendation systems frequently employ online learning to dynamically update their models with freshly collected data. The most commonly used optimizer for updating neural networks in these contexts is the Adam optimizer, which integrates momentum ($m_t$) and adaptive learning rate ($v_t$). However, the volatile nature of online learning data, characterized by its frequent distribution shifts and presence of noises, poses significant challenges to Adam's standard optimization process: (1) Adam may use outdated momentum and the average of squared gradients, resulting in slower adaptation to distribution changes, and (2) Adam's performance is adversely affected by data noise. To mitigate these issues, we introduce CAdam, a confidence-based optimization strategy that assesses the consistence between the momentum and the gradient for each parameter dimension before deciding on updates. If momentum and gradient are in sync, CAdam proceeds with parameter updates according to Adam's original formulation; if not, it temporarily withholds updates and monitors potential shifts in data distribution in subsequent iterations. This method allows CAdam to distinguish between the true distributional shifts and mere noise, and adapt more quickly to new data distributions. Our experiments with both synthetic and real-world datasets demonstrate that CAdam surpasses other well-known optimizers, including the original Adam, in efficiency and noise robustness. Furthermore, in large-scale A/B testing within a live recommendation system, CAdam significantly enhances model performance compared to Adam, leading to substantial increases in the system's gross merchandise volume (GMV).
Decomposing Relationship from 1-to-N into N 1-to-1 for Text-Video Retrieval
Oct 09, 2024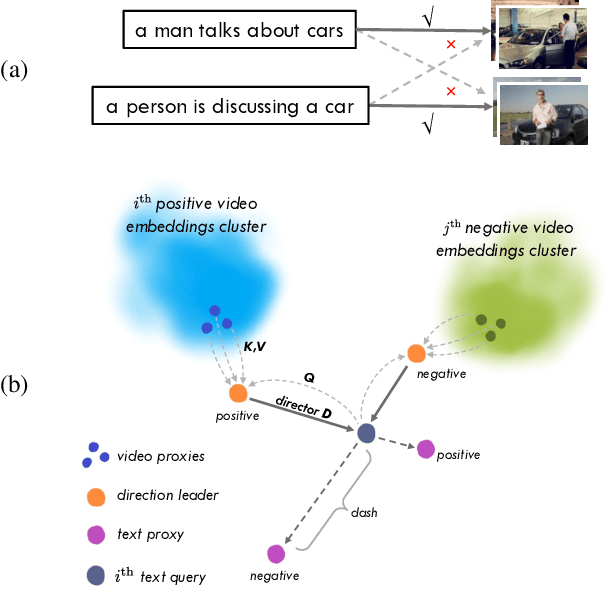
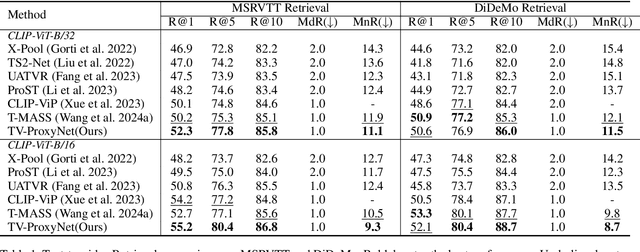
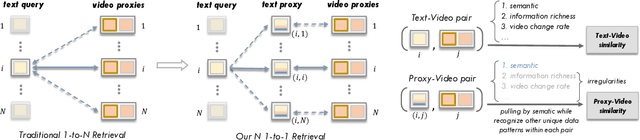
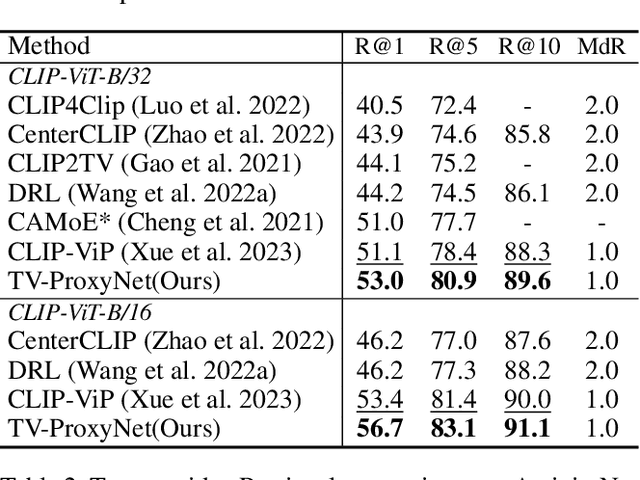
Text-video retrieval (TVR) has seen substantial advancements in recent years, fueled by the utilization of pre-trained models and large language models (LLMs). Despite these advancements, achieving accurate matching in TVR remains challenging due to inherent disparities between video and textual modalities and irregularities in data representation. In this paper, we propose Text-Video-ProxyNet (TV-ProxyNet), a novel framework designed to decompose the conventional 1-to-N relationship of TVR into N distinct 1-to-1 relationships. By replacing a single text query with a series of text proxies, TV-ProxyNet not only broadens the query scope but also achieves a more precise expansion. Each text proxy is crafted through a refined iterative process, controlled by mechanisms we term as the director and dash, which regulate the proxy's direction and distance relative to the original text query. This setup not only facilitates more precise semantic alignment but also effectively manages the disparities and noise inherent in multimodal data. Our experiments on three representative video-text retrieval benchmarks, MSRVTT, DiDeMo, and ActivityNet Captions, demonstrate the effectiveness of TV-ProxyNet. The results show an improvement of 2.0% to 3.3% in R@1 over the baseline. TV-ProxyNet achieved state-of-the-art performance on MSRVTT and ActivityNet Captions, and a 2.0% improvement on DiDeMo compared to existing methods, validating our approach's ability to enhance semantic mapping and reduce error propensity.
DA-Flow: Dual Attention Normalizing Flow for Skeleton-based Video Anomaly Detection
Jun 05, 2024



Cooperation between temporal convolutional networks (TCN) and graph convolutional networks (GCN) as a processing module has shown promising results in skeleton-based video anomaly detection (SVAD). However, to maintain a lightweight model with low computational and storage complexity, shallow GCN and TCN blocks are constrained by small receptive fields and a lack of cross-dimension interaction capture. To tackle this limitation, we propose a lightweight module called the Dual Attention Module (DAM) for capturing cross-dimension interaction relationships in spatio-temporal skeletal data. It employs the frame attention mechanism to identify the most significant frames and the skeleton attention mechanism to capture broader relationships across fixed partitions with minimal parameters and flops. Furthermore, the proposed Dual Attention Normalizing Flow (DA-Flow) integrates the DAM as a post-processing unit after GCN within the normalizing flow framework. Simulations show that the proposed model is robust against noise and negative samples. Experimental results show that DA-Flow reaches competitive or better performance than the existing state-of-the-art (SOTA) methods in terms of the micro AUC metric with the fewest number of parameters. Moreover, we found that even without training, simply using random projection without dimensionality reduction on skeleton data enables substantial anomaly detection capabilities.
Wideband Beamforming for RIS Assisted Near-Field Communications
Jan 20, 2024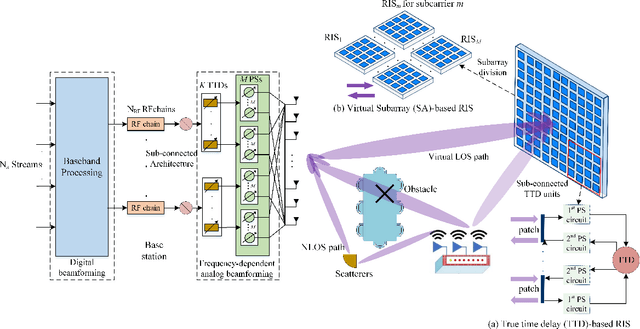
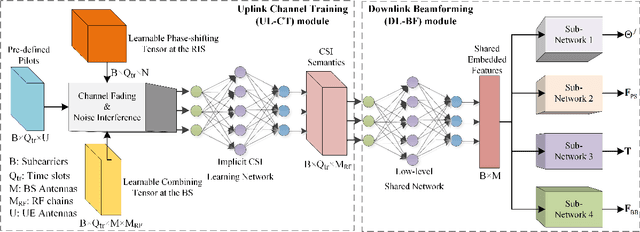
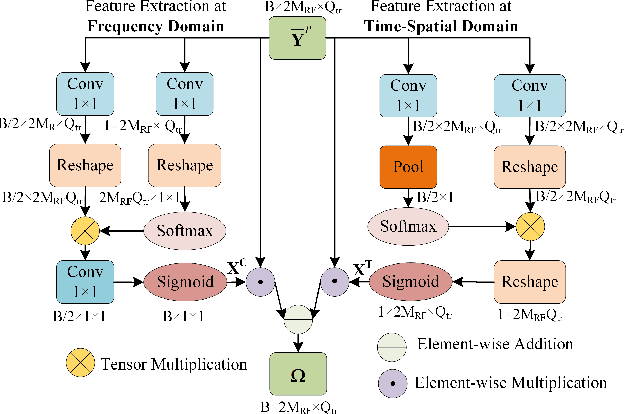
A near-field wideband beamforming scheme is investigated for reconfigurable intelligent surface (RIS) assisted multiple-input multiple-output (MIMO) systems, in which a deep learning-based end-to-end (E2E) optimization framework is proposed to maximize the system spectral efficiency. To deal with the near-field double beam split effect, the base station is equipped with frequency-dependent hybrid precoding architecture by introducing sub-connected true time delay (TTD) units, while two specific RIS architectures, namely true time delay-based RIS (TTD-RIS) and virtual subarray-based RIS (SA-RIS), are exploited to realize the frequency-dependent passive beamforming at the RIS. Furthermore, the efficient E2E beamforming models without explicit channel state information are proposed, which jointly exploits the uplink channel training module and the downlink wideband beamforming module. In the proposed network architecture of the E2E models, the classical communication signal processing methods, i.e., polarized filtering and sparsity transform, are leveraged to develop a signal-guided beamforming network. Numerical results show that the proposed E2E models have superior beamforming performance and robustness to conventional beamforming benchmarks. Furthermore, the tradeoff between the beamforming gain and the hardware complexity is investigated for different frequency-dependent RIS architectures, in which the TTD-RIS can achieve better spectral efficiency than the SA-RIS while requiring additional energy consumption and hardware cost.
Divide and Conquer in Video Anomaly Detection: A Comprehensive Review and New Approach
Oct 03, 2023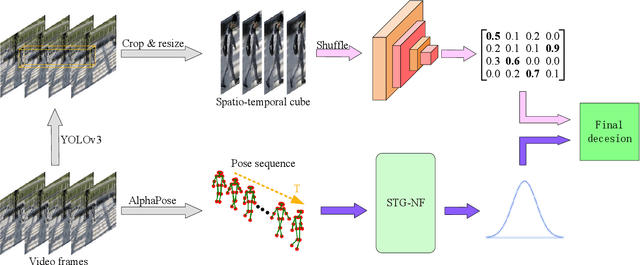
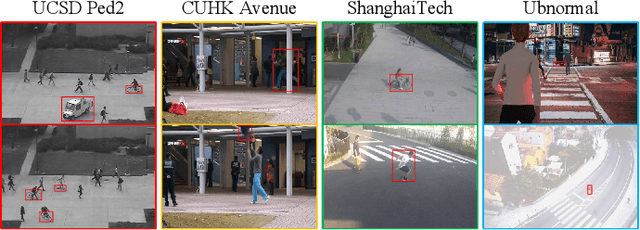
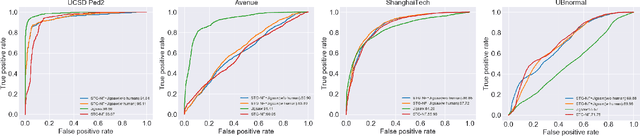
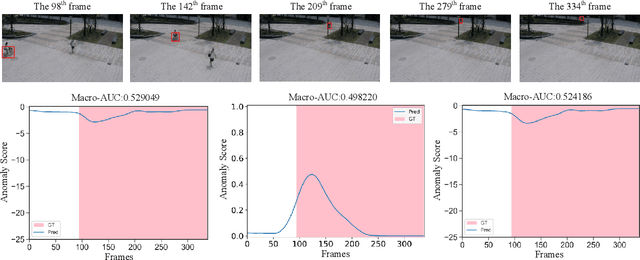
Video anomaly detection is a complex task, and the principle of "divide and conquer" is often regarded as an effective approach to tackling intricate issues. It's noteworthy that recent methods in video anomaly detection have revealed the application of the divide and conquer philosophy (albeit with distinct perspectives from traditional usage), yielding impressive outcomes. This paper systematically reviews these literatures from six dimensions, aiming to enhance the use of the divide and conquer strategy in video anomaly detection. Furthermore, based on the insights gained from this review, a novel approach is presented, which integrates human skeletal frameworks with video data analysis techniques. This method achieves state-of-the-art performance on the ShanghaiTech dataset, surpassing all existing advanced methods.