 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Investigation of Neural Symbolic Reasoning Strategies
Feb 16, 2023Neural reasoning accuracy improves when generating intermediate reasoning steps. However, the source of this improvement is yet unclear. Here, we investigate and factorize the benefit of generating intermediate steps for symbolic reasoning. Specifically, we decompose the reasoning strategy w.r.t. step granularity and chaining strategy. With a purely symbolic numerical reasoning dataset (e.g., A=1, B=3, C=A+3, C?), we found that the choice of reasoning strategies significantly affects the performance, with the gap becoming even larger as the extrapolation length becomes longer. Surprisingly, we also found that certain configurations lead to nearly perfect performance, even in the case of length extrapolation. Our results indicate the importance of further exploring effective strategies for neural reasoning models.
Do Deep Neural Networks Capture Compositionality in Arithmetic Reasoning?
Feb 15, 2023Compositionality is a pivotal property of symbolic reasoning. However, how well recent neural models capture compositionality remains underexplored in the symbolic reasoning tasks. This study empirically addresses this question by systematically examining recently published pre-trained seq2seq models with a carefully controlled dataset of multi-hop arithmetic symbolic reasoning. We introduce a skill tree on compositionality in arithmetic symbolic reasoning that defines the hierarchical levels of complexity along with three compositionality dimensions: systematicity, productivity, and substitutivity. Our experiments revealed that among the three types of composition, the models struggled most with systematicity, performing poorly even with relatively simple compositions. That difficulty was not resolved even after training the models with intermediate reasoning steps.
Tracing and Manipulating Intermediate Values in Neural Math Problem Solvers
Jan 17, 2023How language models process complex input that requires multiple steps of inference is not well understood. Previous research has shown that information about intermediate values of these inputs can be extracted from the activations of the models, but it is unclear where that information is encoded and whether that information is indeed used during inference. We introduce a method for analyzing how a Transformer model processes these inputs by focusing on simple arithmetic problems and their intermediate values. To trace where information about intermediate values is encoded, we measure the correlation between intermediate values and the activations of the model using principal component analysis (PCA). Then, we perform a causal intervention by manipulating model weights. This intervention shows that the weights identified via tracing are not merely correlated with intermediate values, but causally related to model predictions. Our findings show that the model has a locality to certain intermediate values, and this is useful for enhancing the interpretability of the models.
Instance-Based Neural Dependency Parsing
Sep 28, 2021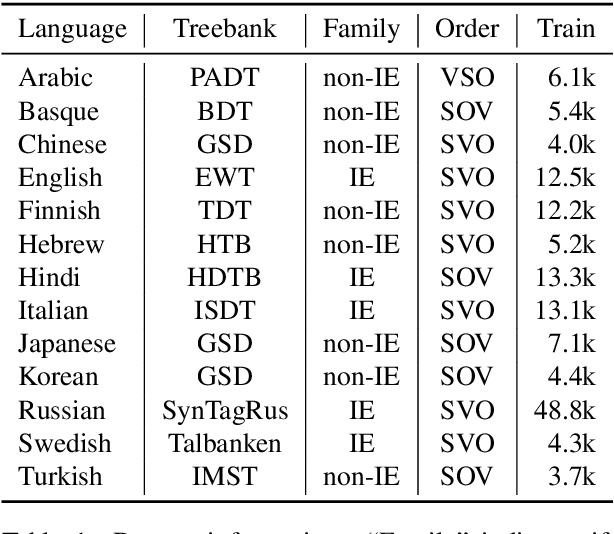
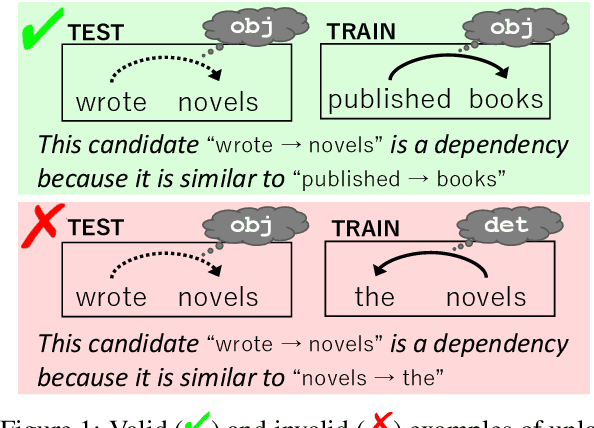

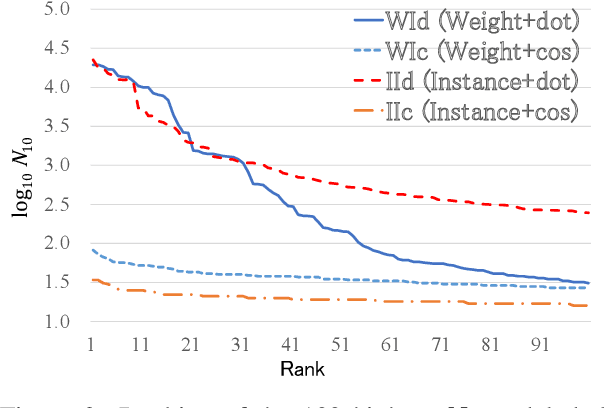
Interpretable rationales for model predictions are crucial in practical applications. We develop neural models that possess an interpretable inference process for dependency parsing. Our models adopt instance-based inference, where dependency edges are extracted and labeled by comparing them to edges in a training set. The training edges are explicitly used for the predictions; thus, it is easy to grasp the contribution of each edge to the predictions. Our experiments show that our instance-based models achieve competitive accuracy with standard neural models and have the reasonable plausibility of instance-based explanations.
Multimodal Logical Inference System for Visual-Textual Entailment
Jun 10, 2019
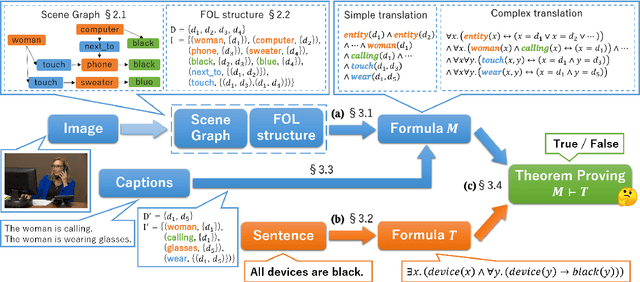


A large amount of research about multimodal inference across text and vision has been recently developed to obtain visually grounded word and sentence representations. In this paper, we use logic-based representations as unified meaning representations for texts and images and present an unsupervised multimodal logical inference system that can effectively prove entailment relations between them. We show that by combining semantic parsing and theorem proving, the system can handle semantically complex sentences for visual-textual inference.
Automatic Generation of High Quality CCGbanks for Parser Domain Adaptation
Jun 05, 2019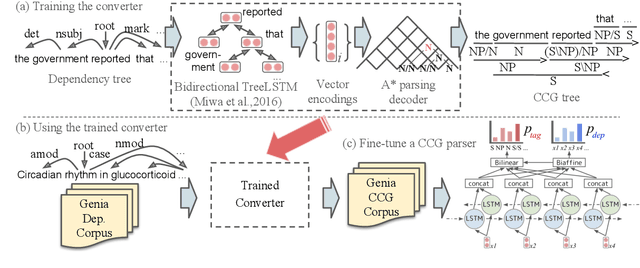
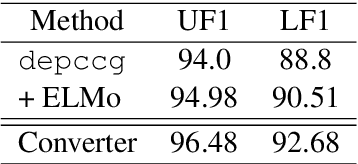

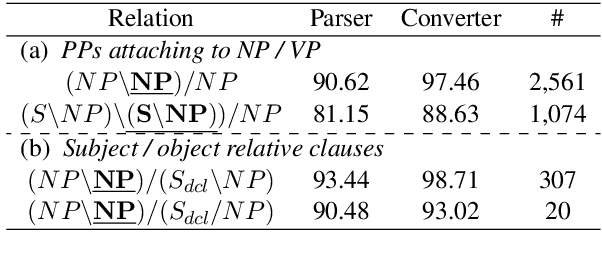
We propose a new domain adaptation method for Combinatory Categorial Grammar (CCG) parsing, based on the idea of automatic generation of CCG corpora exploiting cheaper resources of dependency trees. Our solution is conceptually simple, and not relying on a specific parser architecture, making it applicable to the current best-performing parsers. We conduct extensive parsing experiments with detailed discussion; on top of existing benchmark datasets on (1) biomedical texts and (2) question sentences, we create experimental datasets of (3) speech conversation and (4) math problems. When applied to the proposed method, an off-the-shelf CCG parser shows significant performance gains, improving from 90.7% to 96.6% on speech conversation, and from 88.5% to 96.8% on math problems.
Combining Axiom Injection and Knowledge Base Completion for Efficient Natural Language Inference
Nov 15, 2018



In logic-based approaches to reasoning tasks such as Recognizing Textual Entailment (RTE), it is important for a system to have a large amount of knowledge data. However, there is a tradeoff between adding more knowledge data for improved RTE performance and maintaining an efficient RTE system, as such a big database is problematic in terms of the memory usage and computational complexity. In this work, we show the processing time of a state-of-the-art logic-based RTE system can be significantly reduced by replacing its search-based axiom injection (abduction) mechanism by that based on Knowledge Base Completion (KBC). We integrate this mechanism in a Coq plugin that provides a proof automation tactic for natural language inference. Additionally, we show empirically that adding new knowledge data contributes to better RTE performance while not harming the processing speed in this framework.
Consistent CCG Parsing over Multiple Sentences for Improved Logical Reasoning
Apr 19, 2018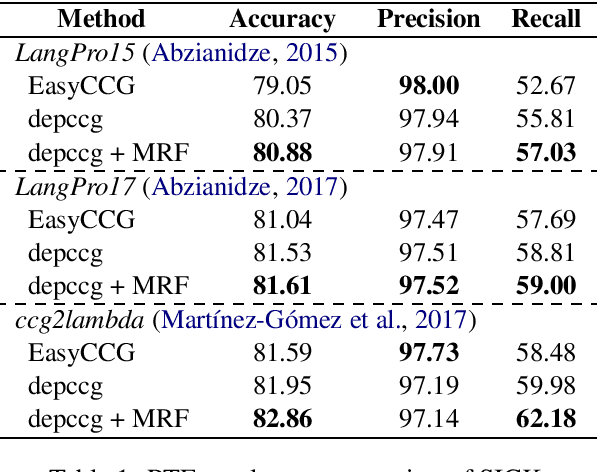
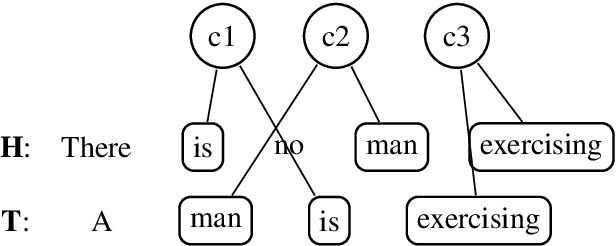

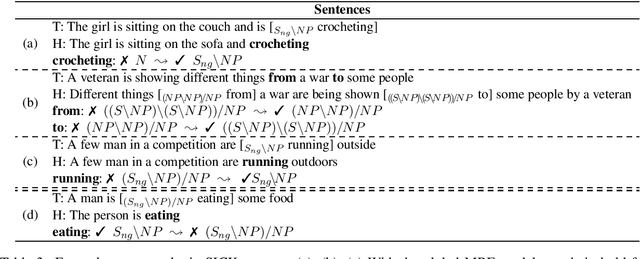
In formal logic-based approaches to Recognizing Textual Entailment (RTE), a Combinatory Categorial Grammar (CCG) parser is used to parse input premises and hypotheses to obtain their logical formulas. Here, it is important that the parser processes the sentences consistently; failing to recognize a similar syntactic structure results in inconsistent predicate argument structures among them, in which case the succeeding theorem proving is doomed to failure. In this work, we present a simple method to extend an existing CCG parser to parse a set of sentences consistently, which is achieved with an inter-sentence modeling with Markov Random Fields (MRF). When combined with existing logic-based systems, our method always shows improvement in the RTE experiments on English and Japanese languages.
A* CCG Parsing with a Supertag and Dependency Factored Model
Apr 23, 2017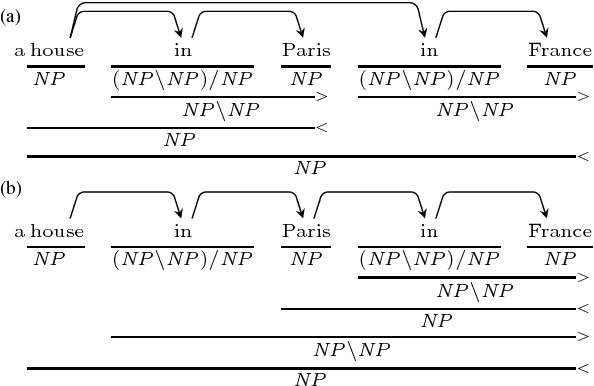
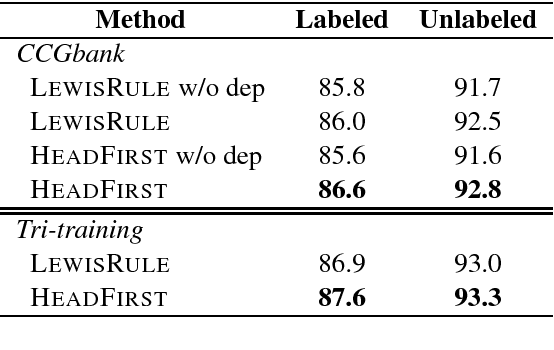
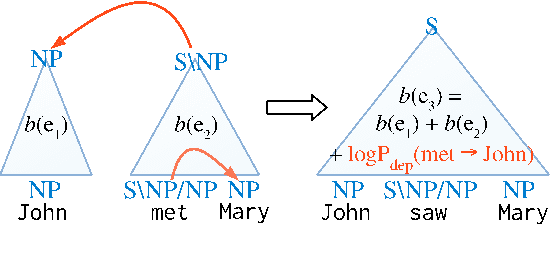
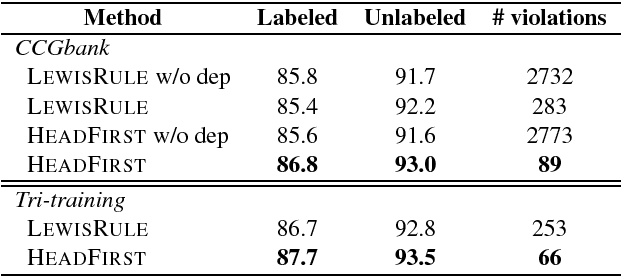
We propose a new A* CCG parsing model in which the probability of a tree is decomposed into factors of CCG categories and its syntactic dependencies both defined on bi-directional LSTMs. Our factored model allows the precomputation of all probabilities and runs very efficiently, while modeling sentence structures explicitly via dependencies. Our model achieves the state-of-the-art results on English and Japanese CCG parsing.