 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTACLer: Tailored Curriculum Reinforcement Learning for Efficient Reasoning
Jan 29, 2026Large Language Models (LLMs) have shown remarkable performance on complex reasoning tasks, especially when equipped with long chain-of-thought (CoT) reasoning. However, eliciting long CoT typically requires large-scale reinforcement learning (RL) training, while often leading to overthinking with redundant intermediate steps. To improve learning and reasoning efficiency, while preserving or even enhancing performance, we propose TACLer, a model-tailored curriculum reinforcement learning framework that gradually increases the complexity of the data based on the model's proficiency in multi-stage RL training. TACLer features two core components: (i) tailored curriculum learning that determines what knowledge the model lacks and needs to learn in progressive stages; (ii) a hybrid Thinking/NoThinking reasoning paradigm that balances accuracy and efficiency by enabling or disabling the Thinking mode. Our experiments show that TACLer yields a twofold advantage in learning and reasoning: (i) it reduces computational cost, cutting training compute by over 50% compared to long thinking models and reducing inference token usage by over 42% relative to the base model; and (ii) it improves accuracy by over 9% on the base model, consistently outperforming state-of-the-art Nothinking and Thinking baselines across four math datasets with complex problems.
OntoURL: A Benchmark for Evaluating Large Language Models on Symbolic Ontological Understanding, Reasoning and Learning
May 19, 2025Large language models (LLMs) have demonstrated remarkable capabilities across a range of natural language processing tasks, yet their ability to process structured symbolic knowledge remains underexplored. To address this gap, we propose a taxonomy of LLMs' ontological capabilities and introduce OntoURL, the first comprehensive benchmark designed to systematically evaluate LLMs' proficiency in handling ontologies -- formal, symbolic representations of domain knowledge through concepts, relationships, and instances. Based on the proposed taxonomy, OntoURL systematically assesses three dimensions: understanding, reasoning, and learning through 15 distinct tasks comprising 58,981 questions derived from 40 ontologies across 8 domains. Experiments with 20 open-source LLMs reveal significant performance differences across models, tasks, and domains, with current LLMs showing proficiency in understanding ontological knowledge but substantial weaknesses in reasoning and learning tasks. These findings highlight fundamental limitations in LLMs' capability to process symbolic knowledge and establish OntoURL as a critical benchmark for advancing the integration of LLMs with formal knowledge representations.
Multidimensional Consistency Improves Reasoning in Language Models
Mar 04, 2025While Large language models (LLMs) have proved able to address some complex reasoning tasks, we also know that they are highly sensitive to input variation, which can lead to different solution paths and final answers. Answer consistency across input variations can thus be taken as a sign of stronger confidence. Leveraging this insight, we introduce a framework, {\em Multidimensional Reasoning Consistency} where, focusing on math problems, models are systematically pushed to diversify solution paths towards a final answer, thereby testing them for answer consistency across multiple input variations. We induce variations in (i) order of shots in prompt, (ii) problem phrasing, and (iii) languages used. Extensive experiments on a large range of open-source state-of-the-art LLMs of various sizes show that reasoning consistency differs by variation dimension, and that by aggregating consistency across dimensions, our framework consistently enhances mathematical reasoning performance on both monolingual dataset GSM8K and multilingual dataset MGSM, especially for smaller models.
Multi-perspective Alignment for Increasing Naturalness in Neural Machine Translation
Dec 11, 2024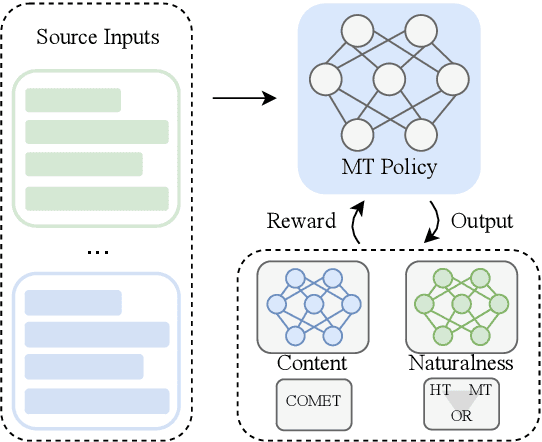
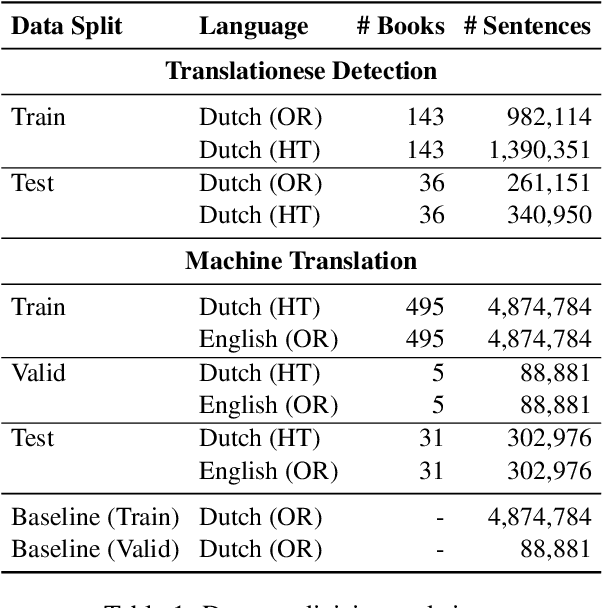
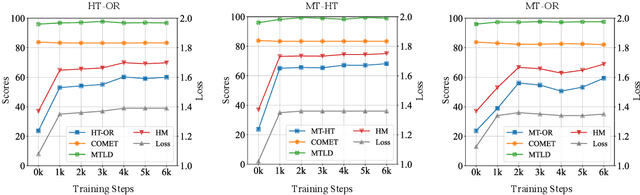
Neural machine translation (NMT) systems amplify lexical biases present in their training data, leading to artificially impoverished language in output translations. These language-level characteristics render automatic translations different from text originally written in a language and human translations, which hinders their usefulness in for example creating evaluation datasets. Attempts to increase naturalness in NMT can fall short in terms of content preservation, where increased lexical diversity comes at the cost of translation accuracy. Inspired by the reinforcement learning from human feedback framework, we introduce a novel method that rewards both naturalness and content preservation. We experiment with multiple perspectives to produce more natural translations, aiming at reducing machine and human translationese. We evaluate our method on English-to-Dutch literary translation, and find that our best model produces translations that are lexically richer and exhibit more properties of human-written language, without loss in translation accuracy.
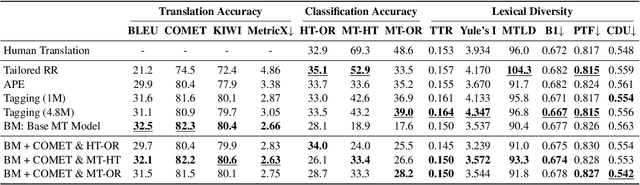
Towards Tailored Recovery of Lexical Diversity in Literary Machine Translation
Aug 30, 2024Machine translations are found to be lexically poorer than human translations. The loss of lexical diversity through MT poses an issue in the automatic translation of literature, where it matters not only what is written, but also how it is written. Current methods for increasing lexical diversity in MT are rigid. Yet, as we demonstrate, the degree of lexical diversity can vary considerably across different novels. Thus, rather than aiming for the rigid increase of lexical diversity, we reframe the task as recovering what is lost in the machine translation process. We propose a novel approach that consists of reranking translation candidates with a classifier that distinguishes between original and translated text. We evaluate our approach on 31 English-to-Dutch book translations, and find that, for certain books, our approach retrieves lexical diversity scores that are close to human translation.
Fine-tuning with HED-IT: The impact of human post-editing for dialogical language models
Jun 11, 2024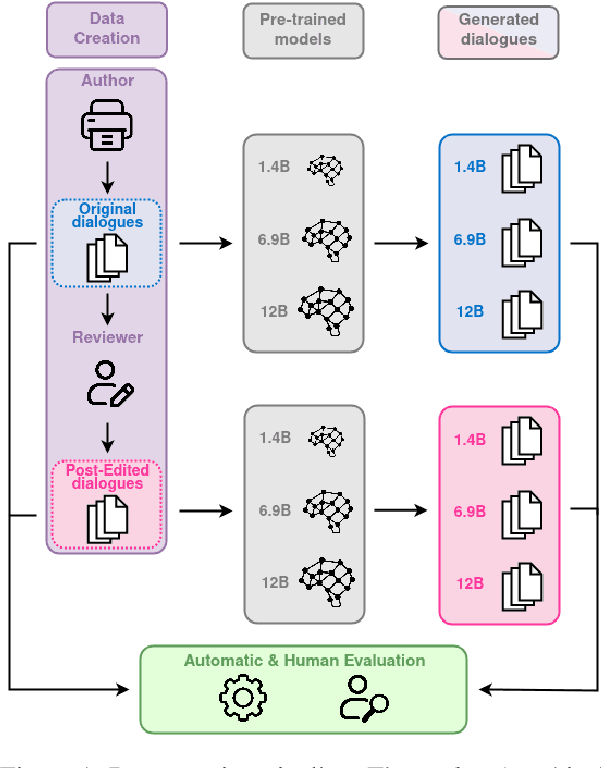

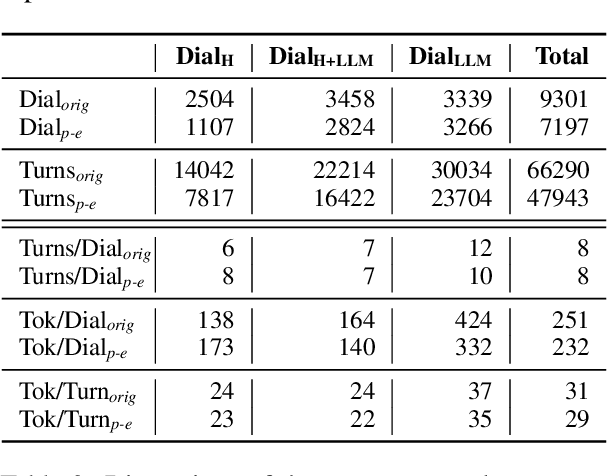

Automatic methods for generating and gathering linguistic data have proven effective for fine-tuning Language Models (LMs) in languages less resourced than English. Still, while there has been emphasis on data quantity, less attention has been given to its quality. In this work, we investigate the impact of human intervention on machine-generated data when fine-tuning dialogical models. In particular, we study (1) whether post-edited dialogues exhibit higher perceived quality compared to the originals that were automatically generated; (2) whether fine-tuning with post-edited dialogues results in noticeable differences in the generated outputs; and (3) whether post-edited dialogues influence the outcomes when considering the parameter size of the LMs. To this end we created HED-IT, a large-scale dataset where machine-generated dialogues are paired with the version post-edited by humans. Using both the edited and unedited portions of HED-IT, we fine-tuned three different sizes of an LM. Results from both human and automatic evaluation show that the different quality of training data is clearly perceived and it has an impact also on the models trained on such data. Additionally, our findings indicate that larger models are less sensitive to data quality, whereas this has a crucial impact on smaller models. These results enhance our comprehension of the impact of human intervention on training data in the development of high-quality LMs.
mCoT: Multilingual Instruction Tuning for Reasoning Consistency in Language Models
Jun 04, 2024



Large language models (LLMs) with Chain-of-thought (CoT) have recently emerged as a powerful technique for eliciting reasoning to improve various downstream tasks. As most research mainly focuses on English, with few explorations in a multilingual context, the question of how reliable this reasoning capability is in different languages is still open. To address it directly, we study multilingual reasoning consistency across multiple languages, using popular open-source LLMs. First, we compile the first large-scale multilingual math reasoning dataset, mCoT-MATH, covering eleven diverse languages. Then, we introduce multilingual CoT instruction tuning to boost reasoning capability across languages, thereby improving model consistency. While existing LLMs show substantial variation across the languages we consider, and especially low performance for lesser resourced languages, our 7B parameter model mCoT achieves impressive consistency across languages, and superior or comparable performance to close- and open-source models even of much larger sizes.
Responsibility Perspective Transfer for Italian Femicide News
Jun 01, 2023Different ways of linguistically expressing the same real-world event can lead to different perceptions of what happened. Previous work has shown that different descriptions of gender-based violence (GBV) influence the reader's perception of who is to blame for the violence, possibly reinforcing stereotypes which see the victim as partly responsible, too. As a contribution to raise awareness on perspective-based writing, and to facilitate access to alternative perspectives, we introduce the novel task of automatically rewriting GBV descriptions as a means to alter the perceived level of responsibility on the perpetrator. We present a quasi-parallel dataset of sentences with low and high perceived responsibility levels for the perpetrator, and experiment with unsupervised (mBART-based), zero-shot and few-shot (GPT3-based) methods for rewriting sentences. We evaluate our models using a questionnaire study and a suite of automatic metrics.
Pre-Trained Language-Meaning Models for Multilingual Parsing and Generation
May 31, 2023

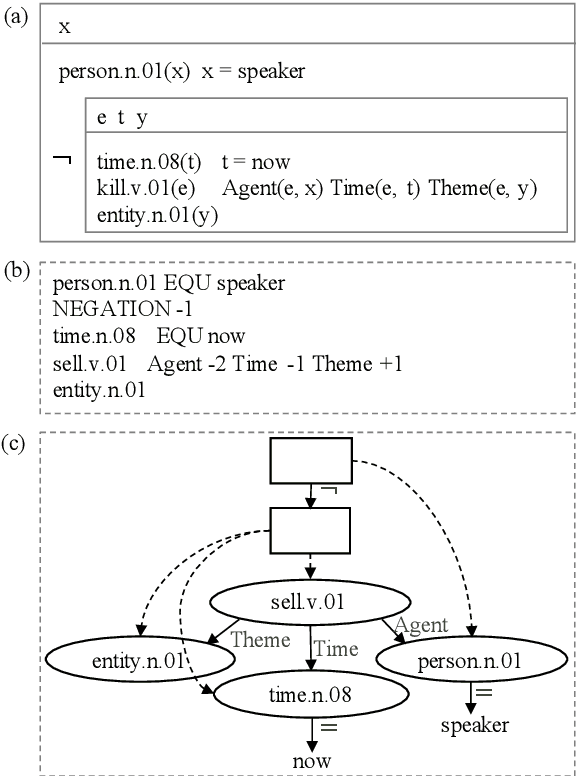

Pre-trained language models (PLMs) have achieved great success in NLP and have recently been used for tasks in computational semantics. However, these tasks do not fully benefit from PLMs since meaning representations are not explicitly included in the pre-training stage. We introduce multilingual pre-trained language-meaning models based on Discourse Representation Structures (DRSs), including meaning representations besides natural language texts in the same model, and design a new strategy to reduce the gap between the pre-training and fine-tuning objectives. Since DRSs are language neutral, cross-lingual transfer learning is adopted to further improve the performance of non-English tasks. Automatic evaluation results show that our approach achieves the best performance on both the multilingual DRS parsing and DRS-to-text generation tasks. Correlation analysis between automatic metrics and human judgements on the generation task further validates the effectiveness of our model. Human inspection reveals that out-of-vocabulary tokens are the main cause of erroneous results.
Multilingual Multi-Figurative Language Detection
May 31, 2023Figures of speech help people express abstract concepts and evoke stronger emotions than literal expressions, thereby making texts more creative and engaging. Due to its pervasive and fundamental character, figurative language understanding has been addressed in Natural Language Processing, but it's highly understudied in a multilingual setting and when considering more than one figure of speech at the same time. To bridge this gap, we introduce multilingual multi-figurative language modelling, and provide a benchmark for sentence-level figurative language detection, covering three common figures of speech and seven languages. Specifically, we develop a framework for figurative language detection based on template-based prompt learning. In so doing, we unify multiple detection tasks that are interrelated across multiple figures of speech and languages, without requiring task- or language-specific modules. Experimental results show that our framework outperforms several strong baselines and may serve as a blueprint for the joint modelling of other interrelated tasks.