 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposing Relationship from 1-to-N into N 1-to-1 for Text-Video Retrieval
Paper and Code
Oct 09, 2024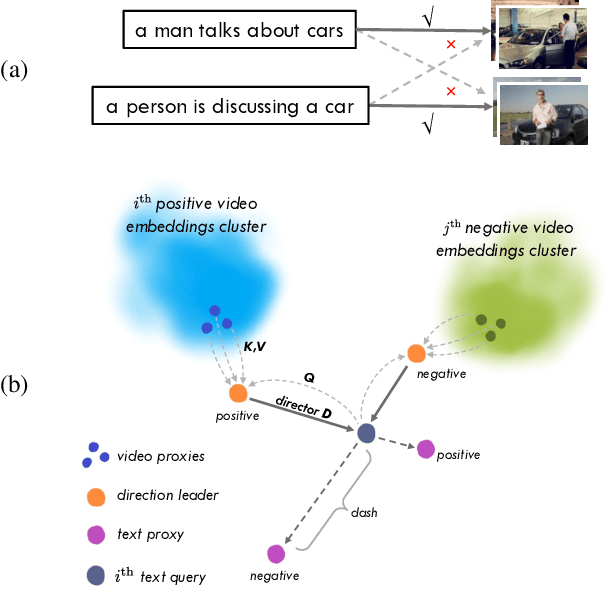
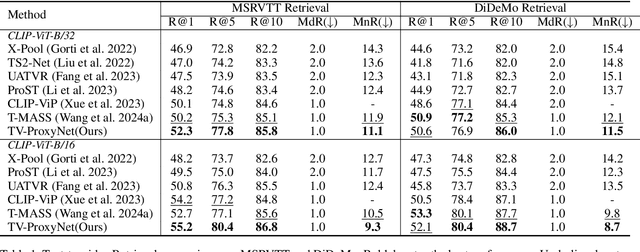
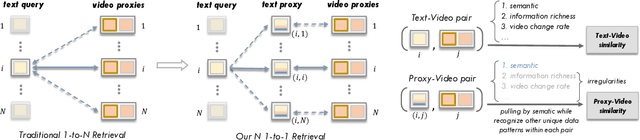
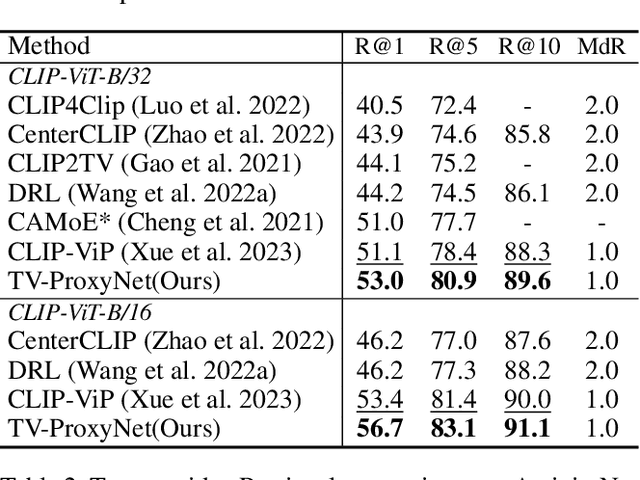
Text-video retrieval (TVR) has seen substantial advancements in recent years, fueled by the utilization of pre-trained models and large language models (LLMs). Despite these advancements, achieving accurate matching in TVR remains challenging due to inherent disparities between video and textual modalities and irregularities in data representation. In this paper, we propose Text-Video-ProxyNet (TV-ProxyNet), a novel framework designed to decompose the conventional 1-to-N relationship of TVR into N distinct 1-to-1 relationships. By replacing a single text query with a series of text proxies, TV-ProxyNet not only broadens the query scope but also achieves a more precise expansion. Each text proxy is crafted through a refined iterative process, controlled by mechanisms we term as the director and dash, which regulate the proxy's direction and distance relative to the original text query. This setup not only facilitates more precise semantic alignment but also effectively manages the disparities and noise inherent in multimodal data. Our experiments on three representative video-text retrieval benchmarks, MSRVTT, DiDeMo, and ActivityNet Captions, demonstrate the effectiveness of TV-ProxyNet. The results show an improvement of 2.0% to 3.3% in R@1 over the baseline. TV-ProxyNet achieved state-of-the-art performance on MSRVTT and ActivityNet Captions, and a 2.0% improvement on DiDeMo compared to existing methods, validating our approach's ability to enhance semantic mapping and reduce error propensity.