 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOntoURL: A Benchmark for Evaluating Large Language Models on Symbolic Ontological Understanding, Reasoning and Learning
May 19, 2025Large language models (LLMs) have demonstrated remarkable capabilities across a range of natural language processing tasks, yet their ability to process structured symbolic knowledge remains underexplored. To address this gap, we propose a taxonomy of LLMs' ontological capabilities and introduce OntoURL, the first comprehensive benchmark designed to systematically evaluate LLMs' proficiency in handling ontologies -- formal, symbolic representations of domain knowledge through concepts, relationships, and instances. Based on the proposed taxonomy, OntoURL systematically assesses three dimensions: understanding, reasoning, and learning through 15 distinct tasks comprising 58,981 questions derived from 40 ontologies across 8 domains. Experiments with 20 open-source LLMs reveal significant performance differences across models, tasks, and domains, with current LLMs showing proficiency in understanding ontological knowledge but substantial weaknesses in reasoning and learning tasks. These findings highlight fundamental limitations in LLMs' capability to process symbolic knowledge and establish OntoURL as a critical benchmark for advancing the integration of LLMs with formal knowledge representations.
Retrieval-Augmented Semantic Parsing: Using Large Language Models to Improve Generalization
Dec 13, 2024

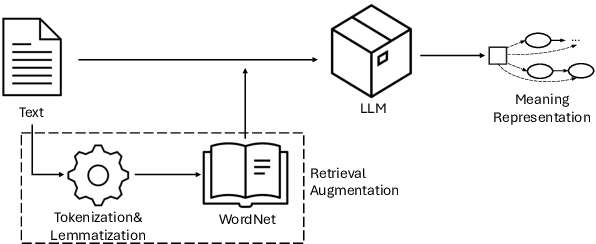

Open-domain semantic parsing remains a challenging task, as models often rely on heuristics and struggle to handle unseen concepts. In this paper, we investigate the potential of large language models (LLMs) for this task and introduce Retrieval-Augmented Semantic Parsing (RASP), a simple yet effective approach that integrates external lexical knowledge into the parsing process. Our experiments not only show that LLMs outperform previous encoder-decoder baselines for semantic parsing, but that RASP further enhances their ability to predict unseen concepts, nearly doubling the performance of previous models on out-of-distribution concepts. These findings highlight the promise of leveraging large language models and retrieval mechanisms for robust and open-domain semantic parsing.
Scope-enhanced Compositional Semantic Parsing for DRT
Jul 02, 2024Discourse Representation Theory (DRT) distinguishes itself from other semantic representation frameworks by its ability to model complex semantic and discourse phenomena through structural nesting and variable binding. While seq2seq models hold the state of the art on DRT parsing, their accuracy degrades with the complexity of the sentence, and they sometimes struggle to produce well-formed DRT representations. We introduce the AMS parser, a compositional, neurosymbolic semantic parser for DRT. It rests on a novel mechanism for predicting quantifier scope. We show that the AMS parser reliably produces well-formed outputs and performs well on DRT parsing, especially on complex sentences.
Neural Semantic Parsing with Extremely Rich Symbolic Meaning Representations
Apr 19, 2024
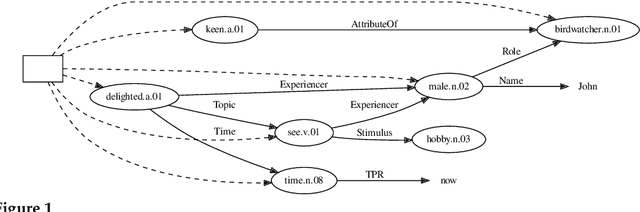


Current open-domain neural semantics parsers show impressive performance. However, closer inspection of the symbolic meaning representations they produce reveals significant weaknesses: sometimes they tend to merely copy character sequences from the source text to form symbolic concepts, defaulting to the most frequent word sense based in the training distribution. By leveraging the hierarchical structure of a lexical ontology, we introduce a novel compositional symbolic representation for concepts based on their position in the taxonomical hierarchy. This representation provides richer semantic information and enhances interpretability. We introduce a neural "taxonomical" semantic parser to utilize this new representation system of predicates, and compare it with a standard neural semantic parser trained on the traditional meaning representation format, employing a novel challenge set and evaluation metric for evaluation. Our experimental findings demonstrate that the taxonomical model, trained on much richer and complex meaning representations, is slightly subordinate in performance to the traditional model using the standard metrics for evaluation, but outperforms it when dealing with out-of-vocabulary concepts. This finding is encouraging for research in computational semantics that aims to combine data-driven distributional meanings with knowledge-based symbolic representations.
Gaining More Insight into Neural Semantic Parsing with Challenging Benchmarks
Apr 12, 2024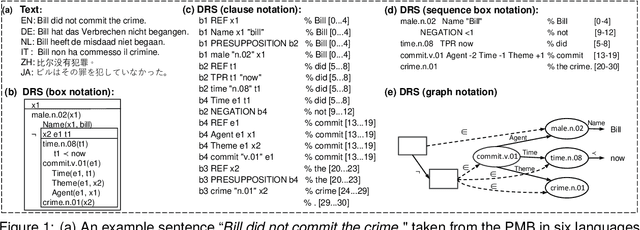
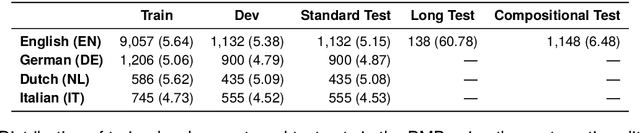
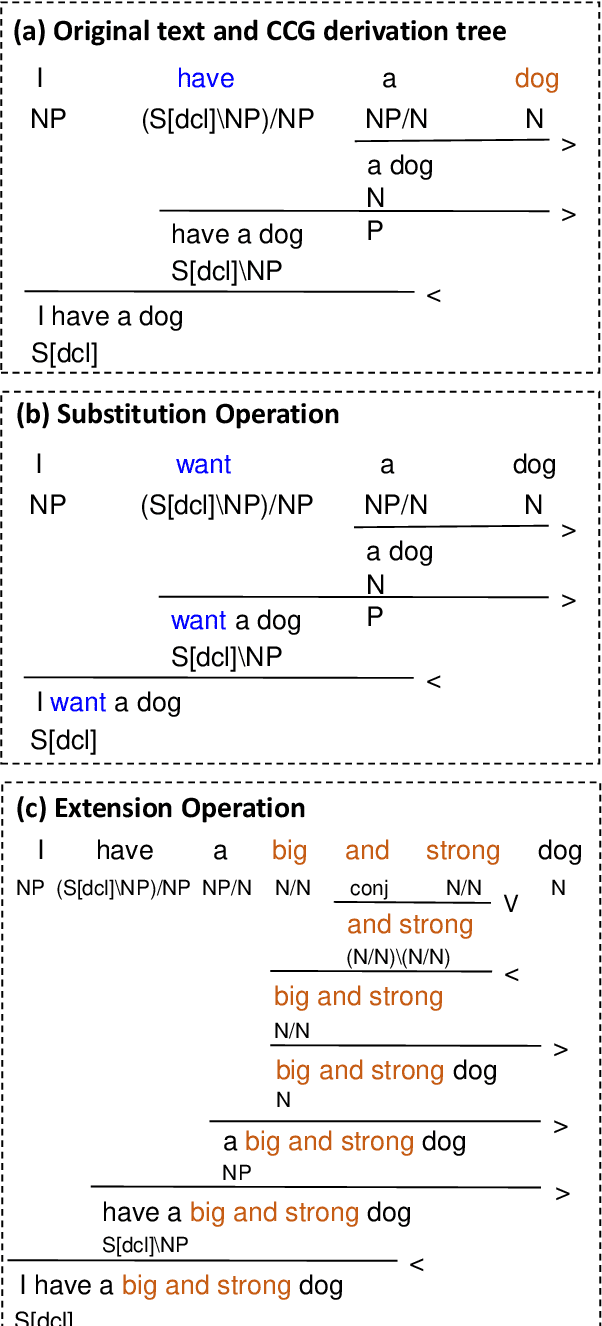
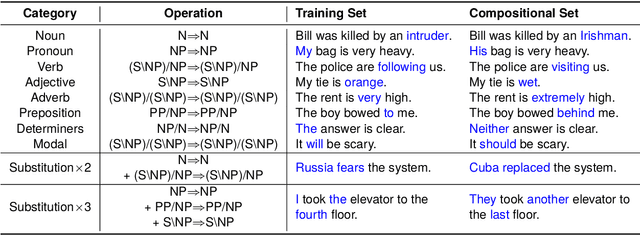
The Parallel Meaning Bank (PMB) serves as a corpus for semantic processing with a focus on semantic parsing and text generation. Currently, we witness an excellent performance of neural parsers and generators on the PMB. This might suggest that such semantic processing tasks have by and large been solved. We argue that this is not the case and that performance scores from the past on the PMB are inflated by non-optimal data splits and test sets that are too easy. In response, we introduce several changes. First, instead of the prior random split, we propose a more systematic splitting approach to improve the reliability of the standard test data. Second, except for the standard test set, we also propose two challenge sets: one with longer texts including discourse structure, and one that addresses compositional generalization. We evaluate five neural models for semantic parsing and meaning-to-text generation. Our results show that model performance declines (in some cases dramatically) on the challenge sets, revealing the limitations of neural models when confronting such challenges.
Controlling Topic-Focus Articulation in Meaning-to-Text Generation using Graph Neural Networks
Oct 03, 2023



A bare meaning representation can be expressed in various ways using natural language, depending on how the information is structured on the surface level. We are interested in finding ways to control topic-focus articulation when generating text from meaning. We focus on distinguishing active and passive voice for sentences with transitive verbs. The idea is to add pragmatic information such as topic to the meaning representation, thereby forcing either active or passive voice when given to a natural language generation system. We use graph neural models because there is no explicit information about word order in a meaning represented by a graph. We try three different methods for topic-focus articulation (TFA) employing graph neural models for a meaning-to-text generation task. We propose a novel encoding strategy about node aggregation in graph neural models, which instead of traditional encoding by aggregating adjacent node information, learns node representations by using depth-first search. The results show our approach can get competitive performance with state-of-art graph models on general text generation, and lead to significant improvements on the task of active-passive conversion compared to traditional adjacency-based aggregation strategies. Different types of TFA can have a huge impact on the performance of the graph models.
Discourse Representation Structure Parsing for Chinese
Jun 16, 2023Previous work has predominantly focused on monolingual English semantic parsing. We, instead, explore the feasibility of Chinese semantic parsing in the absence of labeled data for Chinese meaning representations. We describe the pipeline of automatically collecting the linearized Chinese meaning representation data for sequential-to sequential neural networks. We further propose a test suite designed explicitly for Chinese semantic parsing, which provides fine-grained evaluation for parsing performance, where we aim to study Chinese parsing difficulties. Our experimental results show that the difficulty of Chinese semantic parsing is mainly caused by adverbs. Realizing Chinese parsing through machine translation and an English parser yields slightly lower performance than training a model directly on Chinese data.
Pre-Trained Language-Meaning Models for Multilingual Parsing and Generation
May 31, 2023

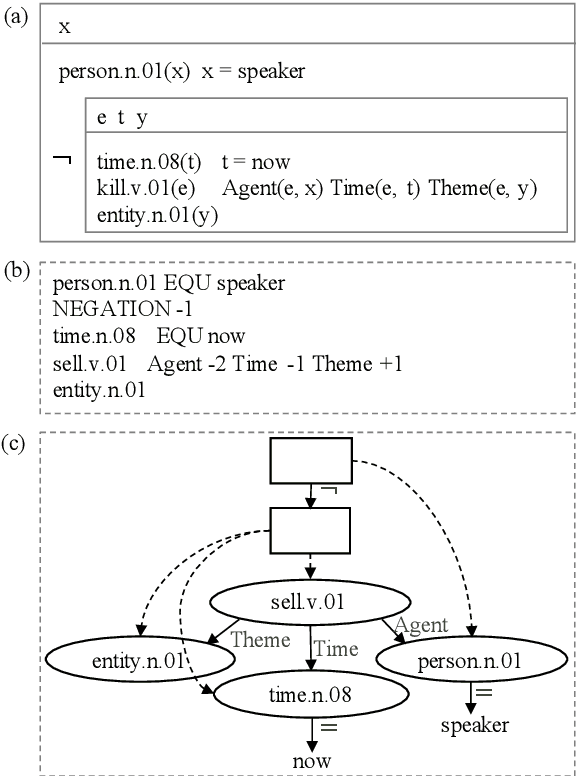

Pre-trained language models (PLMs) have achieved great success in NLP and have recently been used for tasks in computational semantics. However, these tasks do not fully benefit from PLMs since meaning representations are not explicitly included in the pre-training stage. We introduce multilingual pre-trained language-meaning models based on Discourse Representation Structures (DRSs), including meaning representations besides natural language texts in the same model, and design a new strategy to reduce the gap between the pre-training and fine-tuning objectives. Since DRSs are language neutral, cross-lingual transfer learning is adopted to further improve the performance of non-English tasks. Automatic evaluation results show that our approach achieves the best performance on both the multilingual DRS parsing and DRS-to-text generation tasks. Correlation analysis between automatic metrics and human judgements on the generation task further validates the effectiveness of our model. Human inspection reveals that out-of-vocabulary tokens are the main cause of erroneous results.
What's the Meaning of Superhuman Performance in Today's NLU?
May 15, 2023In the last five years, there has been a significant focus in Natural Language Processing (NLP) on developing larger Pretrained Language Models (PLMs) and introducing benchmarks such as SuperGLUE and SQuAD to measure their abilities in language understanding, reasoning, and reading comprehension. These PLMs have achieved impressive results on these benchmarks, even surpassing human performance in some cases. This has led to claims of superhuman capabilities and the provocative idea that certain tasks have been solved. In this position paper, we take a critical look at these claims and ask whether PLMs truly have superhuman abilities and what the current benchmarks are really evaluating. We show that these benchmarks have serious limitations affecting the comparison between humans and PLMs and provide recommendations for fairer and more transparent benchmarks.
The Parallel Meaning Bank: A Framework for Semantically Annotating Multiple Languages
Dec 29, 2020
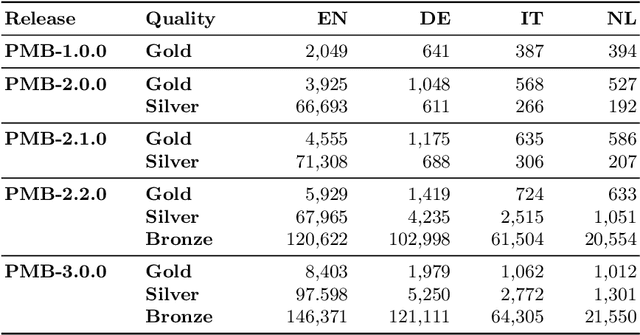

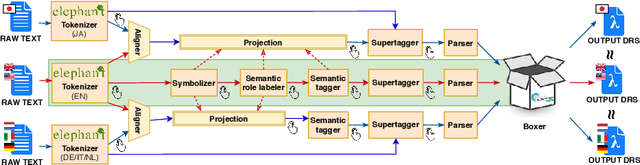
This paper gives a general description of the ideas behind the Parallel Meaning Bank, a framework with the aim to provide an easy way to annotate compositional semantics for texts written in languages other than English. The annotation procedure is semi-automatic, and comprises seven layers of linguistic information: segmentation, symbolisation, semantic tagging, word sense disambiguation, syntactic structure, thematic role labelling, and co-reference. New languages can be added to the meaning bank as long as the documents are based on translations from English, but also introduce new interesting challenges on the linguistics assumptions underlying the Parallel Meaning Bank.