 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEbisu: Benchmarking Large Language Models in Japanese Finance
Feb 01, 2026Japanese finance combines agglutinative, head-final linguistic structure, mixed writing systems, and high-context communication norms that rely on indirect expression and implicit commitment, posing a substantial challenge for LLMs. We introduce Ebisu, a benchmark for native Japanese financial language understanding, comprising two linguistically and culturally grounded, expert-annotated tasks: JF-ICR, which evaluates implicit commitment and refusal recognition in investor-facing Q&A, and JF-TE, which assesses hierarchical extraction and ranking of nested financial terminology from professional disclosures. We evaluate a diverse set of open-source and proprietary LLMs spanning general-purpose, Japanese-adapted, and financial models. Results show that even state-of-the-art systems struggle on both tasks. While increased model scale yields limited improvements, language- and domain-specific adaptation does not reliably improve performance, leaving substantial gaps unresolved. Ebisu provides a focused benchmark for advancing linguistically and culturally grounded financial NLP. All datasets and evaluation scripts are publicly released.
All That Glisters Is Not Gold: A Benchmark for Reference-Free Counterfactual Financial Misinformation Detection
Jan 08, 2026We introduce RFC Bench, a benchmark for evaluating large language models on financial misinformation under realistic news. RFC Bench operates at the paragraph level and captures the contextual complexity of financial news where meaning emerges from dispersed cues. The benchmark defines two complementary tasks: reference free misinformation detection and comparison based diagnosis using paired original perturbed inputs. Experiments reveal a consistent pattern: performance is substantially stronger when comparative context is available, while reference free settings expose significant weaknesses, including unstable predictions and elevated invalid outputs. These results indicate that current models struggle to maintain coherent belief states without external grounding. By highlighting this gap, RFC Bench provides a structured testbed for studying reference free reasoning and advancing more reliable financial misinformation detection in real world settings.
CharacterBERT: Reconciling ELMo and BERT for Word-Level Open-Vocabulary Representations From Characters
Oct 31, 2020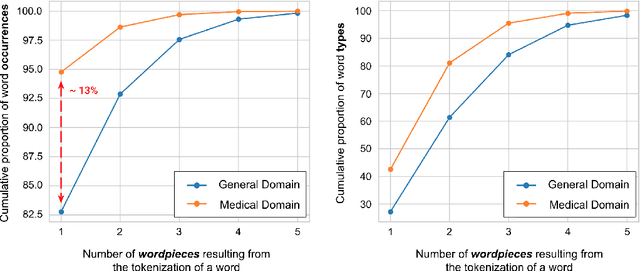

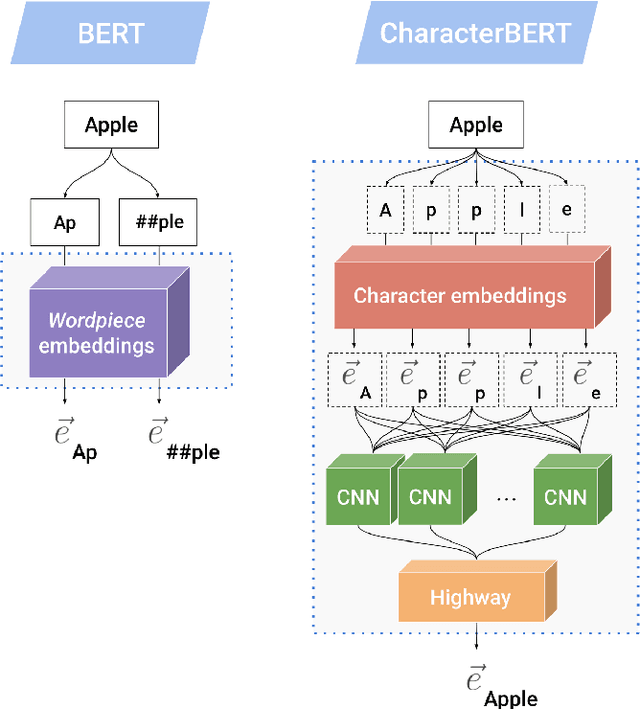
Due to the compelling improvements brought by BERT, many recent representation models adopted the Transformer architecture as their main building block, consequently inheriting the wordpiece tokenization system despite it not being intrinsically linked to the notion of Transformers. While this system is thought to achieve a good balance between the flexibility of characters and the efficiency of full words, using predefined wordpiece vocabularies from the general domain is not always suitable, especially when building models for specialized domains (e.g., the medical domain). Moreover, adopting a wordpiece tokenization shifts the focus from the word level to the subword level, making the models conceptually more complex and arguably less convenient in practice. For these reasons, we propose CharacterBERT, a new variant of BERT that drops the wordpiece system altogether and uses a Character-CNN module instead to represent entire words by consulting their characters. We show that this new model improves the performance of BERT on a variety of medical domain tasks while at the same time producing robust, word-level and open-vocabulary representations.
Transfer Fine-Tuning: A BERT Case Study
Sep 03, 2019

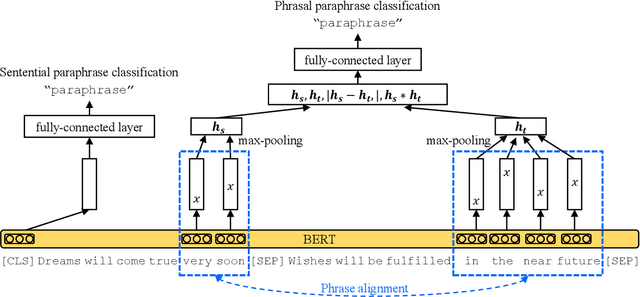

A semantic equivalence assessment is defined as a task that assesses semantic equivalence in a sentence pair by binary judgment (i.e., paraphrase identification) or grading (i.e., semantic textual similarity measurement). It constitutes a set of tasks crucial for research on natural language understanding. Recently, BERT realized a breakthrough in sentence representation learning (Devlin et al., 2019), which is broadly transferable to various NLP tasks. While BERT's performance improves by increasing its model size, the required computational power is an obstacle preventing practical applications from adopting the technology. Herein, we propose to inject phrasal paraphrase relations into BERT in order to generate suitable representations for semantic equivalence assessment instead of increasing the model size. Experiments on standard natural language understanding tasks confirm that our method effectively improves a smaller BERT model while maintaining the model size. The generated model exhibits superior performance compared to a larger BERT model on semantic equivalence assessment tasks. Furthermore, it achieves larger performance gains on tasks with limited training datasets for fine-tuning, which is a property desirable for transfer learning.