 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-perspective Alignment for Increasing Naturalness in Neural Machine Translation
Dec 11, 2024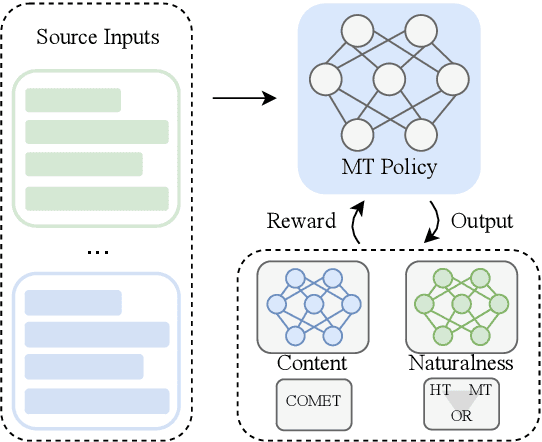
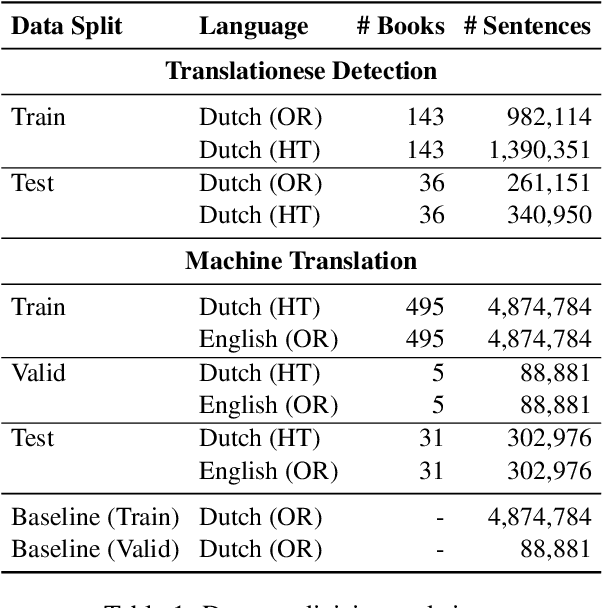
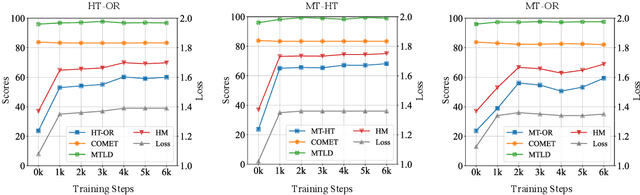
Neural machine translation (NMT) systems amplify lexical biases present in their training data, leading to artificially impoverished language in output translations. These language-level characteristics render automatic translations different from text originally written in a language and human translations, which hinders their usefulness in for example creating evaluation datasets. Attempts to increase naturalness in NMT can fall short in terms of content preservation, where increased lexical diversity comes at the cost of translation accuracy. Inspired by the reinforcement learning from human feedback framework, we introduce a novel method that rewards both naturalness and content preservation. We experiment with multiple perspectives to produce more natural translations, aiming at reducing machine and human translationese. We evaluate our method on English-to-Dutch literary translation, and find that our best model produces translations that are lexically richer and exhibit more properties of human-written language, without loss in translation accuracy.
Towards Tailored Recovery of Lexical Diversity in Literary Machine Translation
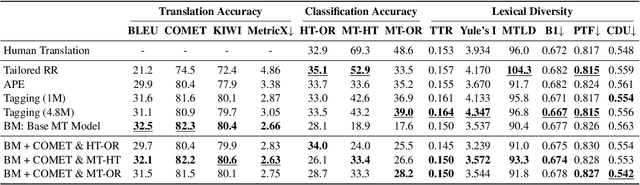
Aug 30, 2024Machine translations are found to be lexically poorer than human translations. The loss of lexical diversity through MT poses an issue in the automatic translation of literature, where it matters not only what is written, but also how it is written. Current methods for increasing lexical diversity in MT are rigid. Yet, as we demonstrate, the degree of lexical diversity can vary considerably across different novels. Thus, rather than aiming for the rigid increase of lexical diversity, we reframe the task as recovering what is lost in the machine translation process. We propose a novel approach that consists of reranking translation candidates with a classifier that distinguishes between original and translated text. We evaluate our approach on 31 English-to-Dutch book translations, and find that, for certain books, our approach retrieves lexical diversity scores that are close to human translation.
Gaining More Insight into Neural Semantic Parsing with Challenging Benchmarks
Apr 12, 2024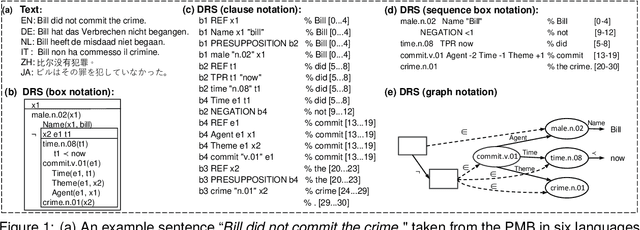
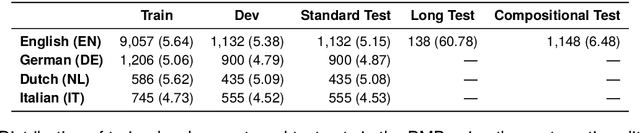
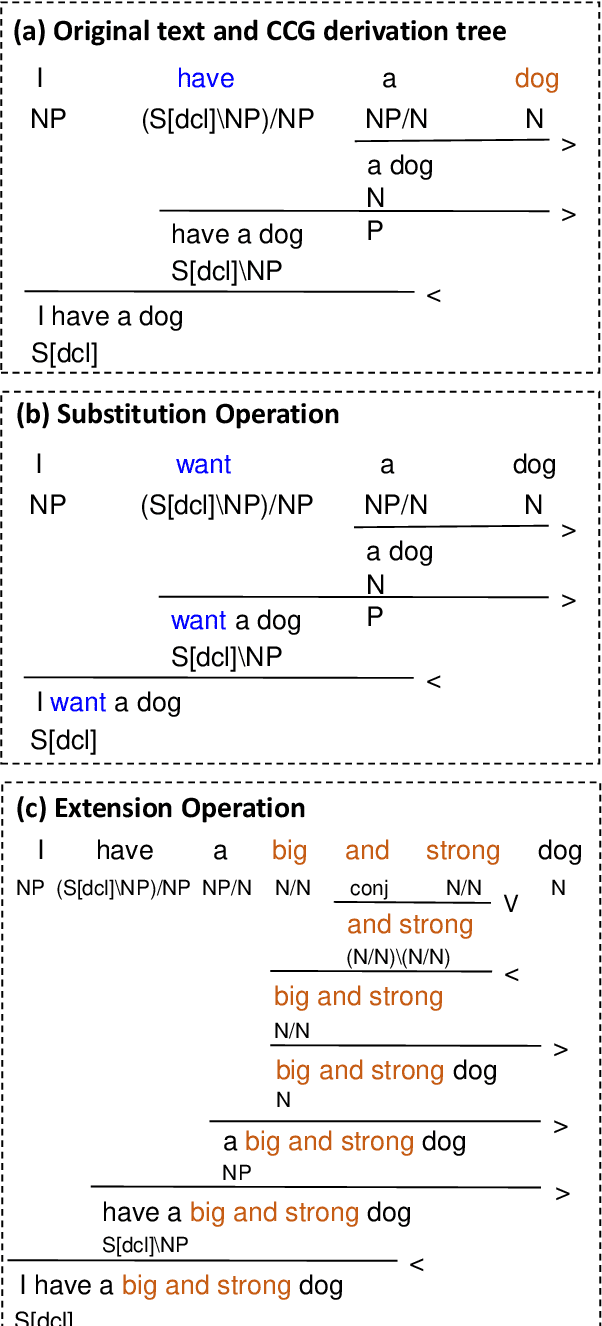
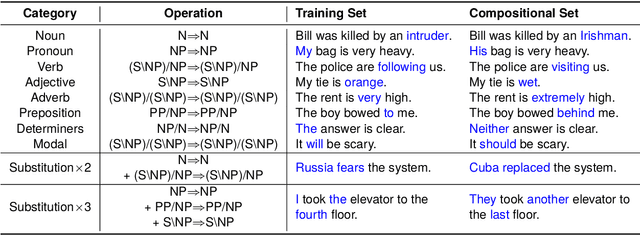
The Parallel Meaning Bank (PMB) serves as a corpus for semantic processing with a focus on semantic parsing and text generation. Currently, we witness an excellent performance of neural parsers and generators on the PMB. This might suggest that such semantic processing tasks have by and large been solved. We argue that this is not the case and that performance scores from the past on the PMB are inflated by non-optimal data splits and test sets that are too easy. In response, we introduce several changes. First, instead of the prior random split, we propose a more systematic splitting approach to improve the reliability of the standard test data. Second, except for the standard test set, we also propose two challenge sets: one with longer texts including discourse structure, and one that addresses compositional generalization. We evaluate five neural models for semantic parsing and meaning-to-text generation. Our results show that model performance declines (in some cases dramatically) on the challenge sets, revealing the limitations of neural models when confronting such challenges.
Language Models on a Diet: Cost-Efficient Development of Encoders for Closely-Related Languages via Additional Pretraining
Apr 08, 2024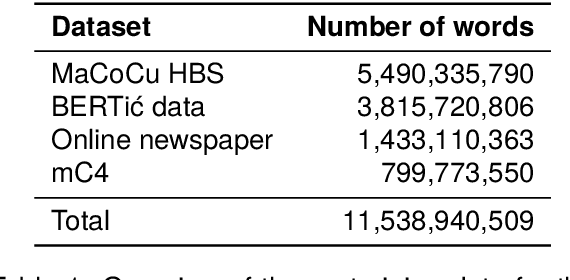
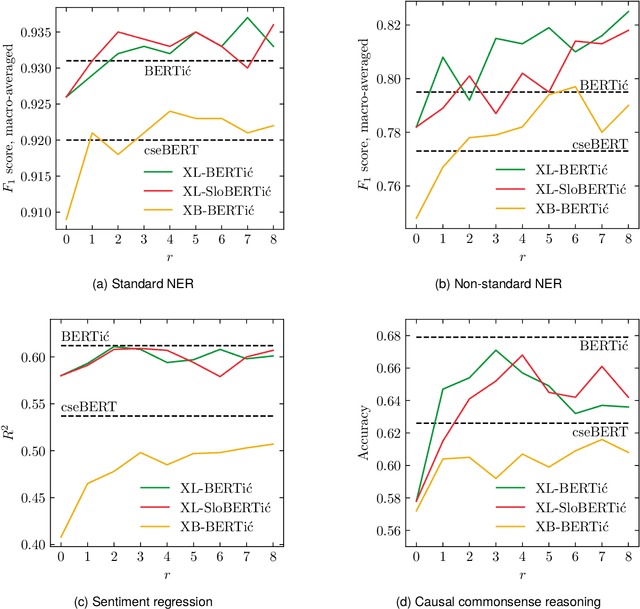
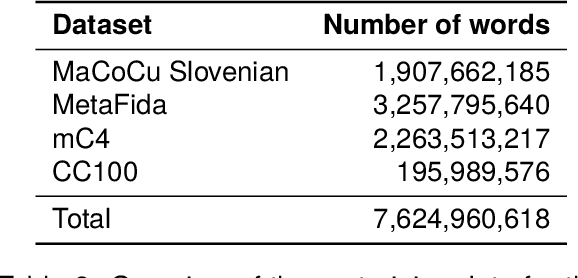

The world of language models is going through turbulent times, better and ever larger models are coming out at an unprecedented speed. However, we argue that, especially for the scientific community, encoder models of up to 1 billion parameters are still very much needed, their primary usage being in enriching large collections of data with metadata necessary for downstream research. We investigate the best way to ensure the existence of such encoder models on the set of very closely related languages - Croatian, Serbian, Bosnian and Montenegrin, by setting up a diverse benchmark for these languages, and comparing the trained-from-scratch models with the new models constructed via additional pretraining of existing multilingual models. We show that comparable performance to dedicated from-scratch models can be obtained by additionally pretraining available multilingual models even with a limited amount of computation. We also show that neighboring languages, in our case Slovenian, can be included in the additional pretraining with little to no loss in the performance of the final model.
Do Language Models Care About Text Quality? Evaluating Web-Crawled Corpora Across 11 Languages
Mar 13, 2024Large, curated, web-crawled corpora play a vital role in training language models (LMs). They form the lion's share of the training data in virtually all recent LMs, such as the well-known GPT, LLaMA and XLM-RoBERTa models. However, despite this importance, relatively little attention has been given to the quality of these corpora. In this paper, we compare four of the currently most relevant large, web-crawled corpora (CC100, MaCoCu, mC4 and OSCAR) across eleven lower-resourced European languages. Our approach is two-fold: first, we perform an intrinsic evaluation by performing a human evaluation of the quality of samples taken from different corpora; then, we assess the practical impact of the qualitative differences by training specific LMs on each of the corpora and evaluating their performance on downstream tasks. We find that there are clear differences in quality of the corpora, with MaCoCu and OSCAR obtaining the best results. However, during the extrinsic evaluation, we actually find that the CC100 corpus achieves the highest scores. We conclude that, in our experiments, the quality of the web-crawled corpora does not seem to play a significant role when training LMs.
Controlling Topic-Focus Articulation in Meaning-to-Text Generation using Graph Neural Networks
Oct 03, 2023



A bare meaning representation can be expressed in various ways using natural language, depending on how the information is structured on the surface level. We are interested in finding ways to control topic-focus articulation when generating text from meaning. We focus on distinguishing active and passive voice for sentences with transitive verbs. The idea is to add pragmatic information such as topic to the meaning representation, thereby forcing either active or passive voice when given to a natural language generation system. We use graph neural models because there is no explicit information about word order in a meaning represented by a graph. We try three different methods for topic-focus articulation (TFA) employing graph neural models for a meaning-to-text generation task. We propose a novel encoding strategy about node aggregation in graph neural models, which instead of traditional encoding by aggregating adjacent node information, learns node representations by using depth-first search. The results show our approach can get competitive performance with state-of-art graph models on general text generation, and lead to significant improvements on the task of active-passive conversion compared to traditional adjacency-based aggregation strategies. Different types of TFA can have a huge impact on the performance of the graph models.
Automatic Discrimination of Human and Neural Machine Translation in Multilingual Scenarios
May 31, 2023We tackle the task of automatically discriminating between human and machine translations. As opposed to most previous work, we perform experiments in a multilingual setting, considering multiple languages and multilingual pretrained language models. We show that a classifier trained on parallel data with a single source language (in our case German-English) can still perform well on English translations that come from different source languages, even when the machine translations were produced by other systems than the one it was trained on. Additionally, we demonstrate that incorporating the source text in the input of a multilingual classifier improves (i) its accuracy and (ii) its robustness on cross-system evaluation, compared to a monolingual classifier. Furthermore, we find that using training data from multiple source languages (German, Russian, and Chinese) tends to improve the accuracy of both monolingual and multilingual classifiers. Finally, we show that bilingual classifiers and classifiers trained on multiple source languages benefit from being trained on longer text sequences, rather than on sentences.
The Parallel Meaning Bank: A Framework for Semantically Annotating Multiple Languages
Dec 29, 2020
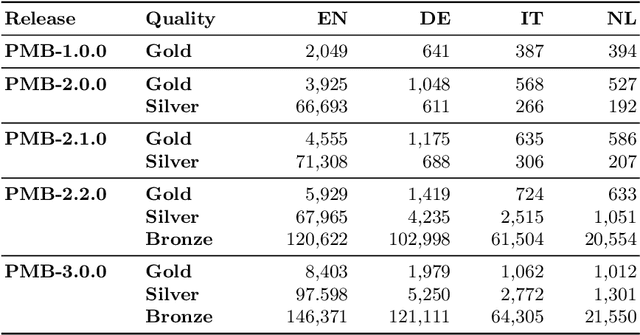

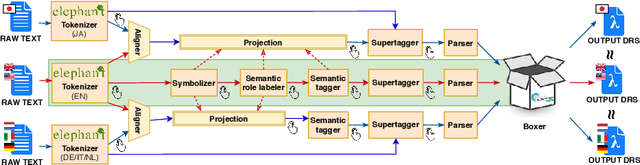
This paper gives a general description of the ideas behind the Parallel Meaning Bank, a framework with the aim to provide an easy way to annotate compositional semantics for texts written in languages other than English. The annotation procedure is semi-automatic, and comprises seven layers of linguistic information: segmentation, symbolisation, semantic tagging, word sense disambiguation, syntactic structure, thematic role labelling, and co-reference. New languages can be added to the meaning bank as long as the documents are based on translations from English, but also introduce new interesting challenges on the linguistics assumptions underlying the Parallel Meaning Bank.
Character-level Representations Improve DRS-based Semantic Parsing Even in the Age of BERT
Nov 09, 2020



We combine character-level and contextual language model representations to improve performance on Discourse Representation Structure parsing. Character representations can easily be added in a sequence-to-sequence model in either one encoder or as a fully separate encoder, with improvements that are robust to different language models, languages and data sets. For English, these improvements are larger than adding individual sources of linguistic information or adding non-contextual embeddings. A new method of analysis based on semantic tags demonstrates that the character-level representations improve performance across a subset of selected semantic phenomena.
The First Shared Task on Discourse Representation Structure Parsing
May 27, 2020
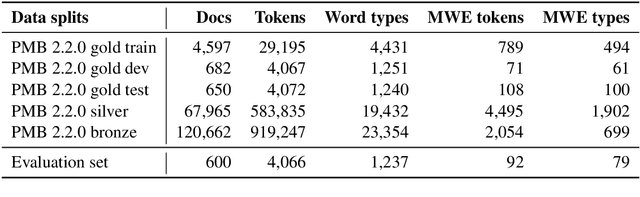

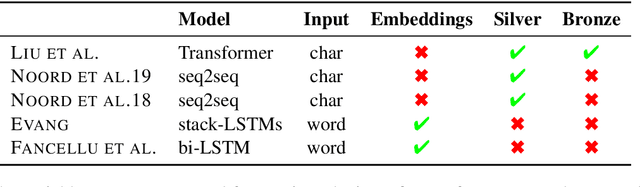
The paper presents the IWCS 2019 shared task on semantic parsing where the goal is to produce Discourse Representation Structures (DRSs) for English sentences. DRSs originate from Discourse Representation Theory and represent scoped meaning representations that capture the semantics of negation, modals, quantification, and presupposition triggers. Additionally, concepts and event-participants in DRSs are described with WordNet synsets and the thematic roles from VerbNet. To measure similarity between two DRSs, they are represented in a clausal form, i.e. as a set of tuples. Participant systems were expected to produce DRSs in this clausal form. Taking into account the rich lexical information, explicit scope marking, a high number of shared variables among clauses, and highly-constrained format of valid DRSs, all these makes the DRS parsing a challenging NLP task. The results of the shared task displayed improvements over the existing state-of-the-art parser.
* International Conference on Computational Semantics (IWCS)