 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Accuracy: Community Perspectives on Machine Translation
Jun 08, 2026Despite remarkable progress in machine translation (MT), non-AI communities have raised growing concerns about MT systems, suggesting a noticeable gap between technical advancement and the needs of real-world users. For instance, while NLP researchers focus on benchmark performance, end users care about ethical concerns, trust, reliability, costs, and more. We argue that listening to various user communities is essential so that research efforts would be directed towards the problems that the communities care about. To this end, we present a large-scale analysis, for the first time, that investigates what four stakeholder communities (AI developers, professional translators, language learners, and language service providers) post about MT technology on social media. To do so, we construct a dataset of 79,286 posts and comments from Reddit, Facebook, Bluesky, and Mastodon from 2019 to 2025, and analyse where these communities disagree, and how and why. Overall, we find that communities often disagree, and even show strong conflicts due to polarised sentiments on topics such as translation quality, efficiency, and reliability. This is because these communities approach these topics differently: the AI community frames them as technical and computational problems, while non-AI (user) communities care more about quality nuances, time savings, user trust, and broader social issues.
NLG Evaluation: Past, Present, Future
May 22, 2026Natural Language Generation (NLG) evaluation has changed dramatically since 1990, and will continue to evolve in the future. In 1990, when NLG had close ties to linguistics, there was very little formal experimental evaluation in the modern sense. In 2026, when NLG is closely linked to machine learning, experimental evaluation is expected and indeed fundamental to research. Many evaluation techniques were developed over this period, including most recently LLM-as-Judge. I expect NLG evaluation will continue to evolve in the future. In particular, impact, qualitative, and safety evaluation will become more important as large numbers of people routinely use NLG technology.
Natural Language Generation
Feb 20, 2025This book provides a broad overview of Natural Language Generation (NLG), including technology, user requirements, evaluation, and real-world applications. The focus is on concepts and insights which hopefully will remain relevant for many years, not on the latest LLM innovations. It draws on decades of work by the author and others on NLG. The book has the following chapters: Introduction to NLG; Rule-Based NLG; Machine Learning and Neural NLG; Requirements; Evaluation; Safety, Maintenance, and Testing; and Applications. All chapters include examples and anecdotes from the author's personal experiences, and end with a Further Reading section. The book should be especially useful to people working on applied NLG, including NLG researchers, people in other fields who want to use NLG, and commercial developers. It will not however be useful to people who want to understand the latest LLM technology. There is a companion site with more information at https://ehudreiter.com/book/
* This is a preprint of the following work: Ehud Reiter, Natural Language Generation, 2024, Springer reproduced with permission of Springer Nature Switzerland AG. The final authenticated version is available online at: http://dx.doi.org/10.1007/978-3-031-68582-8
Explaining Bayesian Networks in Natural Language using Factor Arguments. Evaluation in the medical domain
Oct 23, 2024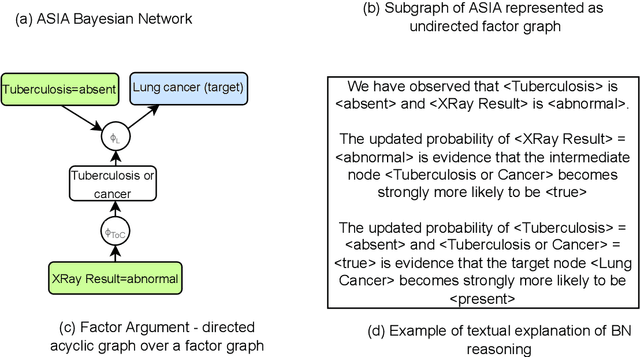

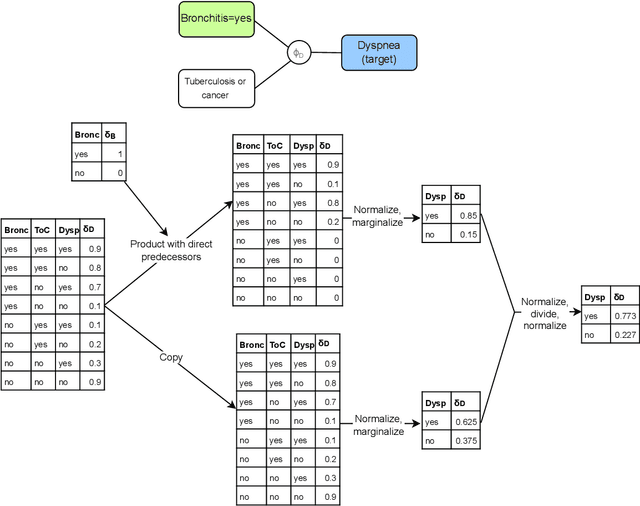

In this paper, we propose a model for building natural language explanations for Bayesian Network Reasoning in terms of factor arguments, which are argumentation graphs of flowing evidence, relating the observed evidence to a target variable we want to learn about. We introduce the notion of factor argument independence to address the outstanding question of defining when arguments should be presented jointly or separately and present an algorithm that, starting from the evidence nodes and a target node, produces a list of all independent factor arguments ordered by their strength. Finally, we implemented a scheme to build natural language explanations of Bayesian Reasoning using this approach. Our proposal has been validated in the medical domain through a human-driven evaluation study where we compare the Bayesian Network Reasoning explanations obtained using factor arguments with an alternative explanation method. Evaluation results indicate that our proposed explanation approach is deemed by users as significantly more useful for understanding Bayesian Network Reasoning than another existing explanation method it is compared to.
Scalability of Bayesian Network Structure Elicitation with Large Language Models: a Novel Methodology and Comparative Analysis
Jul 12, 2024



In this work, we propose a novel method for Bayesian Networks (BNs) structure elicitation that is based on the initialization of several LLMs with different experiences, independently querying them to create a structure of the BN, and further obtaining the final structure by majority voting. We compare the method with one alternative method on various widely and not widely known BNs of different sizes and study the scalability of both methods on them. We also propose an approach to check the contamination of BNs in LLM, which shows that some widely known BNs are inapplicable for testing the LLM usage for BNs structure elicitation. We also show that some BNs may be inapplicable for such experiments because their node names are indistinguishable. The experiments on the other BNs show that our method performs better than the existing method with one of the three studied LLMs; however, the performance of both methods significantly decreases with the increase in BN size.
Effectiveness of ChatGPT in explaining complex medical reports to patients
Jun 23, 2024Electronic health records contain detailed information about the medical condition of patients, but they are difficult for patients to understand even if they have access to them. We explore whether ChatGPT (GPT 4) can help explain multidisciplinary team (MDT) reports to colorectal and prostate cancer patients. These reports are written in dense medical language and assume clinical knowledge, so they are a good test of the ability of ChatGPT to explain complex medical reports to patients. We asked clinicians and lay people (not patients) to review explanations and responses of ChatGPT. We also ran three focus groups (including cancer patients, caregivers, computer scientists, and clinicians) to discuss output of ChatGPT. Our studies highlighted issues with inaccurate information, inappropriate language, limited personalization, AI distrust, and challenges integrating large language models (LLMs) into clinical workflow. These issues will need to be resolved before LLMs can be used to explain complex personal medical information to patients.
A System for Automatic English Text Expansion
May 28, 2024



We present an automatic text expansion system to generate English sentences, which performs automatic Natural Language Generation (NLG) by combining linguistic rules with statistical approaches. Here, "automatic" means that the system can generate coherent and correct sentences from a minimum set of words. From its inception, the design is modular and adaptable to other languages. This adaptability is one of its greatest advantages. For English, we have created the highly precise aLexiE lexicon with wide coverage, which represents a contribution on its own. We have evaluated the resulting NLG library in an Augmentative and Alternative Communication (AAC) proof of concept, both directly (by regenerating corpus sentences) and manually (from annotations) using a popular corpus in the NLG field. We performed a second analysis by comparing the quality of text expansion in English to Spanish, using an ad-hoc Spanish-English parallel corpus. The system might also be applied to other domains such as report and news generation.
PhilHumans: Benchmarking Machine Learning for Personal Health
May 04, 2024



The use of machine learning in Healthcare has the potential to improve patient outcomes as well as broaden the reach and affordability of Healthcare. The history of other application areas indicates that strong benchmarks are essential for the development of intelligent systems. We present Personal Health Interfaces Leveraging HUman-MAchine Natural interactions (PhilHumans), a holistic suite of benchmarks for machine learning across different Healthcare settings - talk therapy, diet coaching, emergency care, intensive care, obstetric sonography - as well as different learning settings, such as action anticipation, timeseries modeling, insight mining, language modeling, computer vision, reinforcement learning and program synthesis
Improving Factual Accuracy of Neural Table-to-Text Output by Addressing Input Problems in ToTTo
Apr 05, 2024Neural Table-to-Text models tend to hallucinate, producing texts that contain factual errors. We investigate whether such errors in the output can be traced back to problems with the input. We manually annotated 1,837 texts generated by multiple models in the politics domain of the ToTTo dataset. We identify the input problems that are responsible for many output errors and show that fixing these inputs reduces factual errors by between 52% and 76% (depending on the model). In addition, we observe that models struggle in processing tabular inputs that are structured in a non-standard way, particularly when the input lacks distinct row and column values or when the column headers are not correctly mapped to corresponding values.
Linguistically Communicating Uncertainty in Patient-Facing Risk Prediction Models
Jan 31, 2024



This paper addresses the unique challenges associated with uncertainty quantification in AI models when applied to patient-facing contexts within healthcare. Unlike traditional eXplainable Artificial Intelligence (XAI) methods tailored for model developers or domain experts, additional considerations of communicating in natural language, its presentation and evaluating understandability are necessary. We identify the challenges in communication model performance, confidence, reasoning and unknown knowns using natural language in the context of risk prediction. We propose a design aimed at addressing these challenges, focusing on the specific application of in-vitro fertilisation outcome prediction.