 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models as Span Annotators
Apr 11, 2025For high-quality texts, single-score metrics seldom provide actionable feedback. In contrast, span annotation - pointing out issues in the text by annotating their spans - can guide improvements and provide insights. Until recently, span annotation was limited to human annotators or fine-tuned encoder models. In this study, we automate span annotation with large language models (LLMs). We compare expert or skilled crowdworker annotators with open and proprietary LLMs on three tasks: data-to-text generation evaluation, machine translation evaluation, and propaganda detection in human-written texts. In our experiments, we show that LLMs as span annotators are straightforward to implement and notably more cost-efficient than human annotators. The LLMs achieve moderate agreement with skilled human annotators, in some scenarios comparable to the average agreement among the annotators themselves. Qualitative analysis shows that reasoning models outperform their instruction-tuned counterparts and provide more valid explanations for annotations. We release the dataset of more than 40k model and human annotations for further research.
Automatic Metrics in Natural Language Generation: A Survey of Current Evaluation Practices
Aug 17, 2024
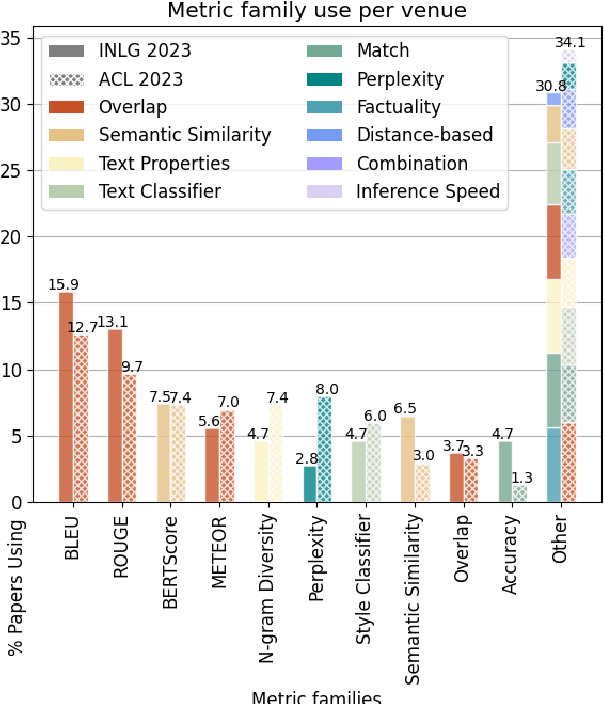
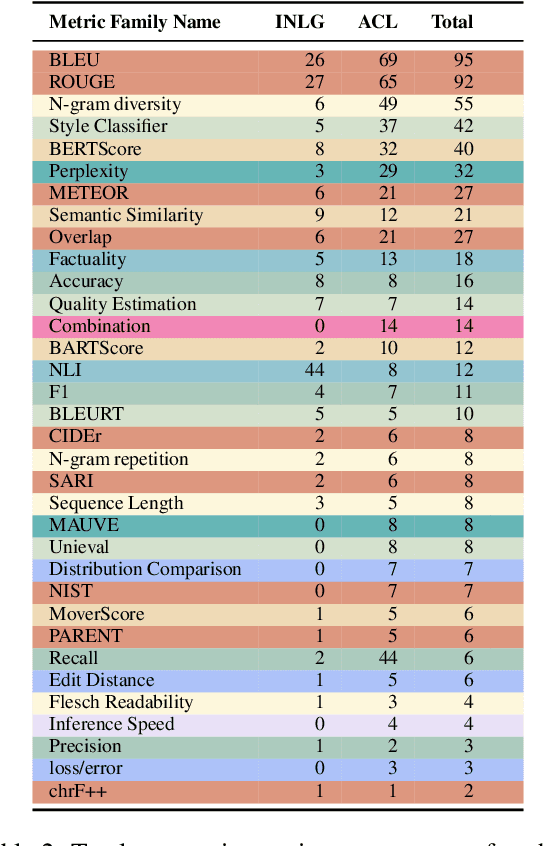
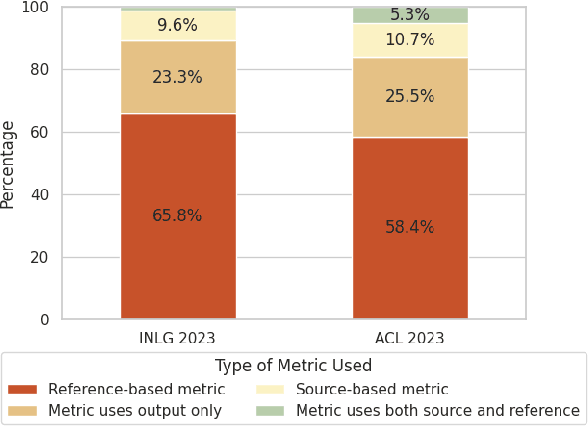
Automatic metrics are extensively used to evaluate natural language processing systems. However, there has been increasing focus on how they are used and reported by practitioners within the field. In this paper, we have conducted a survey on the use of automatic metrics, focusing particularly on natural language generation (NLG) tasks. We inspect which metrics are used as well as why they are chosen and how their use is reported. Our findings from this survey reveal significant shortcomings, including inappropriate metric usage, lack of implementation details and missing correlations with human judgements. We conclude with recommendations that we believe authors should follow to enable more rigour within the field.
factgenie: A Framework for Span-based Evaluation of Generated Texts
Jul 25, 2024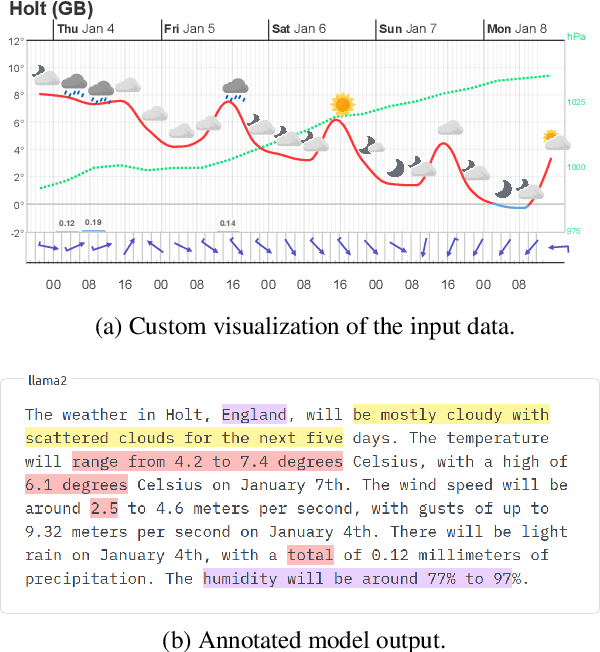
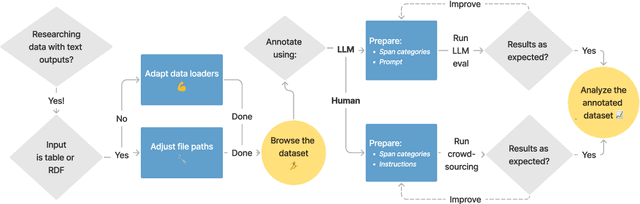
We present factgenie: a framework for annotating and visualizing word spans in textual model outputs. Annotations can capture various span-based phenomena such as semantic inaccuracies or irrelevant text. With factgenie, the annotations can be collected both from human crowdworkers and large language models. Our framework consists of a web interface for data visualization and gathering text annotations, powered by an easily extensible codebase.
With a Little Help from the Authors: Reproducing Human Evaluation of an MT Error Detector
Aug 12, 2023This work presents our efforts to reproduce the results of the human evaluation experiment presented in the paper of Vamvas and Sennrich (2022), which evaluated an automatic system detecting over- and undertranslations (translations containing more or less information than the original) in machine translation (MT) outputs. Despite the high quality of the documentation and code provided by the authors, we discuss some problems we found in reproducing the exact experimental setup and offer recommendations for improving reproducibility. Our replicated results generally confirm the conclusions of the original study, but in some cases, statistically significant differences were observed, suggesting a high variability of human annotation.
Three Ways of Using Large Language Models to Evaluate Chat
Aug 12, 2023This paper describes the systems submitted by team6 for ChatEval, the DSTC 11 Track 4 competition. We present three different approaches to predicting turn-level qualities of chatbot responses based on large language models (LLMs). We report improvement over the baseline using dynamic few-shot examples from a vector store for the prompts for ChatGPT. We also analyze the performance of the other two approaches and report needed improvements for future work. We developed the three systems over just two weeks, showing the potential of LLMs for this task. An ablation study conducted after the challenge deadline shows that the new Llama 2 models are closing the performance gap between ChatGPT and open-source LLMs. However, we find that the Llama 2 models do not benefit from few-shot examples in the same way as ChatGPT.
Missing Information, Unresponsive Authors, Experimental Flaws: The Impossibility of Assessing the Reproducibility of Previous Human Evaluations in NLP
May 02, 2023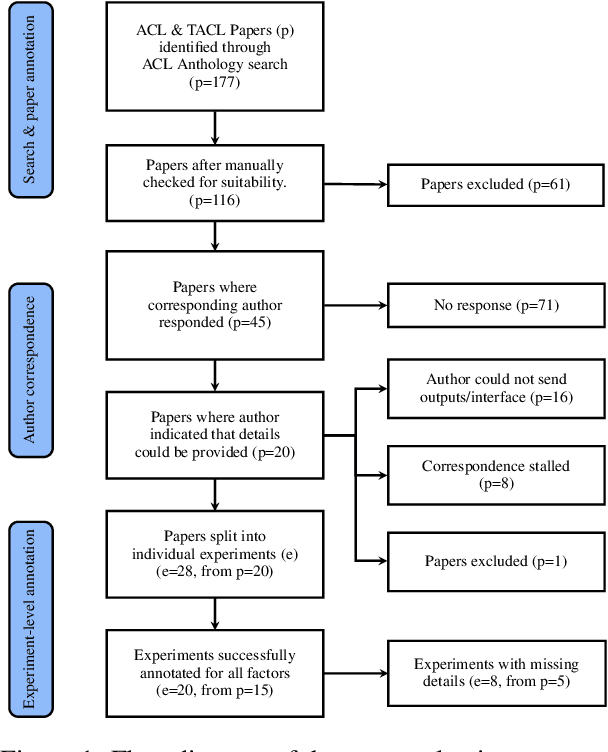
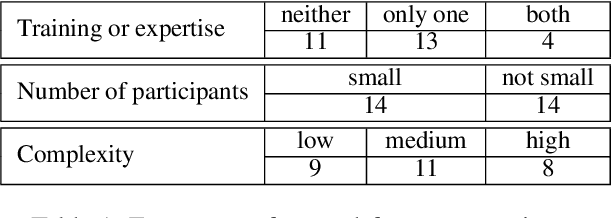


We report our efforts in identifying a set of previous human evaluations in NLP that would be suitable for a coordinated study examining what makes human evaluations in NLP more/less reproducible. We present our results and findings, which include that just 13\% of papers had (i) sufficiently low barriers to reproduction, and (ii) enough obtainable information, to be considered for reproduction, and that all but one of the experiments we selected for reproduction was discovered to have flaws that made the meaningfulness of conducting a reproduction questionable. As a result, we had to change our coordinated study design from a reproduce approach to a standardise-then-reproduce-twice approach. Our overall (negative) finding that the great majority of human evaluations in NLP is not repeatable and/or not reproducible and/or too flawed to justify reproduction, paints a dire picture, but presents an opportunity for a rethink about how to design and report human evaluations in NLP.
TabGenie: A Toolkit for Table-to-Text Generation
Feb 27, 2023Heterogenity of data-to-text generation datasets limits the research on data-to-text generation systems. We present TabGenie - a toolkit which enables researchers to explore, preprocess, and analyze a variety of data-to-text generation datasets through the unified framework of table-to-text generation. In TabGenie, all the inputs are represented as tables with associated metadata. The tables can be explored through the web interface, which also provides an interactive mode for debugging table-to-text generation, facilitates side-by-side comparison of generated system outputs, and allows easy exports for manual analysis. Furthermore, TabGenie is equipped with command line processing tools and Python bindings for unified dataset loading and processing. We release TabGenie as a PyPI package and provide its open-source code and a live demo at https://github.com/kasnerz/tabgenie.
MooseNet: A trainable metric for synthesized speech with plda backend
Jan 17, 2023We present MooseNet, a trainable speech metric that predicts listeners' Mean Opinion Score (MOS). We report improvements to the challenge baselines using easy-to-use modeling techniques, which also scales for larger self-supervised learning (SSL) model. We present two models. The first model is a Neural Network (NN). As a second model, we propose a PLDA generative model on the top layers of the first NN model, which improves the pure NN model. Ensembles from our two models achieve the top 3 or 4 VoiceMOS leaderboard places on all system and utterance level metrics.
Recurrent Neural Networks for Dialogue State Tracking
Jul 13, 2016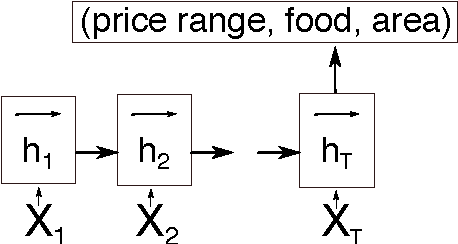

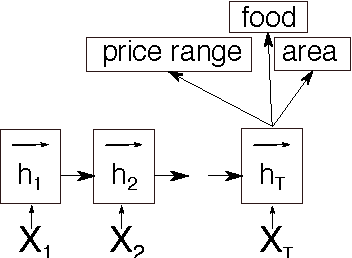

This paper discusses models for dialogue state tracking using recurrent neural networks (RNN). We present experiments on the standard dialogue state tracking (DST) dataset, DSTC2. On the one hand, RNN models became the state of the art models in DST, on the other hand, most state-of-the-art models are only turn-based and require dataset-specific preprocessing (e.g. DSTC2-specific) in order to achieve such results. We implemented two architectures which can be used in incremental settings and require almost no preprocessing. We compare their performance to the benchmarks on DSTC2 and discuss their properties. With only trivial preprocessing, the performance of our models is close to the state-of- the-art results.