 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Syntax-aware Language Modeling through Dependency Tree Conversion
Apr 19, 2022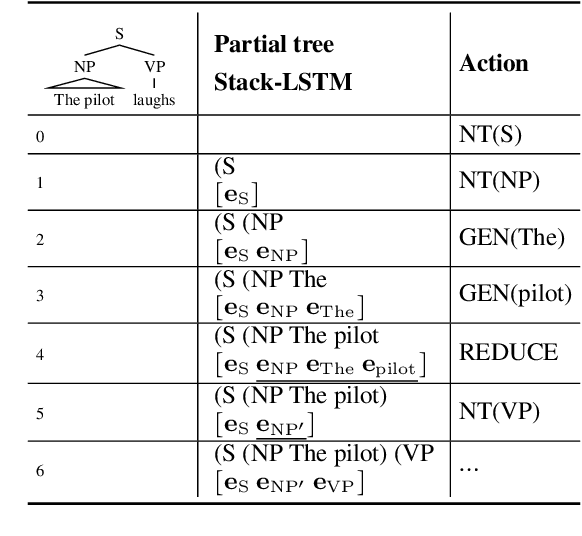
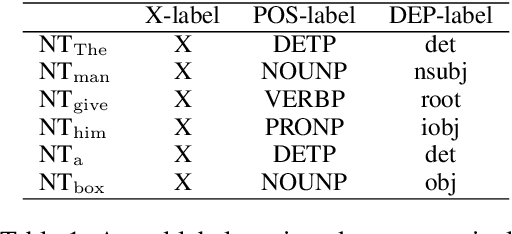
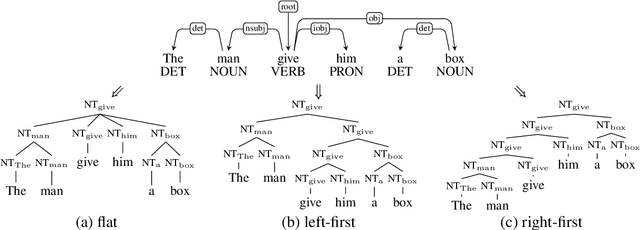
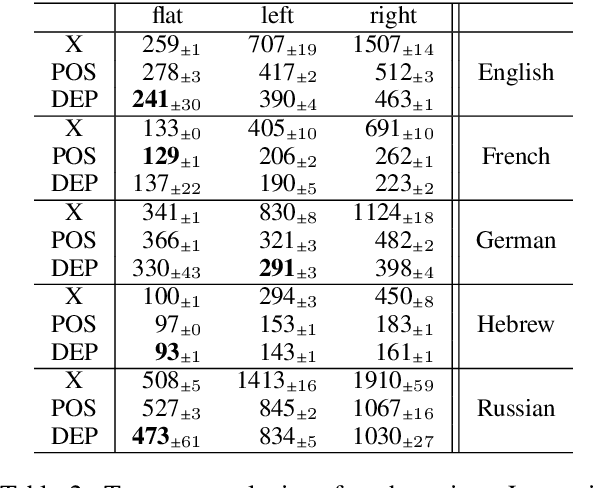
Incorporating stronger syntactic biases into neural language models (LMs) is a long-standing goal, but research in this area often focuses on modeling English text, where constituent treebanks are readily available. Extending constituent tree-based LMs to the multilingual setting, where dependency treebanks are more common, is possible via dependency-to-constituency conversion methods. However, this raises the question of which tree formats are best for learning the model, and for which languages. We investigate this question by training recurrent neural network grammars (RNNGs) using various conversion methods, and evaluating them empirically in a multilingual setting. We examine the effect on LM performance across nine conversion methods and five languages through seven types of syntactic tests. On average, the performance of our best model represents a 19 \% increase in accuracy over the worst choice across all languages. Our best model shows the advantage over sequential/overparameterized LMs, suggesting the positive effect of syntax injection in a multilingual setting. Our experiments highlight the importance of choosing the right tree formalism, and provide insights into making an informed decision.
Modeling Human Sentence Processing with Left-Corner Recurrent Neural Network Grammars
Sep 10, 2021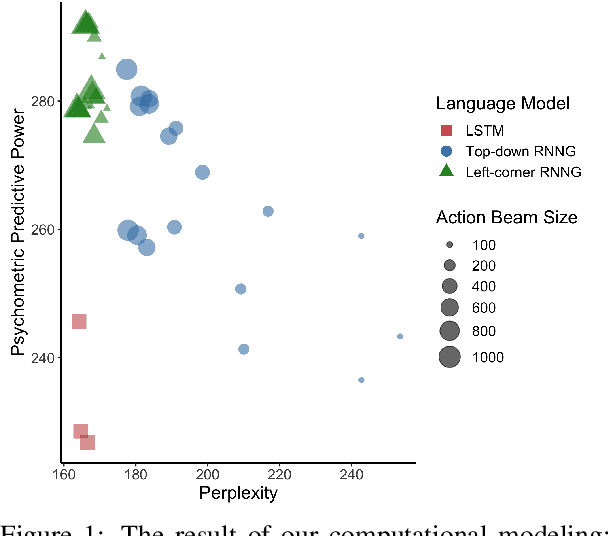
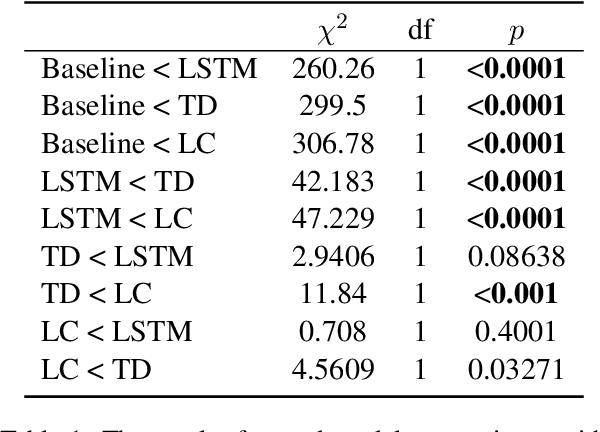
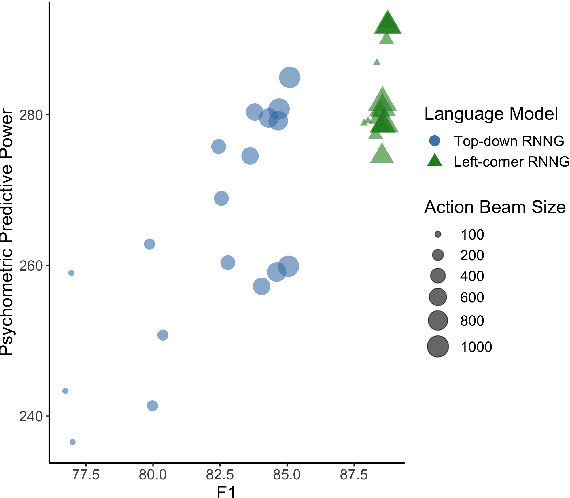

In computational linguistics, it has been shown that hierarchical structures make language models (LMs) more human-like. However, the previous literature has been agnostic about a parsing strategy of the hierarchical models. In this paper, we investigated whether hierarchical structures make LMs more human-like, and if so, which parsing strategy is most cognitively plausible. In order to address this question, we evaluated three LMs against human reading times in Japanese with head-final left-branching structures: Long Short-Term Memory (LSTM) as a sequential model and Recurrent Neural Network Grammars (RNNGs) with top-down and left-corner parsing strategies as hierarchical models. Our computational modeling demonstrated that left-corner RNNGs outperformed top-down RNNGs and LSTM, suggesting that hierarchical and left-corner architectures are more cognitively plausible than top-down or sequential architectures. In addition, the relationships between the cognitive plausibility and (i) perplexity, (ii) parsing, and (iii) beam size will also be discussed.
Effective Batching for Recurrent Neural Network Grammars
May 31, 2021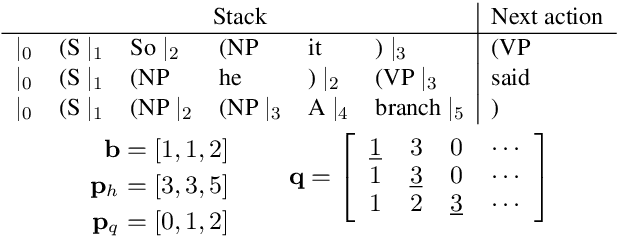
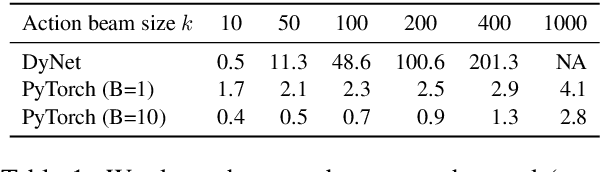
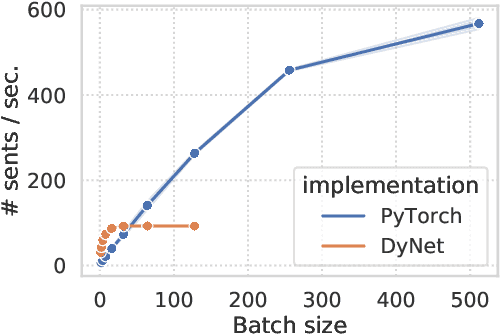
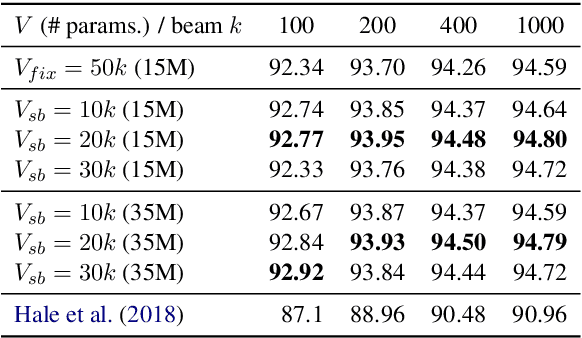
As a language model that integrates traditional symbolic operations and flexible neural representations, recurrent neural network grammars (RNNGs) have attracted great attention from both scientific and engineering perspectives. However, RNNGs are known to be harder to scale due to the difficulty of batched training. In this paper, we propose effective batching for RNNGs, where every operation is computed in parallel with tensors across multiple sentences. Our PyTorch implementation effectively employs a GPU and achieves x6 speedup compared to the existing C++ DyNet implementation with model-independent auto-batching. Moreover, our batched RNNG also accelerates inference and achieves x20-150 speedup for beam search depending on beam sizes. Finally, we evaluate syntactic generalization performance of the scaled RNNG against the LSTM baseline, based on the large training data of 100M tokens from English Wikipedia and the broad-coverage targeted syntactic evaluation benchmark. Our RNNG implementation is available at https://github.com/aistairc/rnng-pytorch/.
CharacterBERT: Reconciling ELMo and BERT for Word-Level Open-Vocabulary Representations From Characters
Oct 31, 2020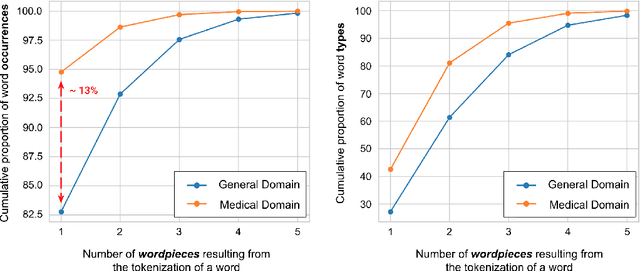

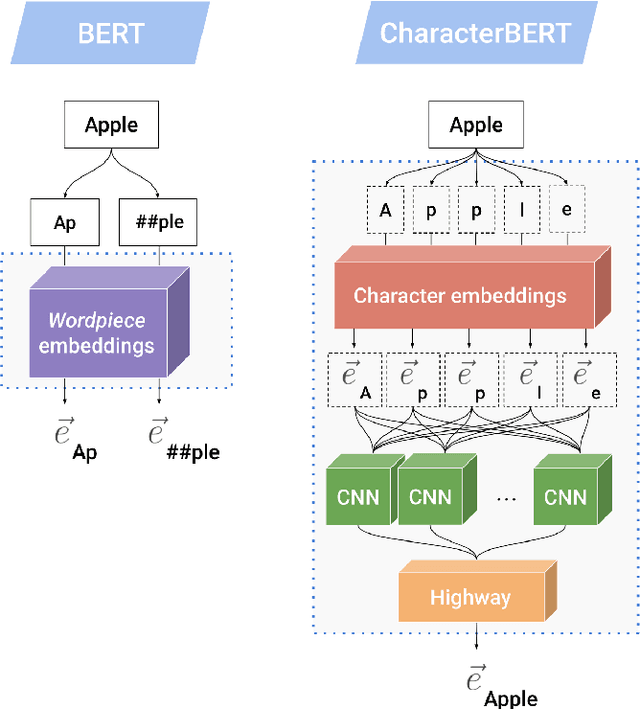
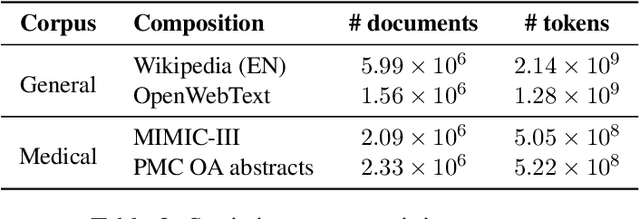
Due to the compelling improvements brought by BERT, many recent representation models adopted the Transformer architecture as their main building block, consequently inheriting the wordpiece tokenization system despite it not being intrinsically linked to the notion of Transformers. While this system is thought to achieve a good balance between the flexibility of characters and the efficiency of full words, using predefined wordpiece vocabularies from the general domain is not always suitable, especially when building models for specialized domains (e.g., the medical domain). Moreover, adopting a wordpiece tokenization shifts the focus from the word level to the subword level, making the models conceptually more complex and arguably less convenient in practice. For these reasons, we propose CharacterBERT, a new variant of BERT that drops the wordpiece system altogether and uses a Character-CNN module instead to represent entire words by consulting their characters. We show that this new model improves the performance of BERT on a variety of medical domain tasks while at the same time producing robust, word-level and open-vocabulary representations.
An analysis of the utility of explicit negative examples to improve the syntactic abilities of neural language models
Apr 06, 2020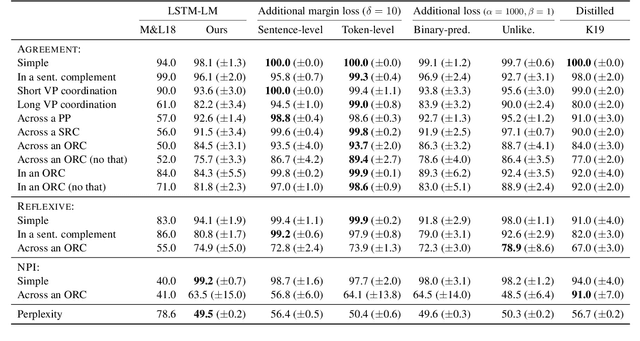
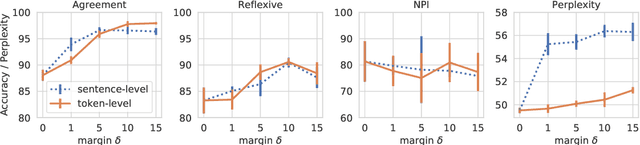
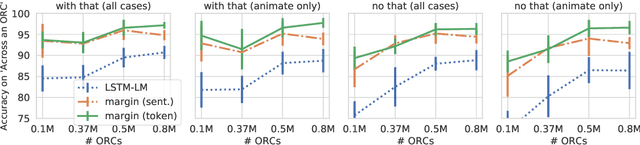

We explore the utilities of explicit negative examples in training neural language models. Negative examples here are incorrect words in a sentence, such as "barks" in "*The dogs barks". Neural language models are commonly trained only on positive examples, a set of sentences in the training data, but recent studies suggest that the models trained in this way are not capable of robustly handling complex syntactic constructions, such as long-distance agreement. In this paper, using English data, we first demonstrate that appropriately using negative examples about particular constructions (e.g., subject-verb agreement) will boost the model's robustness on them, with a negligible loss of perplexity. The key to our success is an additional margin loss between the log-likelihoods of a correct word and an incorrect word. We then provide a detailed analysis of the trained models. One of our findings is the difficulty of object-relative clauses for RNNs. We find that even with our direct learning signals the models still suffer from resolving agreement across an object-relative clause. Augmentation of training sentences involving the constructions somewhat helps, but the accuracy still does not reach the level of subject-relative clauses. Although not directly cognitively appealing, our method can be a tool to analyze the true architectural limitation of neural models on challenging linguistic constructions.
Learning to Select, Track, and Generate for Data-to-Text
Jul 23, 2019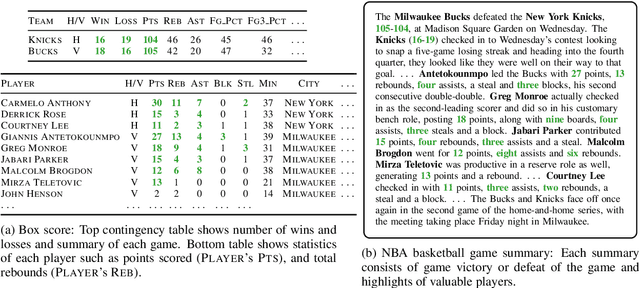

We propose a data-to-text generation model with two modules, one for tracking and the other for text generation. Our tracking module selects and keeps track of salient information and memorizes which record has been mentioned. Our generation module generates a summary conditioned on the state of tracking module. Our model is considered to simulate the human-like writing process that gradually selects the information by determining the intermediate variables while writing the summary. In addition, we also explore the effectiveness of the writer information for generation. Experimental results show that our model outperforms existing models in all evaluation metrics even without writer information. Incorporating writer information further improves the performance, contributing to content planning and surface realization.
Automatic Generation of High Quality CCGbanks for Parser Domain Adaptation
Jun 05, 2019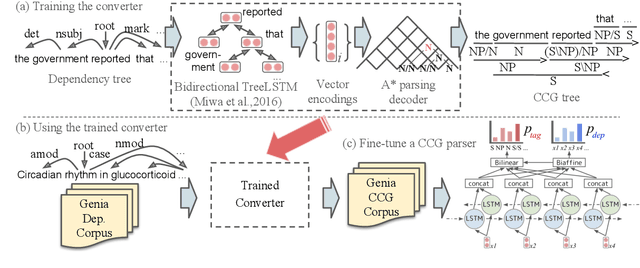
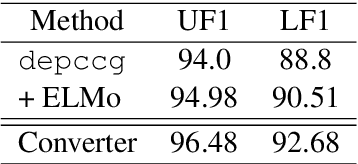

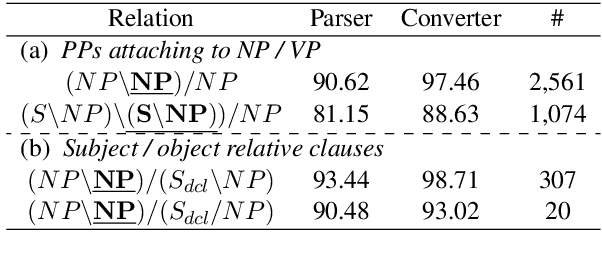
We propose a new domain adaptation method for Combinatory Categorial Grammar (CCG) parsing, based on the idea of automatic generation of CCG corpora exploiting cheaper resources of dependency trees. Our solution is conceptually simple, and not relying on a specific parser architecture, making it applicable to the current best-performing parsers. We conduct extensive parsing experiments with detailed discussion; on top of existing benchmark datasets on (1) biomedical texts and (2) question sentences, we create experimental datasets of (3) speech conversation and (4) math problems. When applied to the proposed method, an off-the-shelf CCG parser shows significant performance gains, improving from 90.7% to 96.6% on speech conversation, and from 88.5% to 96.8% on math problems.
Combining Axiom Injection and Knowledge Base Completion for Efficient Natural Language Inference
Nov 15, 2018



In logic-based approaches to reasoning tasks such as Recognizing Textual Entailment (RTE), it is important for a system to have a large amount of knowledge data. However, there is a tradeoff between adding more knowledge data for improved RTE performance and maintaining an efficient RTE system, as such a big database is problematic in terms of the memory usage and computational complexity. In this work, we show the processing time of a state-of-the-art logic-based RTE system can be significantly reduced by replacing its search-based axiom injection (abduction) mechanism by that based on Knowledge Base Completion (KBC). We integrate this mechanism in a Coq plugin that provides a proof automation tactic for natural language inference. Additionally, we show empirically that adding new knowledge data contributes to better RTE performance while not harming the processing speed in this framework.
Consistent CCG Parsing over Multiple Sentences for Improved Logical Reasoning
Apr 19, 2018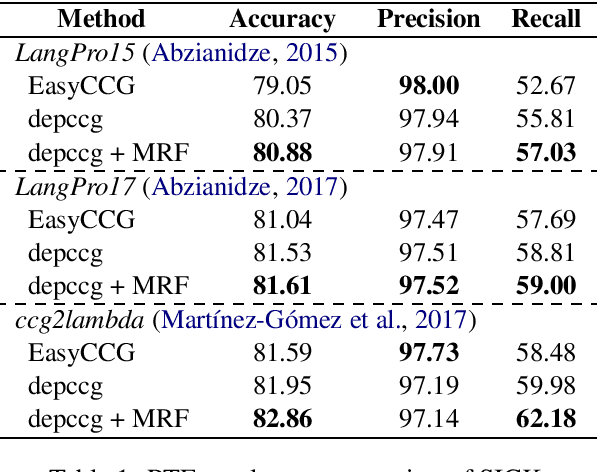
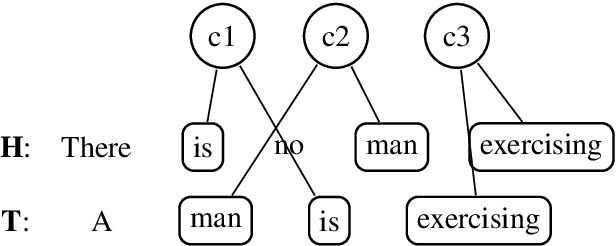

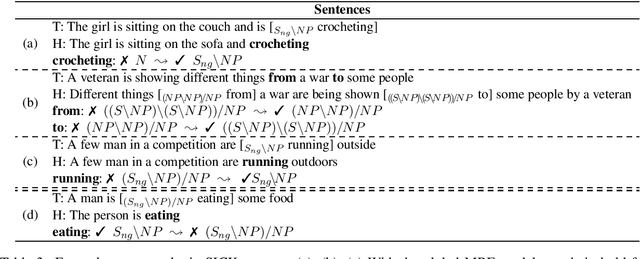
In formal logic-based approaches to Recognizing Textual Entailment (RTE), a Combinatory Categorial Grammar (CCG) parser is used to parse input premises and hypotheses to obtain their logical formulas. Here, it is important that the parser processes the sentences consistently; failing to recognize a similar syntactic structure results in inconsistent predicate argument structures among them, in which case the succeeding theorem proving is doomed to failure. In this work, we present a simple method to extend an existing CCG parser to parse a set of sentences consistently, which is achieved with an inter-sentence modeling with Markov Random Fields (MRF). When combined with existing logic-based systems, our method always shows improvement in the RTE experiments on English and Japanese languages.
A* CCG Parsing with a Supertag and Dependency Factored Model
Apr 23, 2017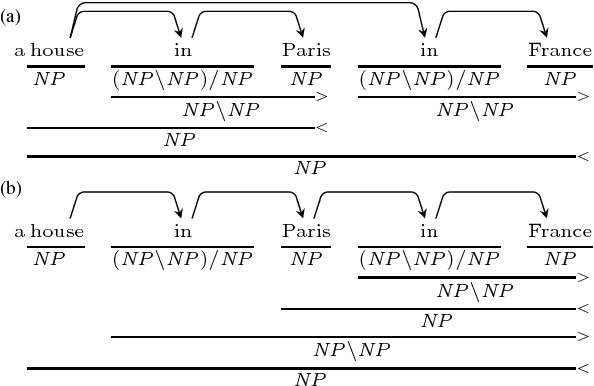
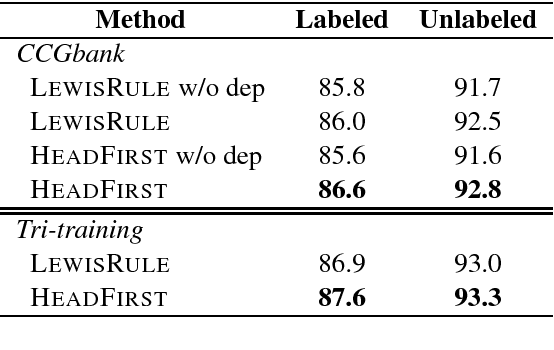
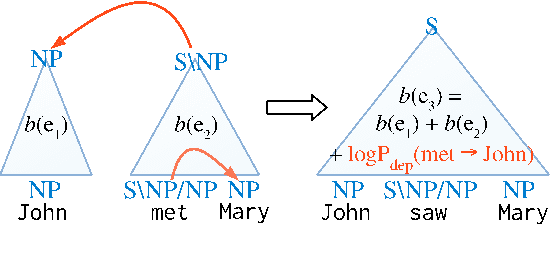
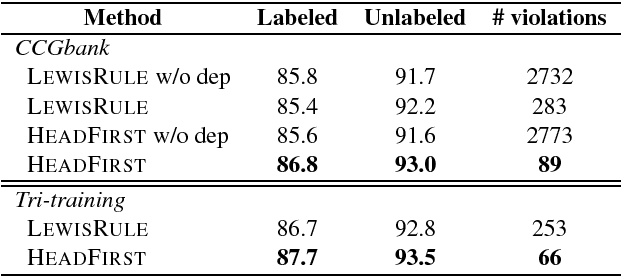
We propose a new A* CCG parsing model in which the probability of a tree is decomposed into factors of CCG categories and its syntactic dependencies both defined on bi-directional LSTMs. Our factored model allows the precomputation of all probabilities and runs very efficiently, while modeling sentence structures explicitly via dependencies. Our model achieves the state-of-the-art results on English and Japanese CCG parsing.