 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree Ways of Using Large Language Models to Evaluate Chat
Aug 12, 2023This paper describes the systems submitted by team6 for ChatEval, the DSTC 11 Track 4 competition. We present three different approaches to predicting turn-level qualities of chatbot responses based on large language models (LLMs). We report improvement over the baseline using dynamic few-shot examples from a vector store for the prompts for ChatGPT. We also analyze the performance of the other two approaches and report needed improvements for future work. We developed the three systems over just two weeks, showing the potential of LLMs for this task. An ablation study conducted after the challenge deadline shows that the new Llama 2 models are closing the performance gap between ChatGPT and open-source LLMs. However, we find that the Llama 2 models do not benefit from few-shot examples in the same way as ChatGPT.
Are LLMs All You Need for Task-Oriented Dialogue?
Apr 13, 2023



Instructions-tuned Large Language Models (LLMs) gained recently huge popularity thanks to their ability to interact with users through conversation. In this work we aim to evaluate their ability to complete multi-turn tasks and interact with external databases in the context of established task-oriented dialogue benchmarks. We show that for explicit belief state tracking, LLMs underperform compared to specialized task-specific models. Nevertheless, they show ability to guide the dialogue to successful ending if given correct slot values. Furthermore this ability improves with access to true belief state distribution or in-domain examples.
Learning Interpretable Latent Dialogue Actions With Less Supervision
Sep 23, 2022



We present a novel architecture for explainable modeling of task-oriented dialogues with discrete latent variables to represent dialogue actions. Our model is based on variational recurrent neural networks (VRNN) and requires no explicit annotation of semantic information. Unlike previous works, our approach models the system and user turns separately and performs database query modeling, which makes the model applicable to task-oriented dialogues while producing easily interpretable action latent variables. We show that our model outperforms previous approaches with less supervision in terms of perplexity and BLEU on three datasets, and we propose a way to measure dialogue success without the need for expert annotation. Finally, we propose a novel way to explain semantics of the latent variables with respect to system actions.
AuGPT: Dialogue with Pre-trained Language Models and Data Augmentation
Feb 09, 2021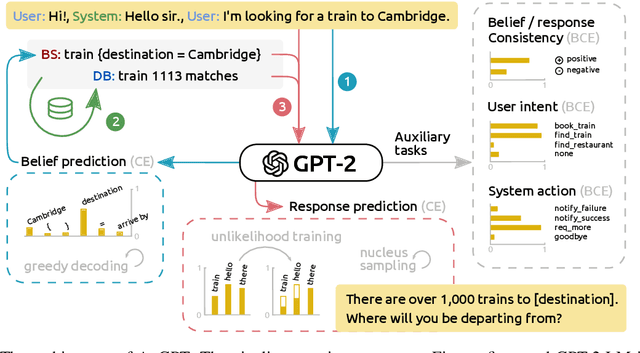
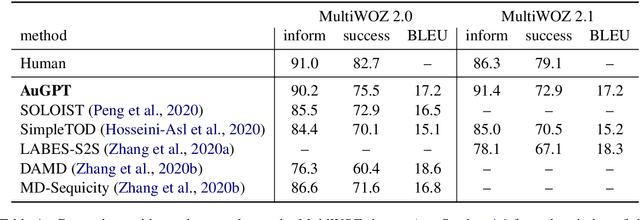
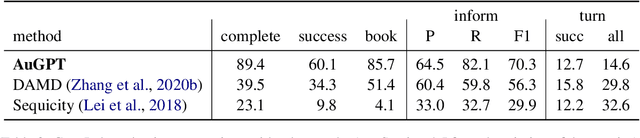
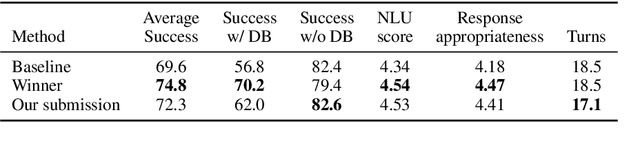
Attention-based pre-trained language models such as GPT-2 brought considerable progress to end-to-end dialogue modelling. However, they also present considerable risks for task-oriented dialogue, such as lack of knowledge grounding or diversity. To address these issues, we introduce modified training objectives for language model finetuning, and we employ massive data augmentation via back-translation to increase the diversity of the training data. We further examine the possibilities of combining data from multiples sources to improve performance on the target dataset. We carefully evaluate our contributions with both human and automatic methods. Our model achieves state-of-the-art performance on the MultiWOZ data and shows competitive performance in human evaluation.
Recurrent Neural Networks for Dialogue State Tracking
Jul 13, 2016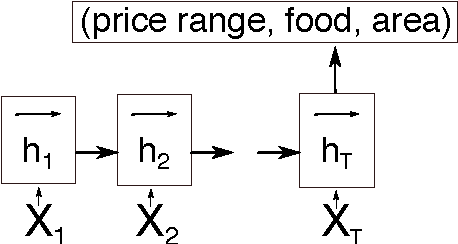

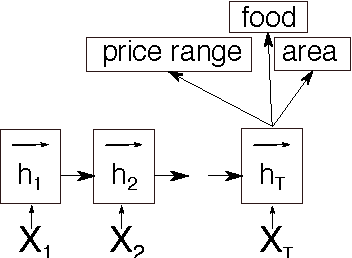

This paper discusses models for dialogue state tracking using recurrent neural networks (RNN). We present experiments on the standard dialogue state tracking (DST) dataset, DSTC2. On the one hand, RNN models became the state of the art models in DST, on the other hand, most state-of-the-art models are only turn-based and require dataset-specific preprocessing (e.g. DSTC2-specific) in order to achieve such results. We implemented two architectures which can be used in incremental settings and require almost no preprocessing. We compare their performance to the benchmarks on DSTC2 and discuss their properties. With only trivial preprocessing, the performance of our models is close to the state-of- the-art results.