 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKUNPENG: An Embodied Large Model for Intelligent Maritime
Jul 12, 2024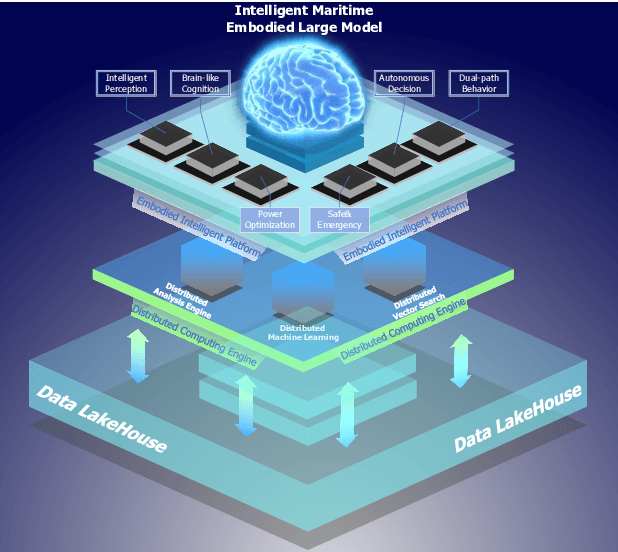
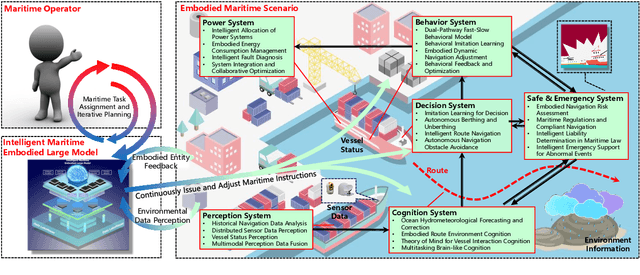
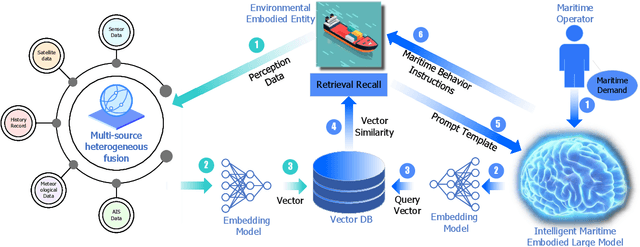
Intelligent maritime, as an essential component of smart ocean construction, deeply integrates advanced artificial intelligence technology and data analysis methods, which covers multiple aspects such as smart vessels, route optimization, safe navigation, aiming to enhance the efficiency of ocean resource utilization and the intelligence of transportation networks. However, the complex and dynamic maritime environment, along with diverse and heterogeneous large-scale data sources, present challenges for real-time decision-making in intelligent maritime. In this paper, We propose KUNPENG, the first-ever embodied large model for intelligent maritime in the smart ocean construction, which consists of six systems. The model perceives multi-source heterogeneous data for the cognition of environmental interaction and make autonomous decision strategies, which are used for intelligent vessels to perform navigation behaviors under safety and emergency guarantees and continuously optimize power to achieve embodied intelligence in maritime. In comprehensive maritime task evaluations, KUNPENG has demonstrated excellent performance.
Gaining More Insight into Neural Semantic Parsing with Challenging Benchmarks
Apr 12, 2024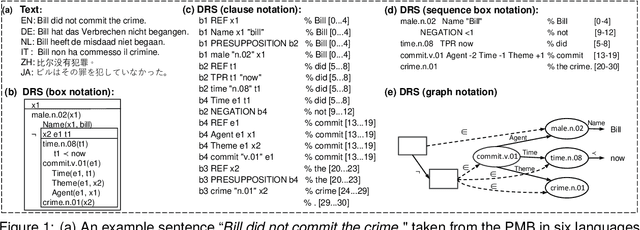
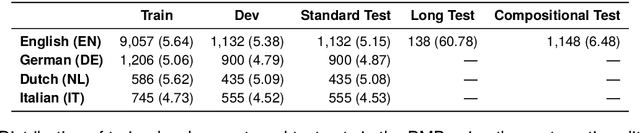
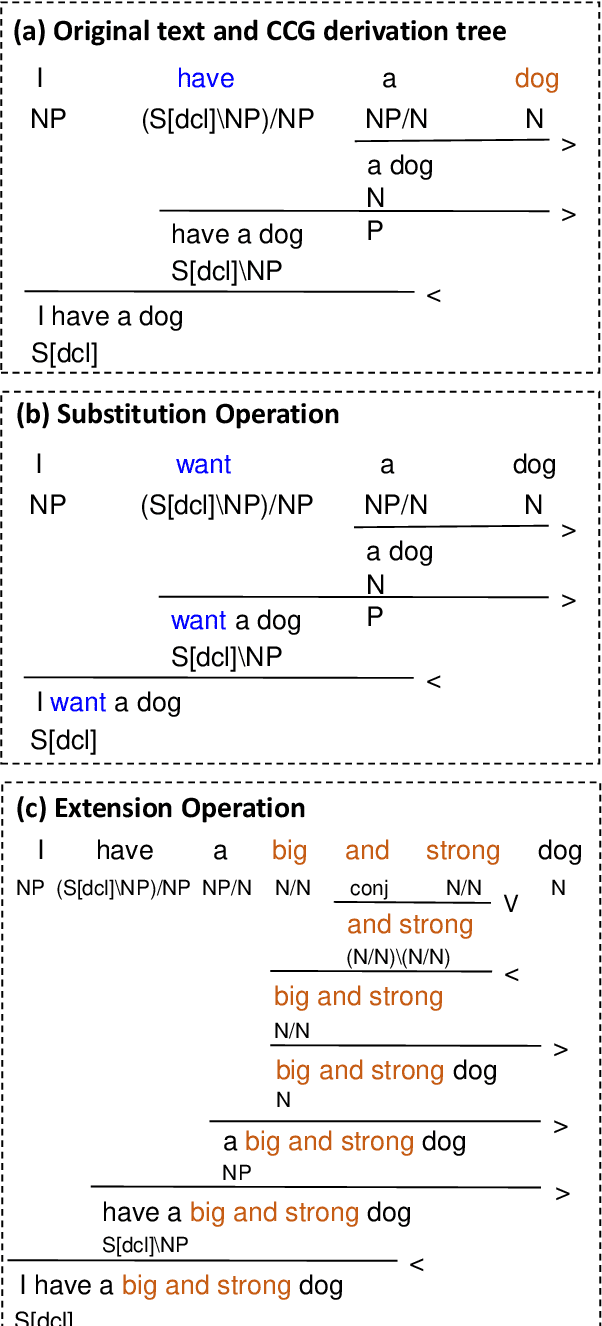
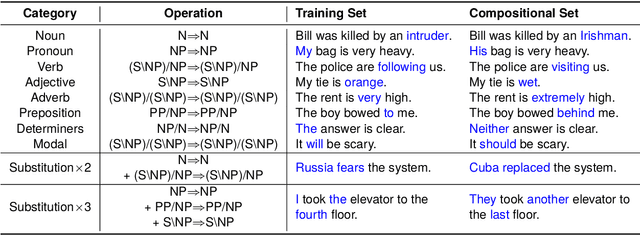
The Parallel Meaning Bank (PMB) serves as a corpus for semantic processing with a focus on semantic parsing and text generation. Currently, we witness an excellent performance of neural parsers and generators on the PMB. This might suggest that such semantic processing tasks have by and large been solved. We argue that this is not the case and that performance scores from the past on the PMB are inflated by non-optimal data splits and test sets that are too easy. In response, we introduce several changes. First, instead of the prior random split, we propose a more systematic splitting approach to improve the reliability of the standard test data. Second, except for the standard test set, we also propose two challenge sets: one with longer texts including discourse structure, and one that addresses compositional generalization. We evaluate five neural models for semantic parsing and meaning-to-text generation. Our results show that model performance declines (in some cases dramatically) on the challenge sets, revealing the limitations of neural models when confronting such challenges.
Controlling Topic-Focus Articulation in Meaning-to-Text Generation using Graph Neural Networks
Oct 03, 2023



A bare meaning representation can be expressed in various ways using natural language, depending on how the information is structured on the surface level. We are interested in finding ways to control topic-focus articulation when generating text from meaning. We focus on distinguishing active and passive voice for sentences with transitive verbs. The idea is to add pragmatic information such as topic to the meaning representation, thereby forcing either active or passive voice when given to a natural language generation system. We use graph neural models because there is no explicit information about word order in a meaning represented by a graph. We try three different methods for topic-focus articulation (TFA) employing graph neural models for a meaning-to-text generation task. We propose a novel encoding strategy about node aggregation in graph neural models, which instead of traditional encoding by aggregating adjacent node information, learns node representations by using depth-first search. The results show our approach can get competitive performance with state-of-art graph models on general text generation, and lead to significant improvements on the task of active-passive conversion compared to traditional adjacency-based aggregation strategies. Different types of TFA can have a huge impact on the performance of the graph models.
Discourse Representation Structure Parsing for Chinese
Jun 16, 2023Previous work has predominantly focused on monolingual English semantic parsing. We, instead, explore the feasibility of Chinese semantic parsing in the absence of labeled data for Chinese meaning representations. We describe the pipeline of automatically collecting the linearized Chinese meaning representation data for sequential-to sequential neural networks. We further propose a test suite designed explicitly for Chinese semantic parsing, which provides fine-grained evaluation for parsing performance, where we aim to study Chinese parsing difficulties. Our experimental results show that the difficulty of Chinese semantic parsing is mainly caused by adverbs. Realizing Chinese parsing through machine translation and an English parser yields slightly lower performance than training a model directly on Chinese data.
Pre-Trained Language-Meaning Models for Multilingual Parsing and Generation
May 31, 2023

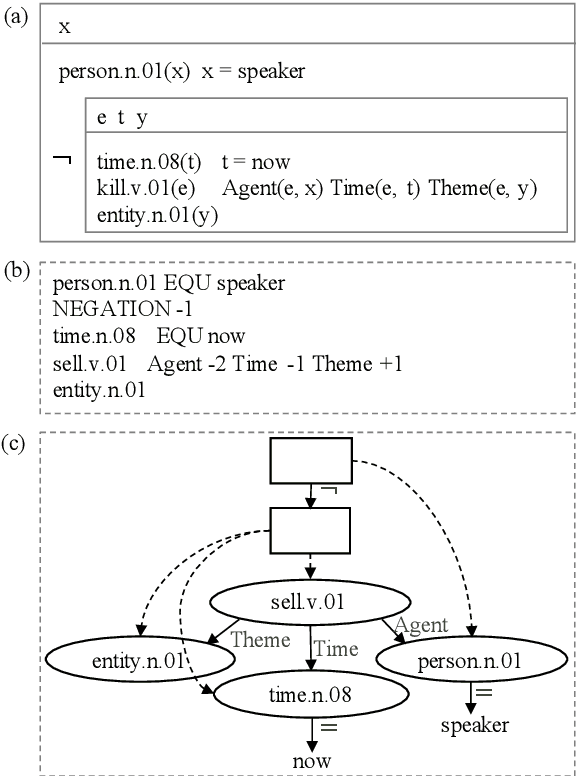

Pre-trained language models (PLMs) have achieved great success in NLP and have recently been used for tasks in computational semantics. However, these tasks do not fully benefit from PLMs since meaning representations are not explicitly included in the pre-training stage. We introduce multilingual pre-trained language-meaning models based on Discourse Representation Structures (DRSs), including meaning representations besides natural language texts in the same model, and design a new strategy to reduce the gap between the pre-training and fine-tuning objectives. Since DRSs are language neutral, cross-lingual transfer learning is adopted to further improve the performance of non-English tasks. Automatic evaluation results show that our approach achieves the best performance on both the multilingual DRS parsing and DRS-to-text generation tasks. Correlation analysis between automatic metrics and human judgements on the generation task further validates the effectiveness of our model. Human inspection reveals that out-of-vocabulary tokens are the main cause of erroneous results.
The Parallel Meaning Bank: A Framework for Semantically Annotating Multiple Languages
Dec 29, 2020
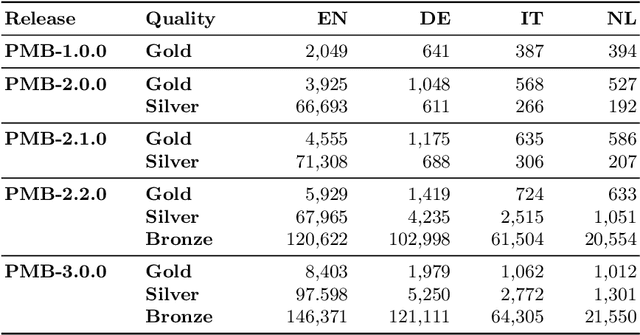

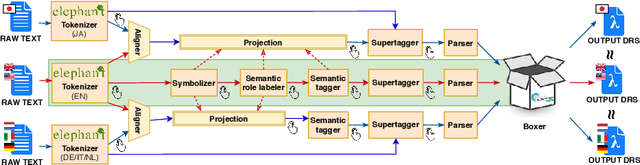
This paper gives a general description of the ideas behind the Parallel Meaning Bank, a framework with the aim to provide an easy way to annotate compositional semantics for texts written in languages other than English. The annotation procedure is semi-automatic, and comprises seven layers of linguistic information: segmentation, symbolisation, semantic tagging, word sense disambiguation, syntactic structure, thematic role labelling, and co-reference. New languages can be added to the meaning bank as long as the documents are based on translations from English, but also introduce new interesting challenges on the linguistics assumptions underlying the Parallel Meaning Bank.