 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormal Proofs as Structured Explanations: Proposing Several Tasks on Explainable Natural Language Inference
Nov 15, 2023
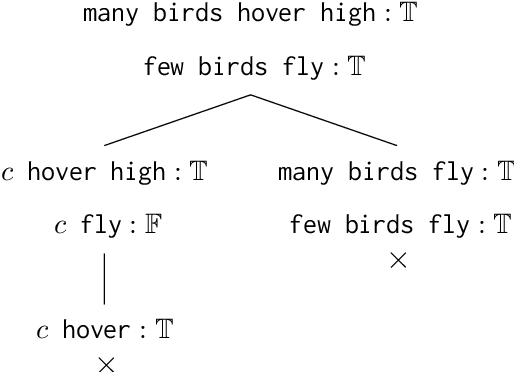
In this position paper, we propose a way of exploiting formal proofs to put forward several explainable natural language inference (NLI) tasks. The formal proofs will be produced by a reliable and high-performing logic-based NLI system. Taking advantage of the in-depth information available in the generated formal proofs, we show how it can be used to define NLI tasks with structured explanations. The proposed tasks can be ordered according to difficulty defined in terms of the granularity of explanations. We argue that the tasks will suffer with substantially fewer shortcomings than the existing explainable NLI tasks (or datasets).
SpaceNLI: Evaluating the Consistency of Predicting Inferences in Space
Jul 05, 2023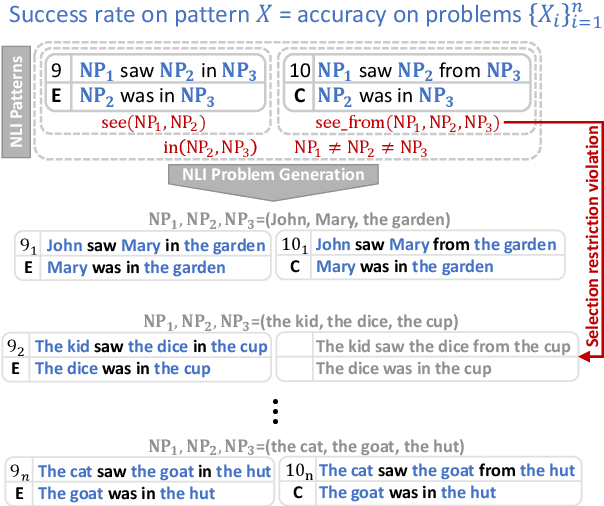


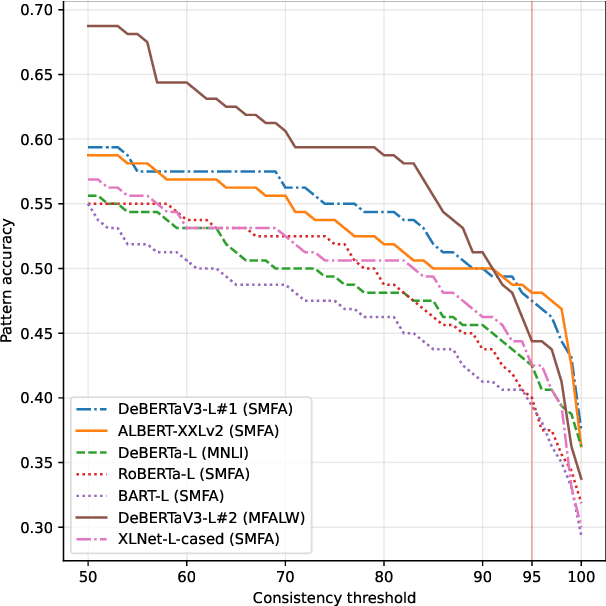
While many natural language inference (NLI) datasets target certain semantic phenomena, e.g., negation, tense & aspect, monotonicity, and presupposition, to the best of our knowledge, there is no NLI dataset that involves diverse types of spatial expressions and reasoning. We fill this gap by semi-automatically creating an NLI dataset for spatial reasoning, called SpaceNLI. The data samples are automatically generated from a curated set of reasoning patterns, where the patterns are annotated with inference labels by experts. We test several SOTA NLI systems on SpaceNLI to gauge the complexity of the dataset and the system's capacity for spatial reasoning. Moreover, we introduce a Pattern Accuracy and argue that it is a more reliable and stricter measure than the accuracy for evaluating a system's performance on pattern-based generated data samples. Based on the evaluation results we find that the systems obtain moderate results on the spatial NLI problems but lack consistency per inference pattern. The results also reveal that non-projective spatial inferences (especially due to the "between" preposition) are the most challenging ones.
A Logic-Based Framework for Natural Language Inference in Dutch
Oct 08, 2021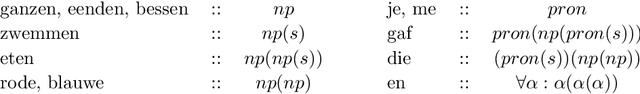
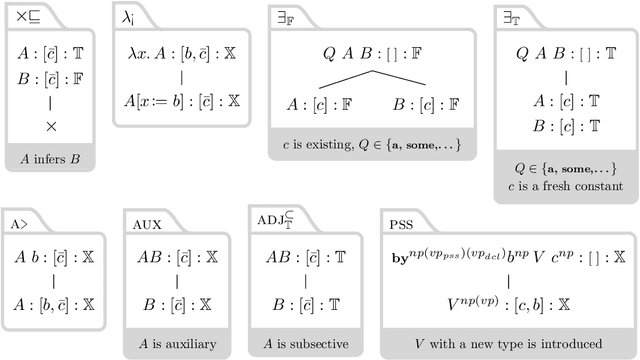
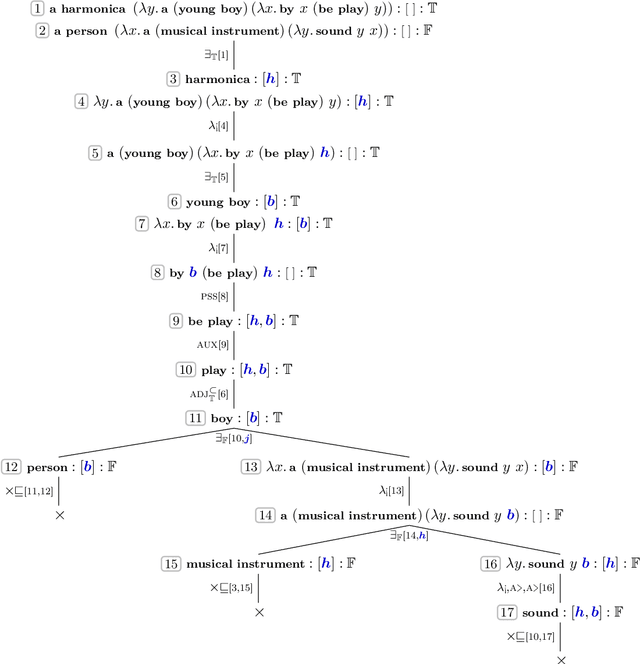
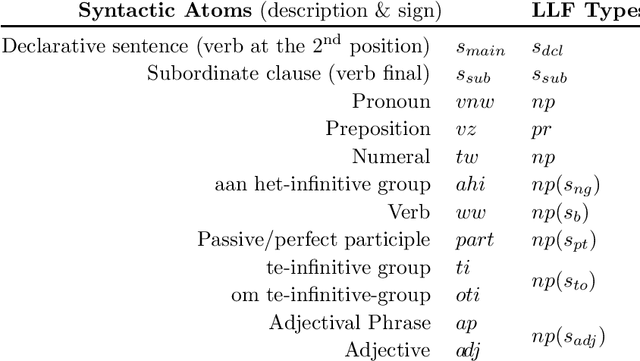
We present a framework for deriving inference relations between Dutch sentence pairs. The proposed framework relies on logic-based reasoning to produce inspectable proofs leading up to inference labels; its judgements are therefore transparent and formally verifiable. At its core, the system is powered by two ${\lambda}$-calculi, used as syntactic and semantic theories, respectively. Sentences are first converted to syntactic proofs and terms of the linear ${\lambda}$-calculus using a choice of two parsers: an Alpino-based pipeline, and Neural Proof Nets. The syntactic terms are then converted to semantic terms of the simply typed ${\lambda}$-calculus, via a set of hand designed type- and term-level transformations. Pairs of semantic terms are then fed to an automated theorem prover for natural logic which reasons with them while using lexical relations found in the Open Dutch WordNet. We evaluate the reasoning pipeline on the recently created Dutch natural language inference dataset, and achieve promising results, remaining only within a $1.1-3.2{\%}$ performance margin to strong neural baselines. To the best of our knowledge, the reasoning pipeline is the first logic-based system for Dutch.
The Parallel Meaning Bank: A Framework for Semantically Annotating Multiple Languages
Dec 29, 2020
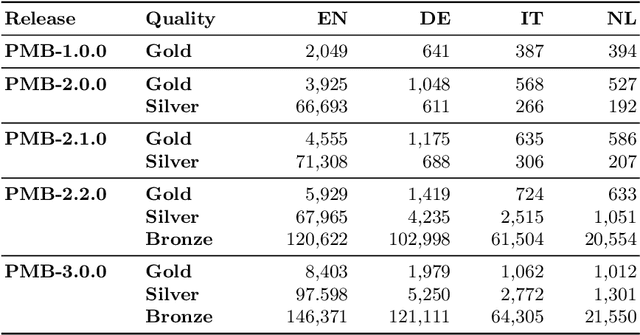

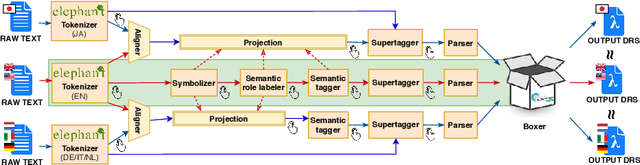
This paper gives a general description of the ideas behind the Parallel Meaning Bank, a framework with the aim to provide an easy way to annotate compositional semantics for texts written in languages other than English. The annotation procedure is semi-automatic, and comprises seven layers of linguistic information: segmentation, symbolisation, semantic tagging, word sense disambiguation, syntactic structure, thematic role labelling, and co-reference. New languages can be added to the meaning bank as long as the documents are based on translations from English, but also introduce new interesting challenges on the linguistics assumptions underlying the Parallel Meaning Bank.
DRS at MRP 2020: Dressing up Discourse Representation Structures as Graphs
Dec 29, 2020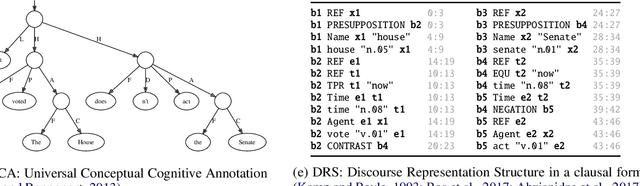
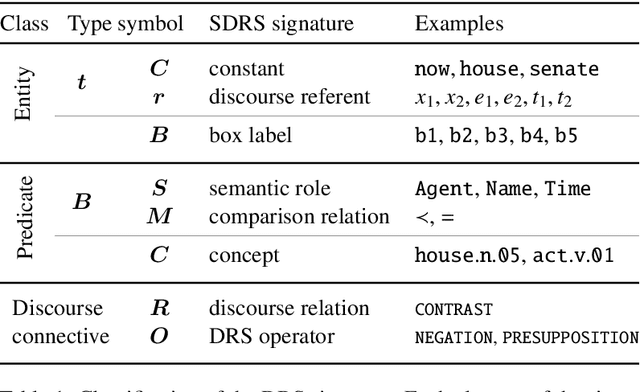
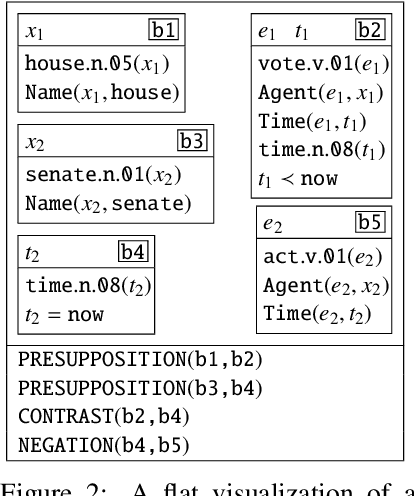
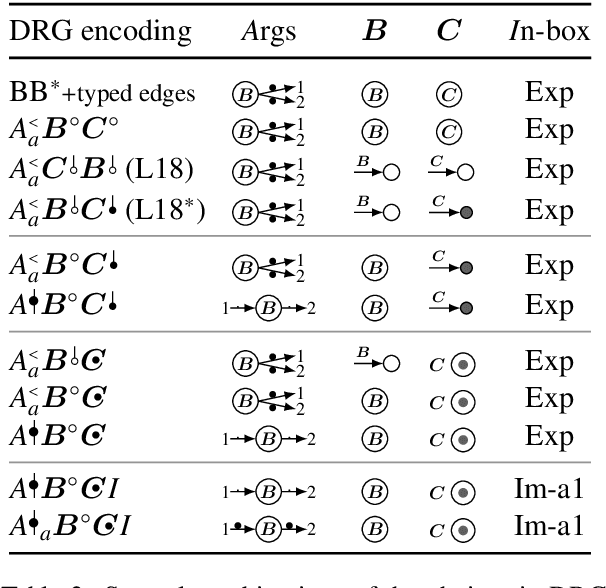
Discourse Representation Theory (DRT) is a formal account for representing the meaning of natural language discourse. Meaning in DRT is modeled via a Discourse Representation Structure (DRS), a meaning representation with a model-theoretic interpretation, which is usually depicted as nested boxes. In contrast, a directed labeled graph is a common data structure used to encode semantics of natural language texts. The paper describes the procedure of dressing up DRSs as directed labeled graphs to include DRT as a new framework in the 2020 shared task on Cross-Framework and Cross-Lingual Meaning Representation Parsing. Since one of the goals of the shared task is to encourage unified models for several semantic graph frameworks, the conversion procedure was biased towards making the DRT graph framework somewhat similar to other graph-based meaning representation frameworks.
Learning as Abduction: Trainable Natural Logic Theorem Prover for Natural Language Inference
Oct 29, 2020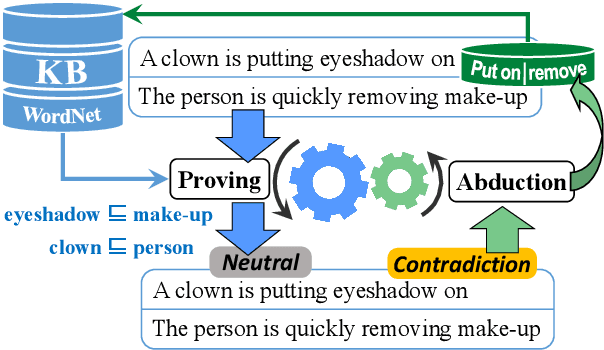
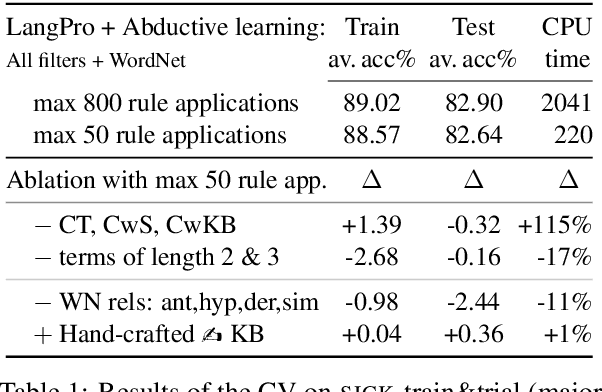


Tackling Natural Language Inference with a logic-based method is becoming less and less common. While this might have been counterintuitive several decades ago, nowadays it seems pretty obvious. The main reasons for such a conception are that (a) logic-based methods are usually brittle when it comes to processing wide-coverage texts, and (b) instead of automatically learning from data, they require much of manual effort for development. We make a step towards to overcome such shortcomings by modeling learning from data as abduction: reversing a theorem-proving procedure to abduce semantic relations that serve as the best explanation for the gold label of an inference problem. In other words, instead of proving sentence-level inference relations with the help of lexical relations, the lexical relations are proved taking into account the sentence-level inference relations. We implement the learning method in a tableau theorem prover for natural language and show that it improves the performance of the theorem prover on the SICK dataset by 1.4% while still maintaining high precision (>94%). The obtained results are competitive with the state of the art among logic-based systems.
Thirty Musts for Meaning Banking
May 27, 2020Meaning banking--creating a semantically annotated corpus for the purpose of semantic parsing or generation--is a challenging task. It is quite simple to come up with a complex meaning representation, but it is hard to design a simple meaning representation that captures many nuances of meaning. This paper lists some lessons learned in nearly ten years of meaning annotation during the development of the Groningen Meaning Bank (Bos et al., 2017) and the Parallel Meaning Bank (Abzianidze et al., 2017). The paper's format is rather unconventional: there is no explicit related work, no methodology section, no results, and no discussion (and the current snippet is not an abstract but actually an introductory preface). Instead, its structure is inspired by work of Traum (2000) and Bender (2013). The list starts with a brief overview of the existing meaning banks (Section 1) and the rest of the items are roughly divided into three groups: corpus collection (Section 2 and 3, annotation methods (Section 4-11), and design of meaning representations (Section 12-30). We hope this overview will give inspiration and guidance in creating improved meaning banks in the future.
* https://www.aclweb.org/anthology/W19-3302/
The First Shared Task on Discourse Representation Structure Parsing
May 27, 2020
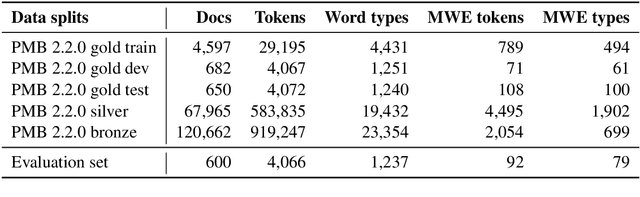

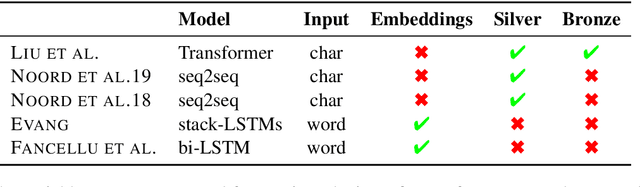
The paper presents the IWCS 2019 shared task on semantic parsing where the goal is to produce Discourse Representation Structures (DRSs) for English sentences. DRSs originate from Discourse Representation Theory and represent scoped meaning representations that capture the semantics of negation, modals, quantification, and presupposition triggers. Additionally, concepts and event-participants in DRSs are described with WordNet synsets and the thematic roles from VerbNet. To measure similarity between two DRSs, they are represented in a clausal form, i.e. as a set of tuples. Participant systems were expected to produce DRSs in this clausal form. Taking into account the rich lexical information, explicit scope marking, a high number of shared variables among clauses, and highly-constrained format of valid DRSs, all these makes the DRS parsing a challenging NLP task. The results of the shared task displayed improvements over the existing state-of-the-art parser.
* International Conference on Computational Semantics (IWCS)
Can neural networks understand monotonicity reasoning?
Jun 27, 2019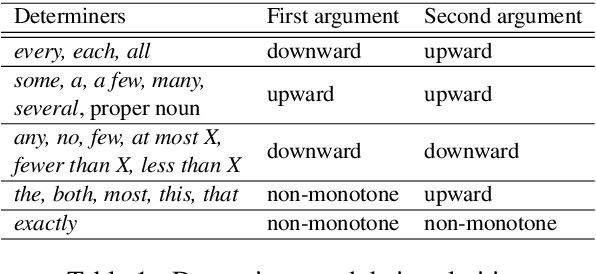


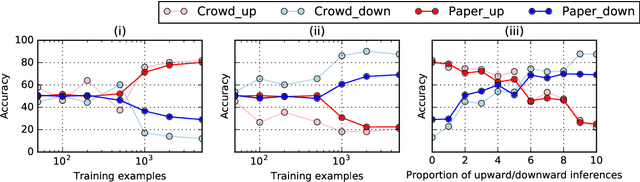
Monotonicity reasoning is one of the important reasoning skills for any intelligent natural language inference (NLI) model in that it requires the ability to capture the interaction between lexical and syntactic structures. Since no test set has been developed for monotonicity reasoning with wide coverage, it is still unclear whether neural models can perform monotonicity reasoning in a proper way. To investigate this issue, we introduce the Monotonicity Entailment Dataset (MED). Performance by state-of-the-art NLI models on the new test set is substantially worse, under 55%, especially on downward reasoning. In addition, analysis using a monotonicity-driven data augmentation method showed that these models might be limited in their generalization ability in upward and downward reasoning.
HELP: A Dataset for Identifying Shortcomings of Neural Models in Monotonicity Reasoning
Apr 27, 2019


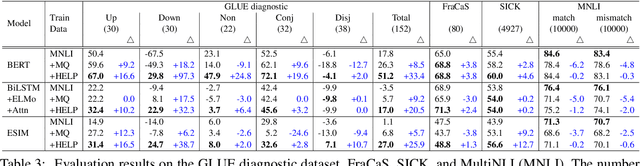
Large crowdsourced datasets are widely used for training and evaluating neural models on natural language inference (NLI). Despite these efforts, neural models have a hard time capturing logical inferences, including those licensed by phrase replacements, so-called monotonicity reasoning. Since no large dataset has been developed for monotonicity reasoning, it is still unclear whether the main obstacle is the size of datasets or the model architectures themselves. To investigate this issue, we introduce a new dataset, called HELP, for handling entailments with lexical and logical phenomena. We add it to training data for the state-of-the-art neural models and evaluate them on test sets for monotonicity phenomena. The results showed that our data augmentation improved the overall accuracy. We also find that the improvement is better on monotonicity inferences with lexical replacements than on downward inferences with disjunction and modification. This suggests that some types of inferences can be improved by our data augmentation while others are immune to it.