 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Generation for Czech: Data and Baselines
Oct 11, 2019



We present the first dataset targeted at end-to-end NLG in Czech in the restaurant domain, along with several strong baseline models using the sequence-to-sequence approach. While non-English NLG is under-explored in general, Czech, as a morphologically rich language, makes the task even harder: Since Czech requires inflecting named entities, delexicalization or copy mechanisms do not work out-of-the-box and lexicalizing the generated outputs is non-trivial. In our experiments, we present two different approaches to this this problem: (1) using a neural language model to select the correct inflected form while lexicalizing, (2) a two-step generation setup: our sequence-to-sequence model generates an interleaved sequence of lemmas and morphological tags, which are then inflected by a morphological generator.
Denotation Extraction for Interactive Learning in Dialogue Systems
Jan 09, 2018
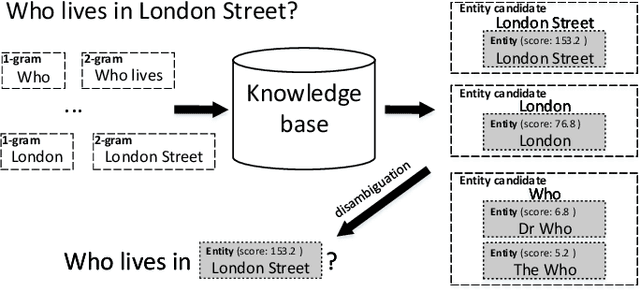
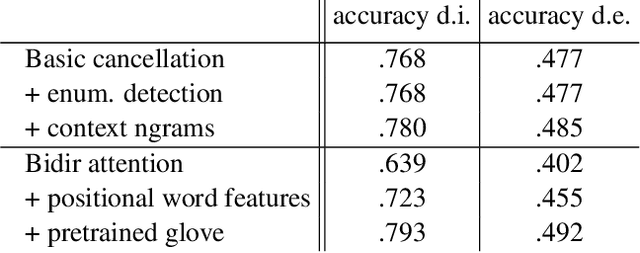
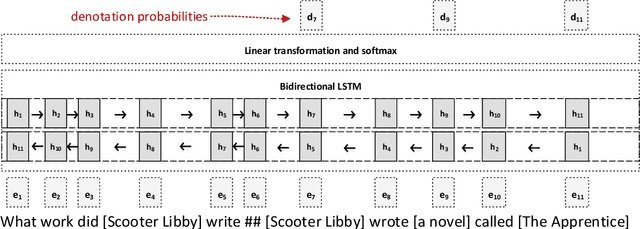
This paper presents a novel task using real user data obtained in human-machine conversation. The task concerns with denotation extraction from answer hints collected interactively in a dialogue. The task is motivated by the need for large amounts of training data for question answering dialogue system development, where the data is often expensive and hard to collect. Being able to collect denotation interactively and directly from users, one could improve, for example, natural understanding components on-line and ease the collection of the training data. This paper also presents introductory results of evaluation of several denotation extraction models including attention-based neural network approaches.
A Context-aware Natural Language Generator for Dialogue Systems
Aug 25, 2016



We present a novel natural language generation system for spoken dialogue systems capable of entraining (adapting) to users' way of speaking, providing contextually appropriate responses. The generator is based on recurrent neural networks and the sequence-to-sequence approach. It is fully trainable from data which include preceding context along with responses to be generated. We show that the context-aware generator yields significant improvements over the baseline in both automatic metrics and a human pairwise preference test.
* Accepted as a short paper for SIGDIAL 2016
Recurrent Neural Networks for Dialogue State Tracking
Jul 13, 2016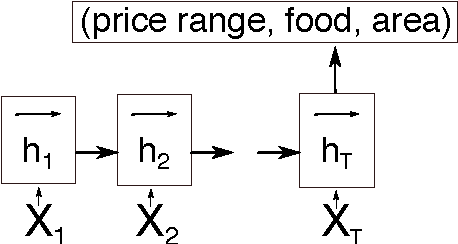

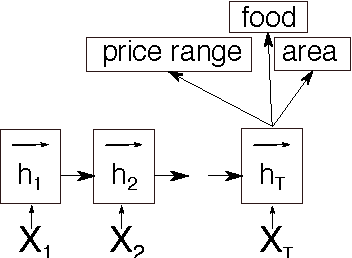

This paper discusses models for dialogue state tracking using recurrent neural networks (RNN). We present experiments on the standard dialogue state tracking (DST) dataset, DSTC2. On the one hand, RNN models became the state of the art models in DST, on the other hand, most state-of-the-art models are only turn-based and require dataset-specific preprocessing (e.g. DSTC2-specific) in order to achieve such results. We implemented two architectures which can be used in incremental settings and require almost no preprocessing. We compare their performance to the benchmarks on DSTC2 and discuss their properties. With only trivial preprocessing, the performance of our models is close to the state-of- the-art results.
Sequence-to-Sequence Generation for Spoken Dialogue via Deep Syntax Trees and Strings
Jun 17, 2016



We present a natural language generator based on the sequence-to-sequence approach that can be trained to produce natural language strings as well as deep syntax dependency trees from input dialogue acts, and we use it to directly compare two-step generation with separate sentence planning and surface realization stages to a joint, one-step approach. We were able to train both setups successfully using very little training data. The joint setup offers better performance, surpassing state-of-the-art with regards to n-gram-based scores while providing more relevant outputs.
* Accepted as a short paper for ACL 2016
Data Collection for Interactive Learning through the Dialog
May 15, 2016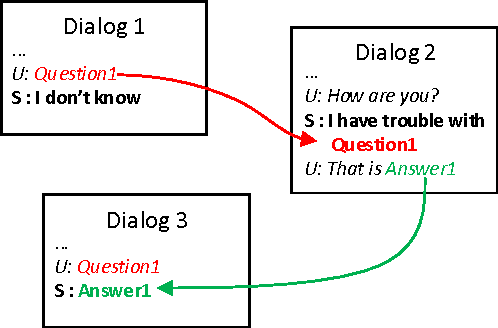
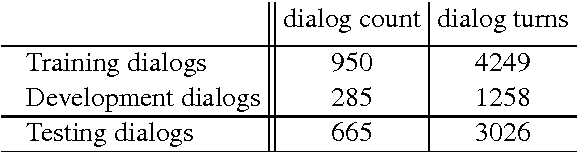
This paper presents a dataset collected from natural dialogs which enables to test the ability of dialog systems to learn new facts from user utterances throughout the dialog. This interactive learning will help with one of the most prevailing problems of open domain dialog system, which is the sparsity of facts a dialog system can reason about. The proposed dataset, consisting of 1900 collected dialogs, allows simulation of an interactive gaining of denotations and questions explanations from users which can be used for the interactive learning.