 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupporting Workflow Reproducibility by Linking Bioinformatics Tools across Papers and Executable Code
Mar 09, 2026Motivation: The rapid growth of biological data has intensified the need for transparent, reproducible, and well-documented computational workflows. The ability to clearly connect the steps of a workflow in the code with their description in a paper would improve workflow understanding, support reproducibility, and facilitate reuse. This task requires the linking of Bioinformatics tools in workflow code with their mentions in a published workflow description. Results: We present CoPaLink, an automated approach that integrates three components: Named Entity Recognition (NER) for identifying tool mentions in scientific text, NER for tool mentions in workflow code, and entity linking grounded on Bioinformatics knowledge bases. We propose approaches for all three steps achieving a high individual F1-measure (84 - 89) and a joint accuracy of 66 when evaluated on Nextflow workflows using Bioconda and Bioweb Knowledge bases. CoPaLink leverages corpora of scientific articles and workflow executable code with curated tool annotations to bridge the gap between narrative descriptions and workflow implementations. Availability: The code is available at https://gitlab.liris.cnrs.fr/sharefair/copalink-experiments and https://gitlab.liris.cnrs.fr/sharefair/copalink. The corpora are also available at https://doi.org/10.5281/zenodo.18526700, https://doi.org/10.5281/zenodo.18526760 and https://doi.org/10.5281/zenodo.18543814.
Text-to-Image Alignment in Denoising-Based Models through Step Selection
Apr 24, 2025Visual generative AI models often encounter challenges related to text-image alignment and reasoning limitations. This paper presents a novel method for selectively enhancing the signal at critical denoising steps, optimizing image generation based on input semantics. Our approach addresses the shortcomings of early-stage signal modifications, demonstrating that adjustments made at later stages yield superior results. We conduct extensive experiments to validate the effectiveness of our method in producing semantically aligned images on Diffusion and Flow Matching model, achieving state-of-the-art performance. Our results highlight the importance of a judicious choice of sampling stage to improve performance and overall image alignment.
Extracting Information in a Low-resource Setting: Case Study on Bioinformatics Workflows
Nov 28, 2024Bioinformatics workflows are essential for complex biological data analyses and are often described in scientific articles with source code in public repositories. Extracting detailed workflow information from articles can improve accessibility and reusability but is hindered by limited annotated corpora. To address this, we framed the problem as a low-resource extraction task and tested four strategies: 1) creating a tailored annotated corpus, 2) few-shot named-entity recognition (NER) with an autoregressive language model, 3) NER using masked language models with existing and new corpora, and 4) integrating workflow knowledge into NER models. Using BioToFlow, a new corpus of 52 articles annotated with 16 entities, a SciBERT-based NER model achieved a 70.4 F-measure, comparable to inter-annotator agreement. While knowledge integration improved performance for specific entities, it was less effective across the entire information schema. Our results demonstrate that high-performance information extraction for bioinformatics workflows is achievable.
From LIMA to DeepLIMA: following a new path of interoperability
Sep 10, 2024In this article, we describe the architecture of the LIMA (Libre Multilingual Analyzer) framework and its recent evolution with the addition of new text analysis modules based on deep neural networks. We extended the functionality of LIMA in terms of the number of supported languages while preserving existing configurable architecture and the availability of previously developed rule-based and statistical analysis components. Models were trained for more than 60 languages on the Universal Dependencies 2.5 corpora, WikiNer corpora, and CoNLL-03 dataset. Universal Dependencies allowed us to increase the number of supported languages and to generate models that could be integrated into other platforms. This integration of ubiquitous Deep Learning Natural Language Processing models and the use of standard annotated collections using Universal Dependencies can be viewed as a new path of interoperability, through the normalization of models and data, that are complementary to a more standard technical interoperability, implemented in LIMA through services available in Docker containers on Docker Hub.
Cross-modal Retrieval for Knowledge-based Visual Question Answering
Jan 11, 2024Knowledge-based Visual Question Answering about Named Entities is a challenging task that requires retrieving information from a multimodal Knowledge Base. Named entities have diverse visual representations and are therefore difficult to recognize. We argue that cross-modal retrieval may help bridge the semantic gap between an entity and its depictions, and is foremost complementary with mono-modal retrieval. We provide empirical evidence through experiments with a multimodal dual encoder, namely CLIP, on the recent ViQuAE, InfoSeek, and Encyclopedic-VQA datasets. Additionally, we study three different strategies to fine-tune such a model: mono-modal, cross-modal, or joint training. Our method, which combines mono-and cross-modal retrieval, is competitive with billion-parameter models on the three datasets, while being conceptually simpler and computationally cheaper.
Probing Pretrained Language Models with Hierarchy Properties
Dec 15, 2023Since Pretrained Language Models (PLMs) are the cornerstone of the most recent Information Retrieval (IR) models, the way they encode semantic knowledge is particularly important. However, little attention has been given to studying the PLMs' capability to capture hierarchical semantic knowledge. Traditionally, evaluating such knowledge encoded in PLMs relies on their performance on a task-dependent evaluation approach based on proxy tasks, such as hypernymy detection. Unfortunately, this approach potentially ignores other implicit and complex taxonomic relations. In this work, we propose a task-agnostic evaluation method able to evaluate to what extent PLMs can capture complex taxonomy relations, such as ancestors and siblings. The evaluation is based on intrinsic properties that capture the hierarchical nature of taxonomies. Our experimental evaluation shows that the lexico-semantic knowledge implicitly encoded in PLMs does not always capture hierarchical relations. We further demonstrate that the proposed properties can be injected into PLMs to improve their understanding of hierarchy. Through evaluations on taxonomy reconstruction, hypernym discovery and reading comprehension tasks, we show that the knowledge about hierarchy is moderately but not systematically transferable across tasks.
TIAM -- A Metric for Evaluating Alignment in Text-to-Image Generation
Jul 11, 2023The progress in the generation of synthetic images has made it crucial to assess their quality. While several metrics have been proposed to assess the rendering of images, it is crucial for Text-to-Image (T2I) models, which generate images based on a prompt, to consider additional aspects such as to which extent the generated image matches the important content of the prompt. Moreover, although the generated images usually result from a random starting point, the influence of this one is generally not considered. In this article, we propose a new metric based on prompt templates to study the alignment between the content specified in the prompt and the corresponding generated images. It allows us to better characterize the alignment in terms of the type of the specified objects, their number, and their color. We conducted a study on several recent T2I models about various aspects. An additional interesting result we obtained with our approach is that image quality can vary drastically depending on the latent noise used as a seed for the images. We also quantify the influence of the number of concepts in the prompt, their order as well as their (color) attributes. Finally, our method allows us to identify some latent seeds that produce better images than others, opening novel directions of research on this understudied topic.
Multimodal Inverse Cloze Task for Knowledge-based Visual Question Answering
Jan 11, 2023


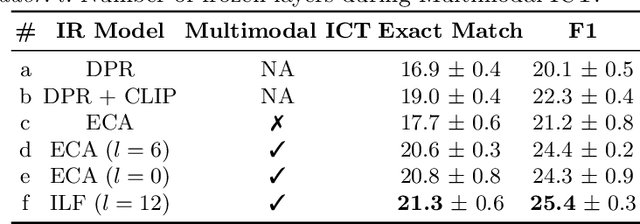
We present a new pre-training method, Multimodal Inverse Cloze Task, for Knowledge-based Visual Question Answering about named Entities (KVQAE). KVQAE is a recently introduced task that consists in answering questions about named entities grounded in a visual context using a Knowledge Base. Therefore, the interaction between the modalities is paramount to retrieve information and must be captured with complex fusion models. As these models require a lot of training data, we design this pre-training task from existing work in textual Question Answering. It consists in considering a sentence as a pseudo-question and its context as a pseudo-relevant passage and is extended by considering images near texts in multimodal documents. Our method is applicable to different neural network architectures and leads to a 9% relative-MRR and 15% relative-F1 gain for retrieval and reading comprehension, respectively, over a no-pre-training baseline.
Using Distributional Principles for the Semantic Study of Contextual Language Models
Nov 23, 2021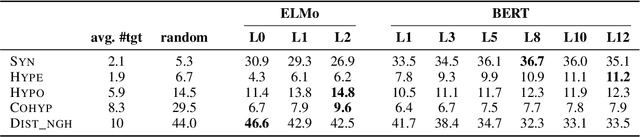
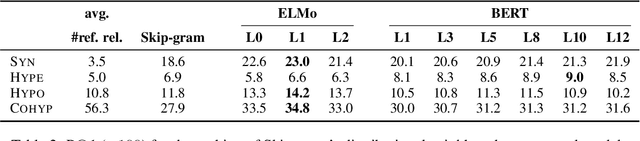
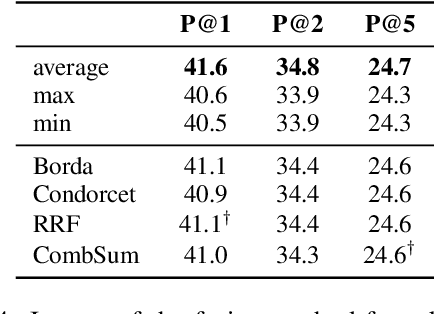
Many studies were recently done for investigating the properties of contextual language models but surprisingly, only a few of them consider the properties of these models in terms of semantic similarity. In this article, we first focus on these properties for English by exploiting the distributional principle of substitution as a probing mechanism in the controlled context of SemCor and WordNet paradigmatic relations. Then, we propose to adapt the same method to a more open setting for characterizing the differences between static and contextual language models.
Multimodal Entity Linking for Tweets
Apr 07, 2021

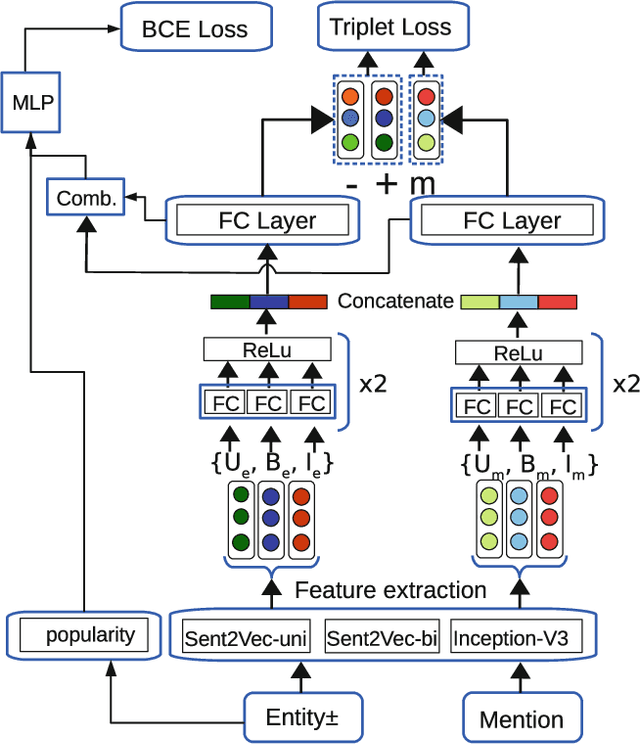

In many information extraction applications, entity linking (EL) has emerged as a crucial task that allows leveraging information about named entities from a knowledge base. In this paper, we address the task of multimodal entity linking (MEL), an emerging research field in which textual and visual information is used to map an ambiguous mention to an entity in a knowledge base (KB). First, we propose a method for building a fully annotated Twitter dataset for MEL, where entities are defined in a Twitter KB. Then, we propose a model for jointly learning a representation of both mentions and entities from their textual and visual contexts. We demonstrate the effectiveness of the proposed model by evaluating it on the proposed dataset and highlight the importance of leveraging visual information when it is available.