 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix and Relative Weak Crossover in Japanese: An Experimental Investigation
Oct 03, 2024



This paper provides evidence that weak crossover effects differ in nature between matrix and relative clauses. Fukushima et al. (2024) provided similar evidence, showing that, when various non-structural factors were eliminated English speakers never accepted matrix weak crossover cases, but often accepted relative weak crossover ones. Those results were limited, however, by English word order, which lead to uncertainty as to whether this difference was due to the effects of linear precedence or syntactic structure. In this paper, to distinguish between these two possibilities, we conduct an experiment using Japanese, which lacks the word-order confound that English had. We find results that are qualitatively in line with Fukushima et al. (2024) suggesting that the relevant distinction is structural and not based simply on precedence.
Is Japanese CCGBank empirically correct? A case study of passive and causative constructions
Feb 28, 2023

The Japanese CCGBank serves as training and evaluation data for developing Japanese CCG parsers. However, since it is automatically generated from the Kyoto Corpus, a dependency treebank, its linguistic validity still needs to be sufficiently verified. In this paper, we focus on the analysis of passive/causative constructions in the Japanese CCGBank and show that, together with the compositional semantics of ccg2lambda, a semantic parsing system, it yields empirically wrong predictions for the nested construction of passives and causatives.
Building a Video-and-Language Dataset with Human Actions for Multimodal Logical Inference
Jun 27, 2021



This paper introduces a new video-and-language dataset with human actions for multimodal logical inference, which focuses on intentional and aspectual expressions that describe dynamic human actions. The dataset consists of 200 videos, 5,554 action labels, and 1,942 action triplets of the form <subject, predicate, object> that can be translated into logical semantic representations. The dataset is expected to be useful for evaluating multimodal inference systems between videos and semantically complicated sentences including negation and quantification.
Combining Event Semantics and Degree Semantics for Natural Language Inference
Nov 02, 2020


In formal semantics, there are two well-developed semantic frameworks: event semantics, which treats verbs and adverbial modifiers using the notion of event, and degree semantics, which analyzes adjectives and comparatives using the notion of degree. However, it is not obvious whether these frameworks can be combined to handle cases in which the phenomena in question are interacting with each other. Here, we study this issue by focusing on natural language inference (NLI). We implement a logic-based NLI system that combines event semantics and degree semantics and their interaction with lexical knowledge. We evaluate the system on various NLI datasets containing linguistically challenging problems. The results show that the system achieves high accuracies on these datasets in comparison with previous logic-based systems and deep-learning-based systems. This suggests that the two semantic frameworks can be combined consistently to handle various combinations of linguistic phenomena without compromising the advantage of either framework.
Logical Inferences with Comparatives and Generalized Quantifiers
May 16, 2020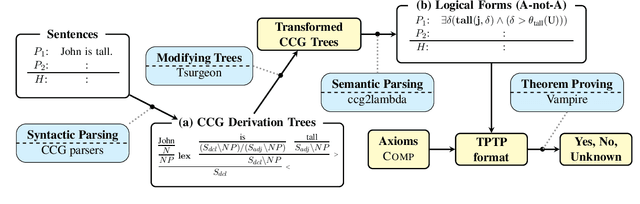



Comparative constructions pose a challenge in Natural Language Inference (NLI), which is the task of determining whether a text entails a hypothesis. Comparatives are structurally complex in that they interact with other linguistic phenomena such as quantifiers, numerals, and lexical antonyms. In formal semantics, there is a rich body of work on comparatives and gradable expressions using the notion of degree. However, a logical inference system for comparatives has not been sufficiently developed for use in the NLI task. In this paper, we present a compositional semantics that maps various comparative constructions in English to semantic representations via Combinatory Categorial Grammar (CCG) parsers and combine it with an inference system based on automated theorem proving. We evaluate our system on three NLI datasets that contain complex logical inferences with comparatives, generalized quantifiers, and numerals. We show that the system outperforms previous logic-based systems as well as recent deep learning-based models.
Do Neural Models Learn Systematicity of Monotonicity Inference in Natural Language?
May 02, 2020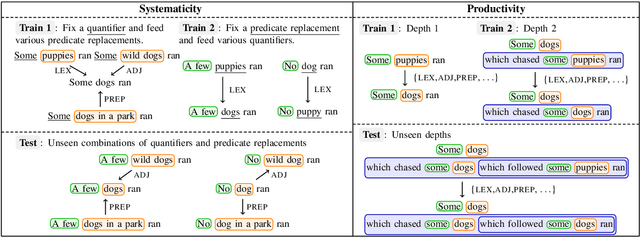


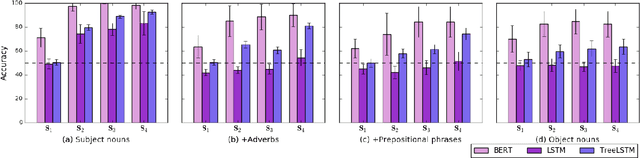
Despite the success of language models using neural networks, it remains unclear to what extent neural models have the generalization ability to perform inferences. In this paper, we introduce a method for evaluating whether neural models can learn systematicity of monotonicity inference in natural language, namely, the regularity for performing arbitrary inferences with generalization on composition. We consider four aspects of monotonicity inferences and test whether the models can systematically interpret lexical and logical phenomena on different training/test splits. A series of experiments show that three neural models systematically draw inferences on unseen combinations of lexical and logical phenomena when the syntactic structures of the sentences are similar between the training and test sets. However, the performance of the models significantly decreases when the structures are slightly changed in the test set while retaining all vocabularies and constituents already appearing in the training set. This indicates that the generalization ability of neural models is limited to cases where the syntactic structures are nearly the same as those in the training set.
A CCG-based Compositional Semantics and Inference System for Comparatives
Oct 02, 2019

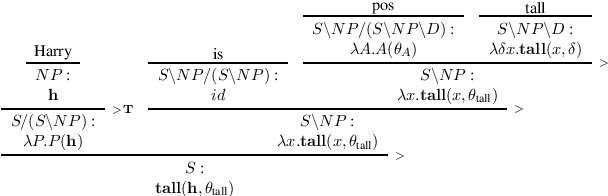
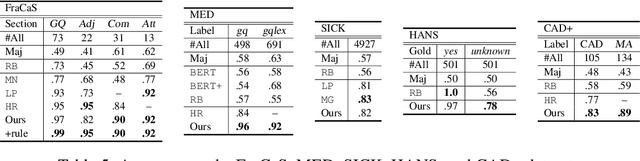
Comparative constructions play an important role in natural language inference. However, attempts to study semantic representations and logical inferences for comparatives from the computational perspective are not well developed, due to the complexity of their syntactic structures and inference patterns. In this study, using a framework based on Combinatory Categorial Grammar (CCG), we present a compositional semantics that maps various comparative constructions in English to semantic representations and introduces an inference system that effectively handles logical inference with comparatives, including those involving numeral adjectives, antonyms, and quantification. We evaluate the performance of our system on the FraCaS test suite and show that the system can handle a variety of complex logical inferences with comparatives.
Can neural networks understand monotonicity reasoning?
Jun 27, 2019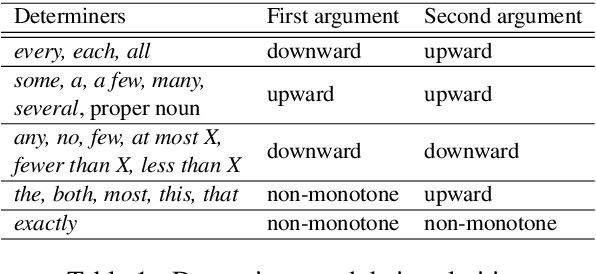


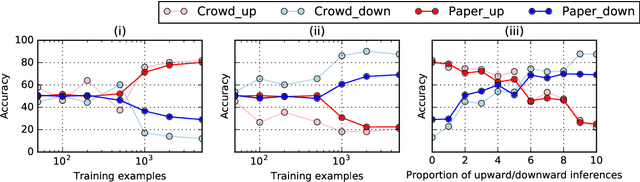
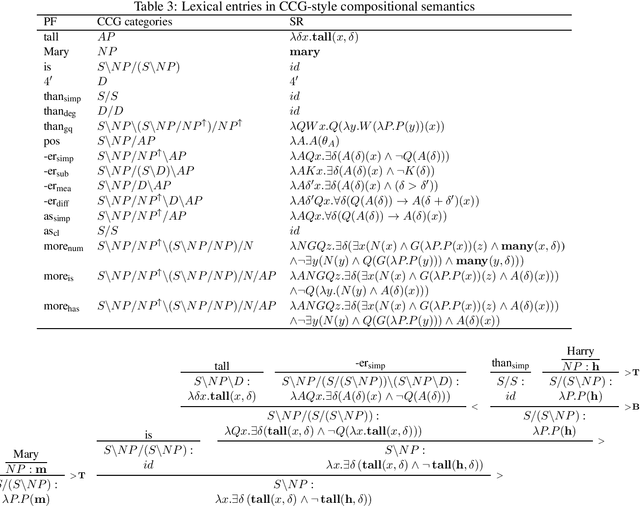
Monotonicity reasoning is one of the important reasoning skills for any intelligent natural language inference (NLI) model in that it requires the ability to capture the interaction between lexical and syntactic structures. Since no test set has been developed for monotonicity reasoning with wide coverage, it is still unclear whether neural models can perform monotonicity reasoning in a proper way. To investigate this issue, we introduce the Monotonicity Entailment Dataset (MED). Performance by state-of-the-art NLI models on the new test set is substantially worse, under 55%, especially on downward reasoning. In addition, analysis using a monotonicity-driven data augmentation method showed that these models might be limited in their generalization ability in upward and downward reasoning.
Multimodal Logical Inference System for Visual-Textual Entailment
Jun 10, 2019
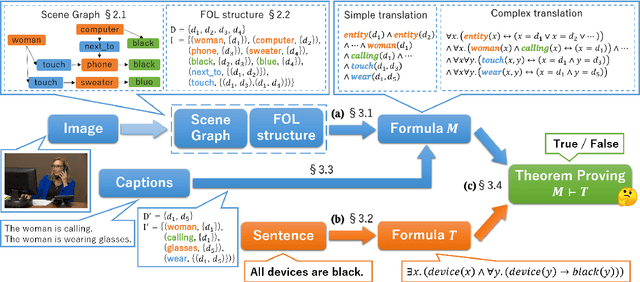


A large amount of research about multimodal inference across text and vision has been recently developed to obtain visually grounded word and sentence representations. In this paper, we use logic-based representations as unified meaning representations for texts and images and present an unsupervised multimodal logical inference system that can effectively prove entailment relations between them. We show that by combining semantic parsing and theorem proving, the system can handle semantically complex sentences for visual-textual inference.
Automatic Generation of High Quality CCGbanks for Parser Domain Adaptation
Jun 05, 2019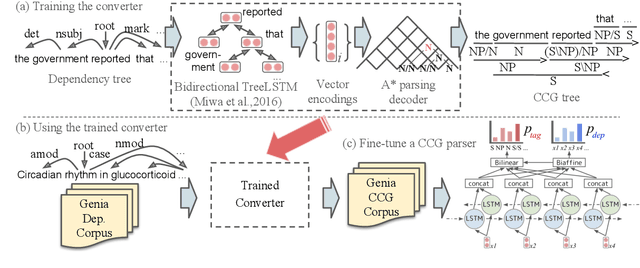
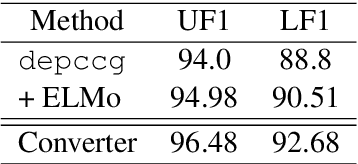

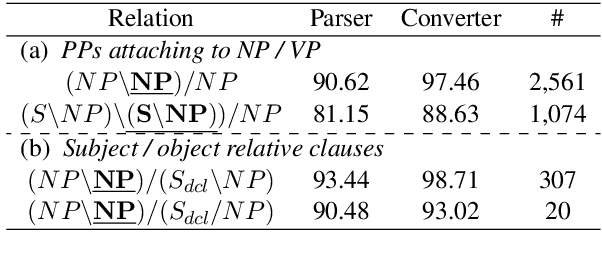
We propose a new domain adaptation method for Combinatory Categorial Grammar (CCG) parsing, based on the idea of automatic generation of CCG corpora exploiting cheaper resources of dependency trees. Our solution is conceptually simple, and not relying on a specific parser architecture, making it applicable to the current best-performing parsers. We conduct extensive parsing experiments with detailed discussion; on top of existing benchmark datasets on (1) biomedical texts and (2) question sentences, we create experimental datasets of (3) speech conversation and (4) math problems. When applied to the proposed method, an off-the-shelf CCG parser shows significant performance gains, improving from 90.7% to 96.6% on speech conversation, and from 88.5% to 96.8% on math problems.