 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummarization of Multimodal Presentations with Vision-Language Models: Study of the Effect of Modalities and Structure
Apr 14, 2025Vision-Language Models (VLMs) can process visual and textual information in multiple formats: texts, images, interleaved texts and images, or even hour-long videos. In this work, we conduct fine-grained quantitative and qualitative analyses of automatic summarization of multimodal presentations using VLMs with various representations as input. From these experiments, we suggest cost-effective strategies for generating summaries from text-heavy multimodal documents under different input-length budgets using VLMs. We show that slides extracted from the video stream can be beneficially used as input against the raw video, and that a structured representation from interleaved slides and transcript provides the best performance. Finally, we reflect and comment on the nature of cross-modal interactions in multimodal presentations and share suggestions to improve the capabilities of VLMs to understand documents of this nature.
Mitigating the Impact of Reference Quality on Evaluation of Summarization Systems with Reference-Free Metrics
Oct 08, 2024



Automatic metrics are used as proxies to evaluate abstractive summarization systems when human annotations are too expensive. To be useful, these metrics should be fine-grained, show a high correlation with human annotations, and ideally be independent of reference quality; however, most standard evaluation metrics for summarization are reference-based, and existing reference-free metrics correlate poorly with relevance, especially on summaries of longer documents. In this paper, we introduce a reference-free metric that correlates well with human evaluated relevance, while being very cheap to compute. We show that this metric can also be used alongside reference-based metrics to improve their robustness in low quality reference settings.
Cross-modal Retrieval for Knowledge-based Visual Question Answering
Jan 11, 2024Knowledge-based Visual Question Answering about Named Entities is a challenging task that requires retrieving information from a multimodal Knowledge Base. Named entities have diverse visual representations and are therefore difficult to recognize. We argue that cross-modal retrieval may help bridge the semantic gap between an entity and its depictions, and is foremost complementary with mono-modal retrieval. We provide empirical evidence through experiments with a multimodal dual encoder, namely CLIP, on the recent ViQuAE, InfoSeek, and Encyclopedic-VQA datasets. Additionally, we study three different strategies to fine-tune such a model: mono-modal, cross-modal, or joint training. Our method, which combines mono-and cross-modal retrieval, is competitive with billion-parameter models on the three datasets, while being conceptually simpler and computationally cheaper.
Multimodal Inverse Cloze Task for Knowledge-based Visual Question Answering
Jan 11, 2023


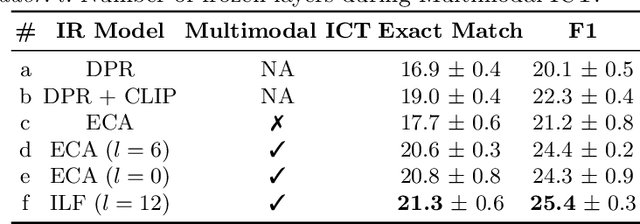
We present a new pre-training method, Multimodal Inverse Cloze Task, for Knowledge-based Visual Question Answering about named Entities (KVQAE). KVQAE is a recently introduced task that consists in answering questions about named entities grounded in a visual context using a Knowledge Base. Therefore, the interaction between the modalities is paramount to retrieve information and must be captured with complex fusion models. As these models require a lot of training data, we design this pre-training task from existing work in textual Question Answering. It consists in considering a sentence as a pseudo-question and its context as a pseudo-relevant passage and is extended by considering images near texts in multimodal documents. Our method is applicable to different neural network architectures and leads to a 9% relative-MRR and 15% relative-F1 gain for retrieval and reading comprehension, respectively, over a no-pre-training baseline.