 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Batching for Recurrent Neural Network Grammars
Paper and Code
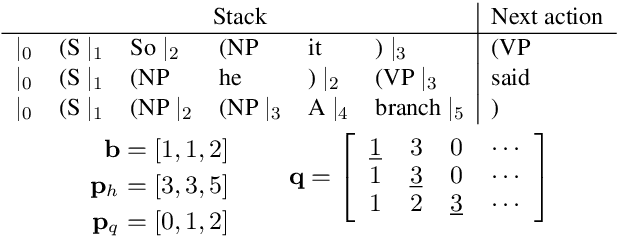
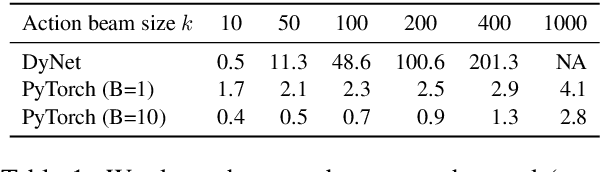
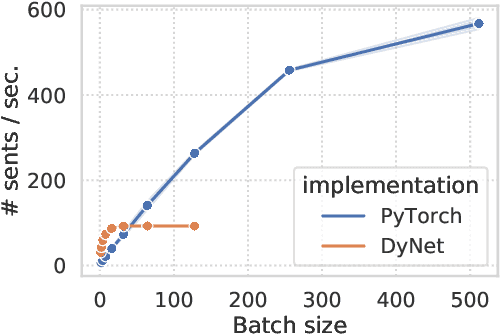
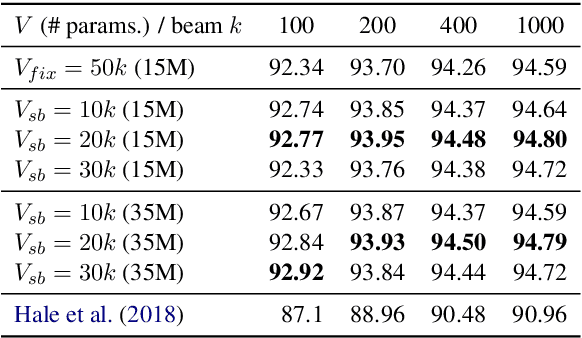
As a language model that integrates traditional symbolic operations and flexible neural representations, recurrent neural network grammars (RNNGs) have attracted great attention from both scientific and engineering perspectives. However, RNNGs are known to be harder to scale due to the difficulty of batched training. In this paper, we propose effective batching for RNNGs, where every operation is computed in parallel with tensors across multiple sentences. Our PyTorch implementation effectively employs a GPU and achieves x6 speedup compared to the existing C++ DyNet implementation with model-independent auto-batching. Moreover, our batched RNNG also accelerates inference and achieves x20-150 speedup for beam search depending on beam sizes. Finally, we evaluate syntactic generalization performance of the scaled RNNG against the LSTM baseline, based on the large training data of 100M tokens from English Wikipedia and the broad-coverage targeted syntactic evaluation benchmark. Our RNNG implementation is available at https://github.com/aistairc/rnng-pytorch/.