 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormative Reasoning in Large Language Models: A Comparative Benchmark from Logical and Modal Perspectives
Oct 30, 2025



Normative reasoning is a type of reasoning that involves normative or deontic modality, such as obligation and permission. While large language models (LLMs) have demonstrated remarkable performance across various reasoning tasks, their ability to handle normative reasoning remains underexplored. In this paper, we systematically evaluate LLMs' reasoning capabilities in the normative domain from both logical and modal perspectives. Specifically, to assess how well LLMs reason with normative modals, we make a comparison between their reasoning with normative modals and their reasoning with epistemic modals, which share a common formal structure. To this end, we introduce a new dataset covering a wide range of formal patterns of reasoning in both normative and epistemic domains, while also incorporating non-formal cognitive factors that influence human reasoning. Our results indicate that, although LLMs generally adhere to valid reasoning patterns, they exhibit notable inconsistencies in specific types of normative reasoning and display cognitive biases similar to those observed in psychological studies of human reasoning. These findings highlight challenges in achieving logical consistency in LLMs' normative reasoning and provide insights for enhancing their reliability. All data and code are released publicly at https://github.com/kmineshima/NeuBAROCO.
Exploring Reasoning Biases in Large Language Models Through Syllogism: Insights from the NeuBAROCO Dataset
Aug 08, 2024



This paper explores the question of how accurately current large language models can perform logical reasoning in natural language, with an emphasis on whether these models exhibit reasoning biases similar to humans. Specifically, our study focuses on syllogistic reasoning, a form of deductive reasoning extensively studied in cognitive science as a natural form of human reasoning. We present a syllogism dataset called NeuBAROCO, which consists of syllogistic reasoning problems in English and Japanese. This dataset was originally designed for psychological experiments to assess human reasoning capabilities using various forms of syllogisms. Our experiments with leading large language models indicate that these models exhibit reasoning biases similar to humans, along with other error tendencies. Notably, there is significant room for improvement in reasoning problems where the relationship between premises and hypotheses is neither entailment nor contradiction. We also present experimental results and in-depth analysis using a new Chain-of-Thought prompting method, which asks LLMs to translate syllogisms into abstract logical expressions and then explain their reasoning process. Our analysis using this method suggests that the primary limitations of LLMs lie in the reasoning process itself rather than the interpretation of syllogisms.
Computational Semantics and Evaluation Benchmark for Interrogative Sentences via Combinatory Categorial Grammar
Dec 22, 2023



We present a compositional semantics for various types of polar questions and wh-questions within the framework of Combinatory Categorial Grammar (CCG). To assess the explanatory power of our proposed analysis, we introduce a question-answering dataset QSEM specifically designed to evaluate the semantics of interrogative sentences. We implement our analysis using existing CCG parsers and conduct evaluations using the dataset. Through the evaluation, we have obtained annotated data with CCG trees and semantic representations for about half of the samples included in QSEM. Furthermore, we discuss the discrepancy between the theoretical capacity of CCG and the capabilities of existing CCG parsers.
Evaluating Large Language Models with NeuBAROCO: Syllogistic Reasoning Ability and Human-like Biases
Jun 21, 2023



This paper investigates whether current large language models exhibit biases in logical reasoning, similar to humans. Specifically, we focus on syllogistic reasoning, a well-studied form of inference in the cognitive science of human deduction. To facilitate our analysis, we introduce a dataset called NeuBAROCO, originally designed for psychological experiments that assess human logical abilities in syllogistic reasoning. The dataset consists of syllogistic inferences in both English and Japanese. We examine three types of biases observed in human syllogistic reasoning: belief biases, conversion errors, and atmosphere effects. Our findings demonstrate that current large language models struggle more with problems involving these three types of biases.
Compositional Evaluation on Japanese Textual Entailment and Similarity
Aug 09, 2022
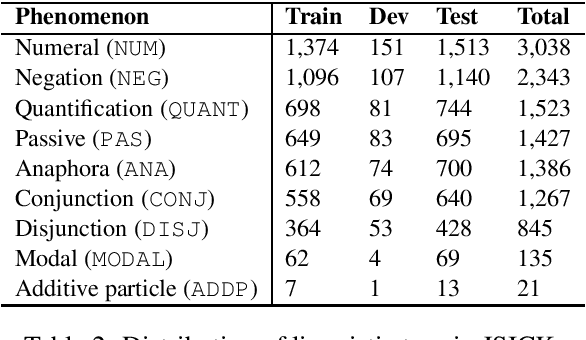
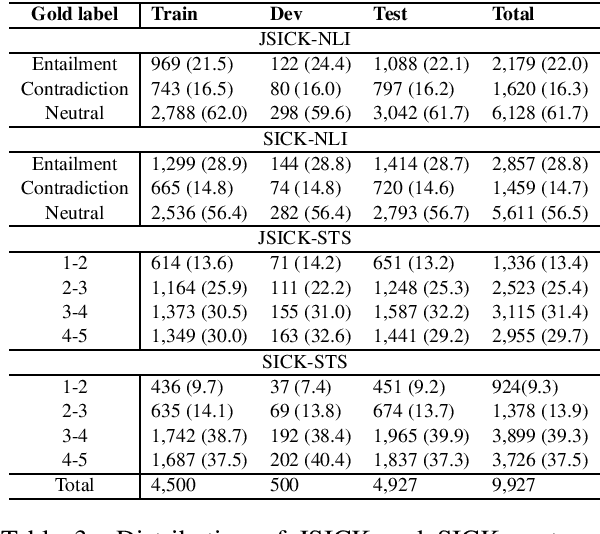
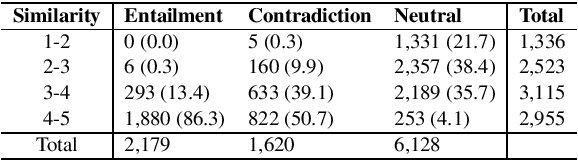
Natural Language Inference (NLI) and Semantic Textual Similarity (STS) are widely used benchmark tasks for compositional evaluation of pre-trained language models. Despite growing interest in linguistic universals, most NLI/STS studies have focused almost exclusively on English. In particular, there are no available multilingual NLI/STS datasets in Japanese, which is typologically different from English and can shed light on the currently controversial behavior of language models in matters such as sensitivity to word order and case particles. Against this background, we introduce JSICK, a Japanese NLI/STS dataset that was manually translated from the English dataset SICK. We also present a stress-test dataset for compositional inference, created by transforming syntactic structures of sentences in JSICK to investigate whether language models are sensitive to word order and case particles. We conduct baseline experiments on different pre-trained language models and compare the performance of multilingual models when applied to Japanese and other languages. The results of the stress-test experiments suggest that the current pre-trained language models are insensitive to word order and case marking.
Building a Video-and-Language Dataset with Human Actions for Multimodal Logical Inference
Jun 27, 2021



This paper introduces a new video-and-language dataset with human actions for multimodal logical inference, which focuses on intentional and aspectual expressions that describe dynamic human actions. The dataset consists of 200 videos, 5,554 action labels, and 1,942 action triplets of the form <subject, predicate, object> that can be translated into logical semantic representations. The dataset is expected to be useful for evaluating multimodal inference systems between videos and semantically complicated sentences including negation and quantification.
SyGNS: A Systematic Generalization Testbed Based on Natural Language Semantics
Jun 02, 2021
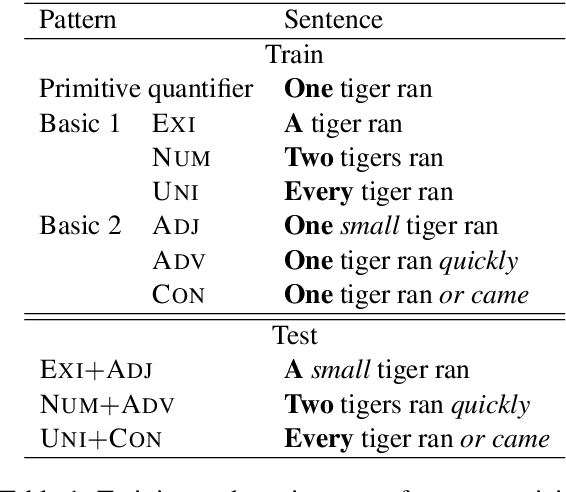
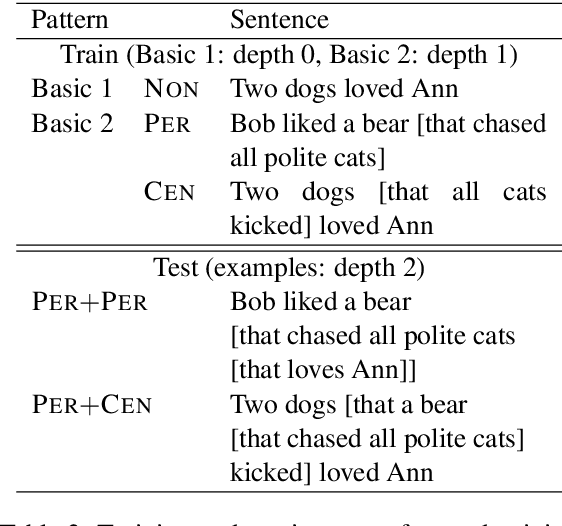
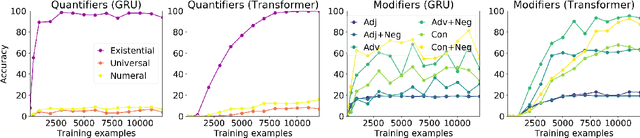
Recently, deep neural networks (DNNs) have achieved great success in semantically challenging NLP tasks, yet it remains unclear whether DNN models can capture compositional meanings, those aspects of meaning that have been long studied in formal semantics. To investigate this issue, we propose a Systematic Generalization testbed based on Natural language Semantics (SyGNS), whose challenge is to map natural language sentences to multiple forms of scoped meaning representations, designed to account for various semantic phenomena. Using SyGNS, we test whether neural networks can systematically parse sentences involving novel combinations of logical expressions such as quantifiers and negation. Experiments show that Transformer and GRU models can generalize to unseen combinations of quantifiers, negations, and modifiers that are similar to given training instances in form, but not to the others. We also find that the generalization performance to unseen combinations is better when the form of meaning representations is simpler. The data and code for SyGNS are publicly available at https://github.com/verypluming/SyGNS.
Visual representation of negation: Real world data analysis on comic image design
May 21, 2021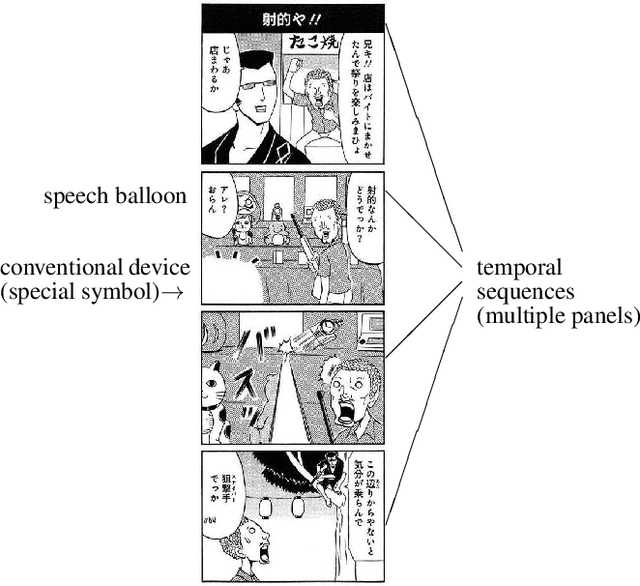

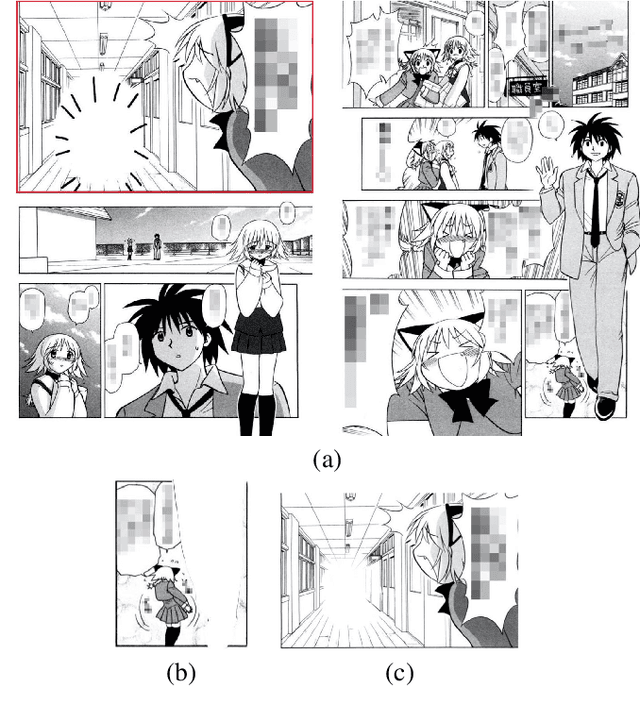

There has been a widely held view that visual representations (e.g., photographs and illustrations) do not depict negation, for example, one that can be expressed by a sentence "the train is not coming". This view is empirically challenged by analyzing the real-world visual representations of comic (manga) illustrations. In the experiment using image captioning tasks, we gave people comic illustrations and asked them to explain what they could read from them. The collected data showed that some comic illustrations could depict negation without any aid of sequences (multiple panels) or conventional devices (special symbols). This type of comic illustrations was subjected to further experiments, classifying images into those containing negation and those not containing negation. While this image classification was easy for humans, it was difficult for data-driven machines, i.e., deep learning models (CNN), to achieve the same high performance. Given the findings, we argue that some comic illustrations evoke background knowledge and thus can depict negation with purely visual elements.
Exploring Transitivity in Neural NLI Models through Veridicality
Jan 26, 2021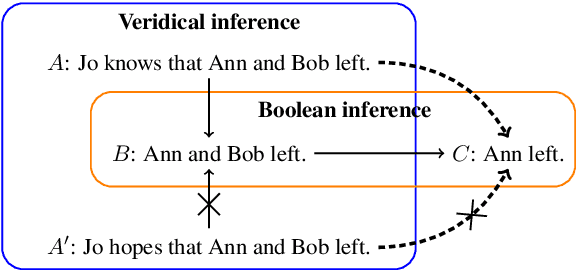


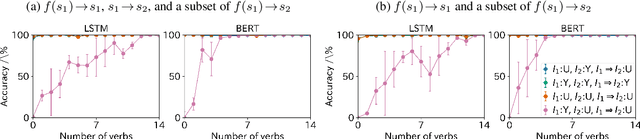
Despite the recent success of deep neural networks in natural language processing, the extent to which they can demonstrate human-like generalization capacities for natural language understanding remains unclear. We explore this issue in the domain of natural language inference (NLI), focusing on the transitivity of inference relations, a fundamental property for systematically drawing inferences. A model capturing transitivity can compose basic inference patterns and draw new inferences. We introduce an analysis method using synthetic and naturalistic NLI datasets involving clause-embedding verbs to evaluate whether models can perform transitivity inferences composed of veridical inferences and arbitrary inference types. We find that current NLI models do not perform consistently well on transitivity inference tasks, suggesting that they lack the generalization capacity for drawing composite inferences from provided training examples. The data and code for our analysis are publicly available at https://github.com/verypluming/transitivity.
Combining Event Semantics and Degree Semantics for Natural Language Inference
Nov 02, 2020


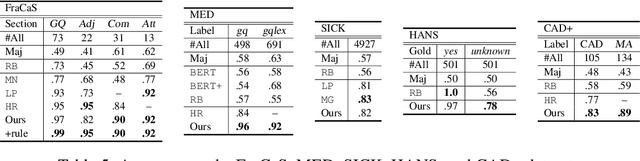
In formal semantics, there are two well-developed semantic frameworks: event semantics, which treats verbs and adverbial modifiers using the notion of event, and degree semantics, which analyzes adjectives and comparatives using the notion of degree. However, it is not obvious whether these frameworks can be combined to handle cases in which the phenomena in question are interacting with each other. Here, we study this issue by focusing on natural language inference (NLI). We implement a logic-based NLI system that combines event semantics and degree semantics and their interaction with lexical knowledge. We evaluate the system on various NLI datasets containing linguistically challenging problems. The results show that the system achieves high accuracies on these datasets in comparison with previous logic-based systems and deep-learning-based systems. This suggests that the two semantic frameworks can be combined consistently to handle various combinations of linguistic phenomena without compromising the advantage of either framework.