 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Scaffold Effect: How Prompt Framing Drives Apparent Multimodal Gains in Clinical VLM Evaluation
Mar 30, 2026Trustworthy clinical AI requires that performance gains reflect genuine evidence integration rather than surface-level artifacts. We evaluate 12 open-weight vision-language models (VLMs) on binary classification across two clinical neuroimaging cohorts, \textsc{FOR2107} (affective disorders) and \textsc{OASIS-3} (cognitive decline). Both datasets come with structural MRI data that carries no reliable individual-level diagnostic signal. Under these conditions, smaller VLMs exhibit gains of up to 58\% F1 upon introduction of neuroimaging context, with distilled models becoming competitive with counterparts an order of magnitude larger. A contrastive confidence analysis reveals that merely \emph{mentioning} MRI availability in the task prompt accounts for 70-80\% of this shift, independent of whether imaging data is present, a domain-specific instance of modality collapse we term the \emph{scaffold effect}. Expert evaluation reveals fabrication of neuroimaging-grounded justifications across all conditions, and preference alignment, while eliminating MRI-referencing behavior, collapses both conditions toward random baseline. Our findings demonstrate that surface evaluations are inadequate indicators of multimodal reasoning, with direct implications for the deployment of VLMs in clinical settings.
Large Language Models as Span Annotators
Apr 11, 2025For high-quality texts, single-score metrics seldom provide actionable feedback. In contrast, span annotation - pointing out issues in the text by annotating their spans - can guide improvements and provide insights. Until recently, span annotation was limited to human annotators or fine-tuned encoder models. In this study, we automate span annotation with large language models (LLMs). We compare expert or skilled crowdworker annotators with open and proprietary LLMs on three tasks: data-to-text generation evaluation, machine translation evaluation, and propaganda detection in human-written texts. In our experiments, we show that LLMs as span annotators are straightforward to implement and notably more cost-efficient than human annotators. The LLMs achieve moderate agreement with skilled human annotators, in some scenarios comparable to the average agreement among the annotators themselves. Qualitative analysis shows that reasoning models outperform their instruction-tuned counterparts and provide more valid explanations for annotations. We release the dataset of more than 40k model and human annotations for further research.
Automatic Metrics in Natural Language Generation: A Survey of Current Evaluation Practices
Aug 17, 2024
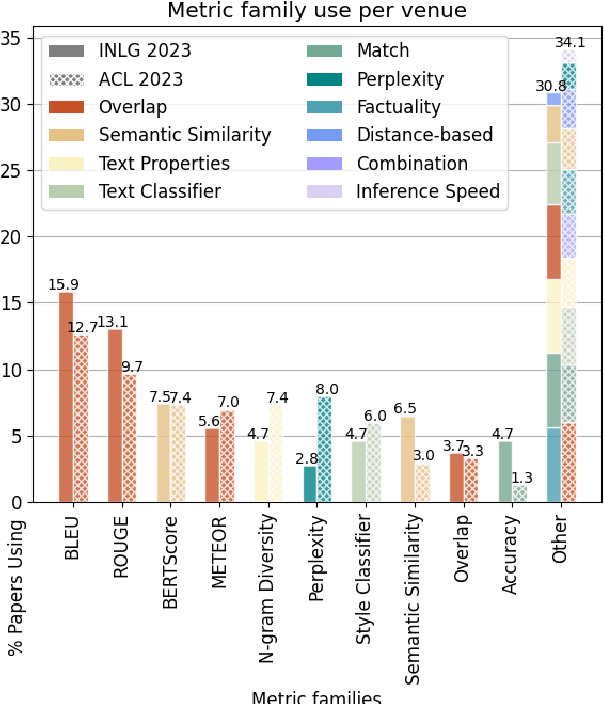
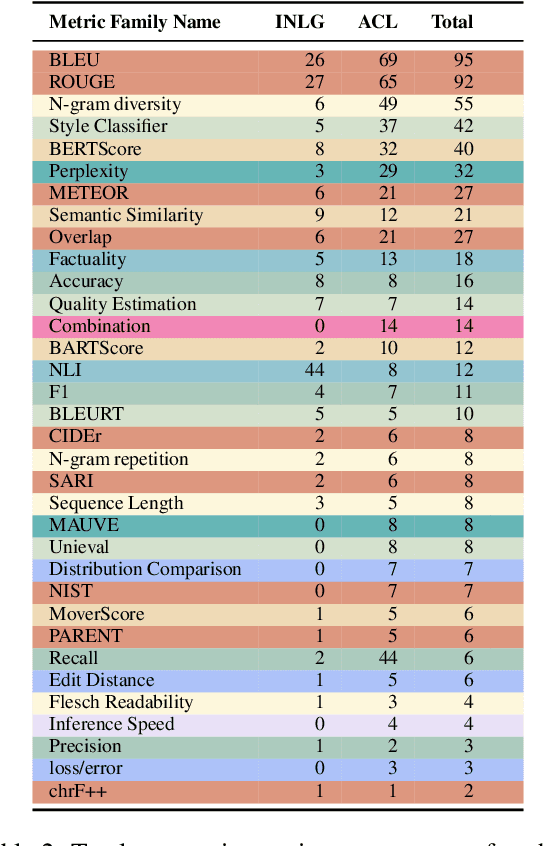
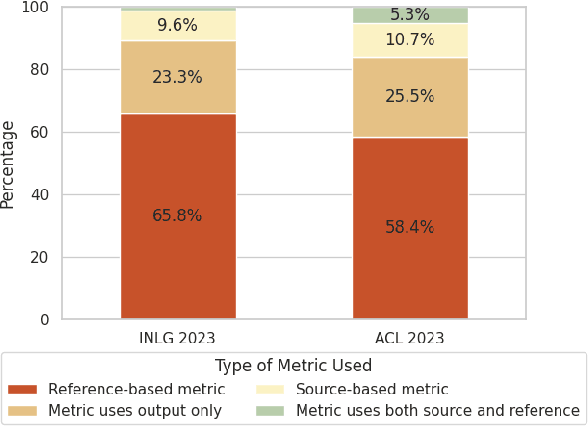
Automatic metrics are extensively used to evaluate natural language processing systems. However, there has been increasing focus on how they are used and reported by practitioners within the field. In this paper, we have conducted a survey on the use of automatic metrics, focusing particularly on natural language generation (NLG) tasks. We inspect which metrics are used as well as why they are chosen and how their use is reported. Our findings from this survey reveal significant shortcomings, including inappropriate metric usage, lack of implementation details and missing correlations with human judgements. We conclude with recommendations that we believe authors should follow to enable more rigour within the field.
factgenie: A Framework for Span-based Evaluation of Generated Texts
Jul 25, 2024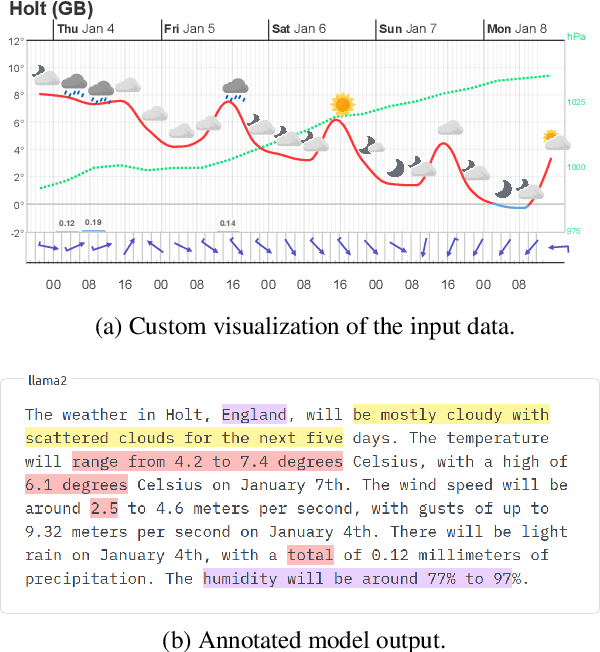
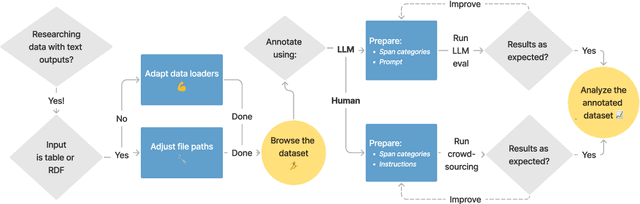
We present factgenie: a framework for annotating and visualizing word spans in textual model outputs. Annotations can capture various span-based phenomena such as semantic inaccuracies or irrelevant text. With factgenie, the annotations can be collected both from human crowdworkers and large language models. Our framework consists of a web interface for data visualization and gathering text annotations, powered by an easily extensible codebase.
Leak, Cheat, Repeat: Data Contamination and Evaluation Malpractices in Closed-Source LLMs
Feb 06, 2024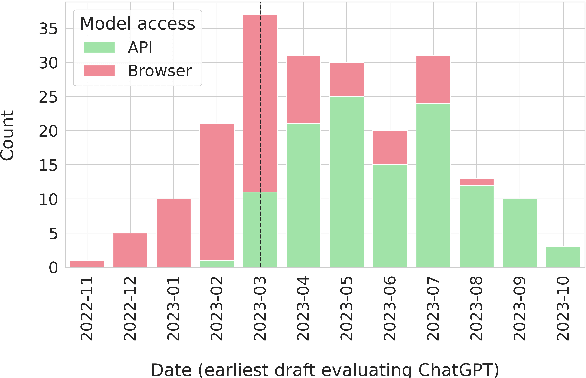
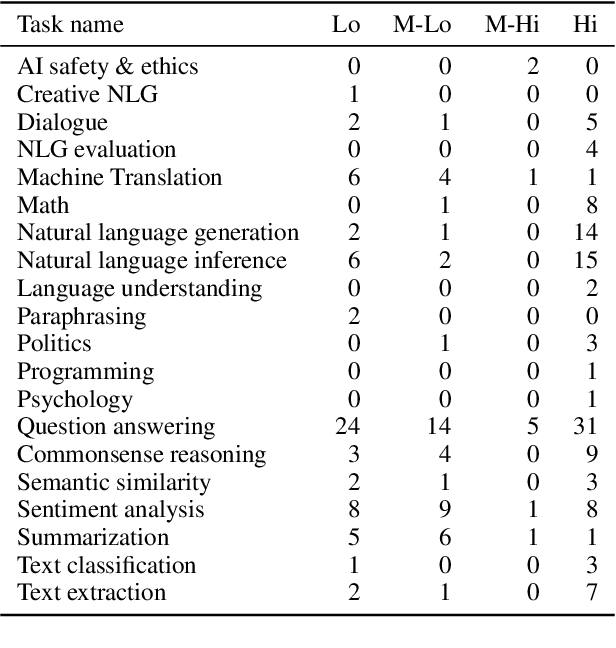
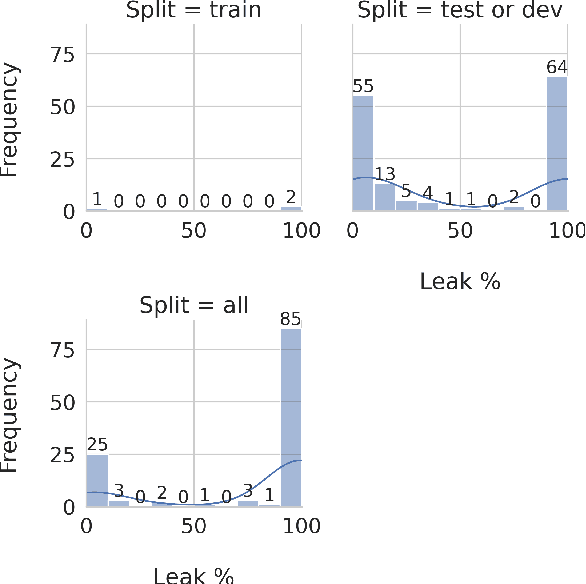
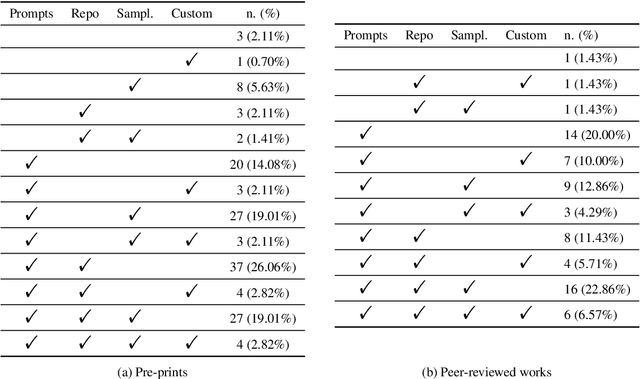
Natural Language Processing (NLP) research is increasingly focusing on the use of Large Language Models (LLMs), with some of the most popular ones being either fully or partially closed-source. The lack of access to model details, especially regarding training data, has repeatedly raised concerns about data contamination among researchers. Several attempts have been made to address this issue, but they are limited to anecdotal evidence and trial and error. Additionally, they overlook the problem of \emph{indirect} data leaking, where models are iteratively improved by using data coming from users. In this work, we conduct the first systematic analysis of work using OpenAI's GPT-3.5 and GPT-4, the most prominently used LLMs today, in the context of data contamination. By analysing 255 papers and considering OpenAI's data usage policy, we extensively document the amount of data leaked to these models during the first year after the model's release. We report that these models have been globally exposed to $\sim$4.7M samples from 263 benchmarks. At the same time, we document a number of evaluation malpractices emerging in the reviewed papers, such as unfair or missing baseline comparisons and reproducibility issues. We release our results as a collaborative project on https://leak-llm.github.io/, where other researchers can contribute to our efforts.
Ask the experts: sourcing high-quality datasets for nutritional counselling through Human-AI collaboration
Jan 16, 2024Large Language Models (LLMs), with their flexible generation abilities, can be powerful data sources in domains with few or no available corpora. However, problems like hallucinations and biases limit such applications. In this case study, we pick nutrition counselling, a domain lacking any public resource, and show that high-quality datasets can be gathered by combining LLMs, crowd-workers and nutrition experts. We first crowd-source and cluster a novel dataset of diet-related issues, then work with experts to prompt ChatGPT into producing related supportive text. Finally, we let the experts evaluate the safety of the generated text. We release HAI-coaching, the first expert-annotated nutrition counselling dataset containing ~2.4K dietary struggles from crowd workers, and ~97K related supportive texts generated by ChatGPT. Extensive analysis shows that ChatGPT while producing highly fluent and human-like text, also manifests harmful behaviours, especially in sensitive topics like mental health, making it unsuitable for unsupervised use.
Comparing informativeness of an NLG chatbot vs graphical app in diet-information domain
Jul 02, 2022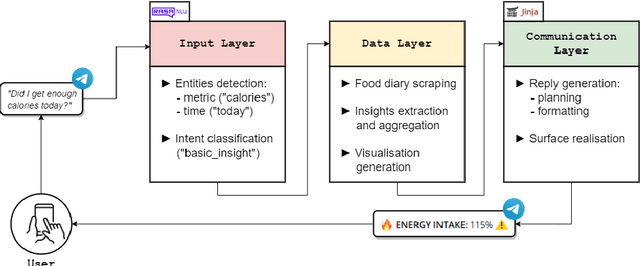
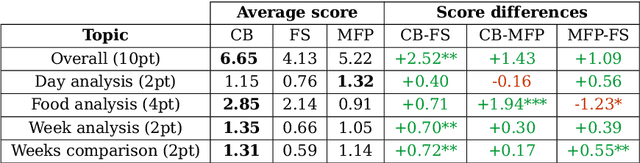
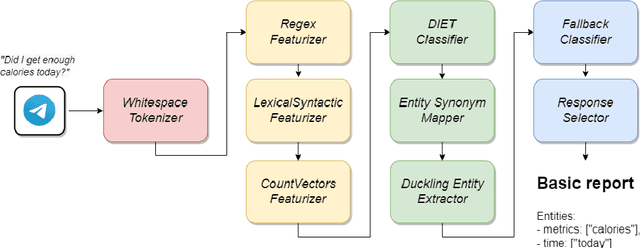

Visual representation of data like charts and tables can be challenging to understand for readers. Previous work showed that combining visualisations with text can improve the communication of insights in static contexts, but little is known about interactive ones. In this work we present an NLG chatbot that processes natural language queries and provides insights through a combination of charts and text. We apply it to nutrition, a domain communication quality is critical. Through crowd-sourced evaluation we compare the informativeness of our chatbot against traditional, static diet-apps. We find that the conversational context significantly improved users' understanding of dietary data in various tasks, and that users considered the chatbot as more useful and quick to use than traditional apps.
How are you? Introducing stress-based text tailoring
Jul 20, 2020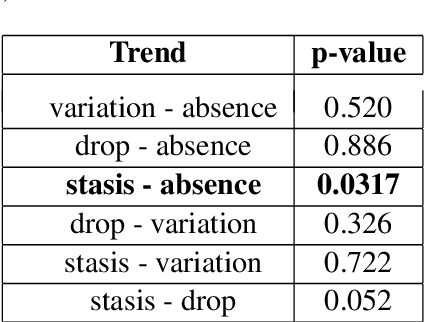
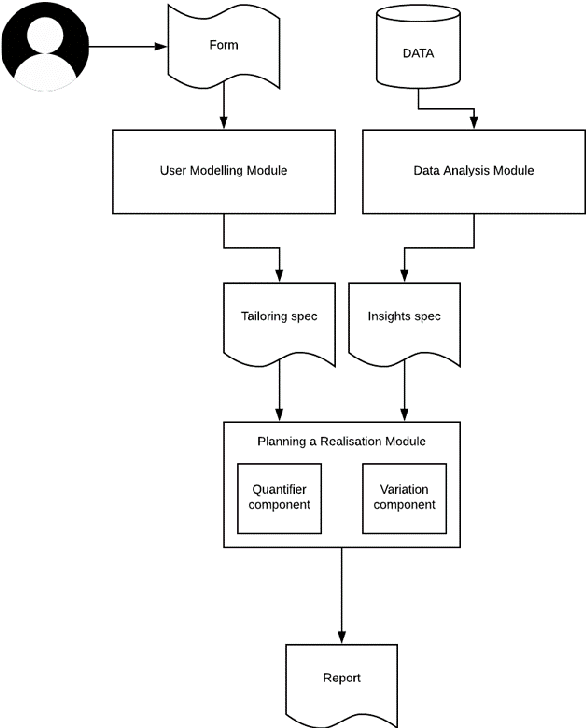
Can stress affect not only your life but also how you read and interpret a text? Healthcare has shown evidence of such dynamics and in this short paper we discuss customising texts based on user stress level, as it could represent a critical factor when it comes to user engagement and behavioural change. We first show a real-world example in which user behaviour is influenced by stress, then, after discussing which tools can be employed to assess and measure it, we propose an initial method for tailoring the document by exploiting complexity reduction and affect enforcement. The result is a short and encouraging text which requires less commitment to be read and understood. We believe this work in progress can raise some interesting questions on a topic that is often overlooked in NLG.