 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Metrics in Natural Language Generation: A Survey of Current Evaluation Practices
Aug 17, 2024
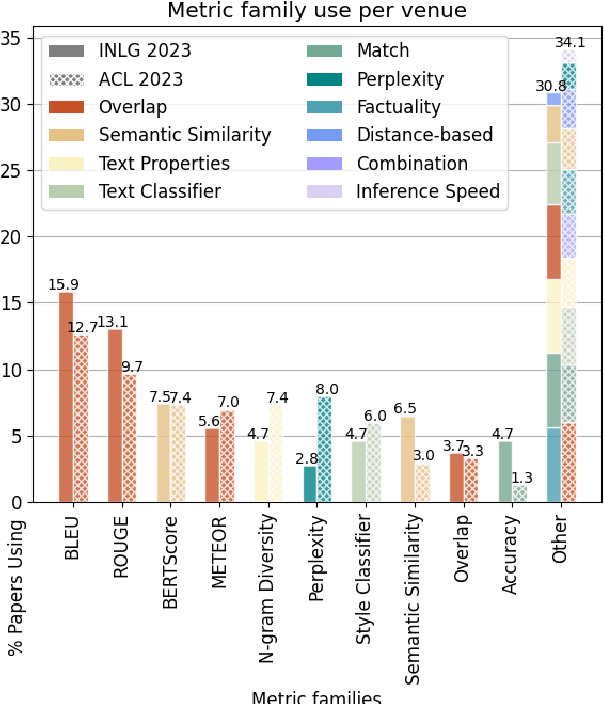
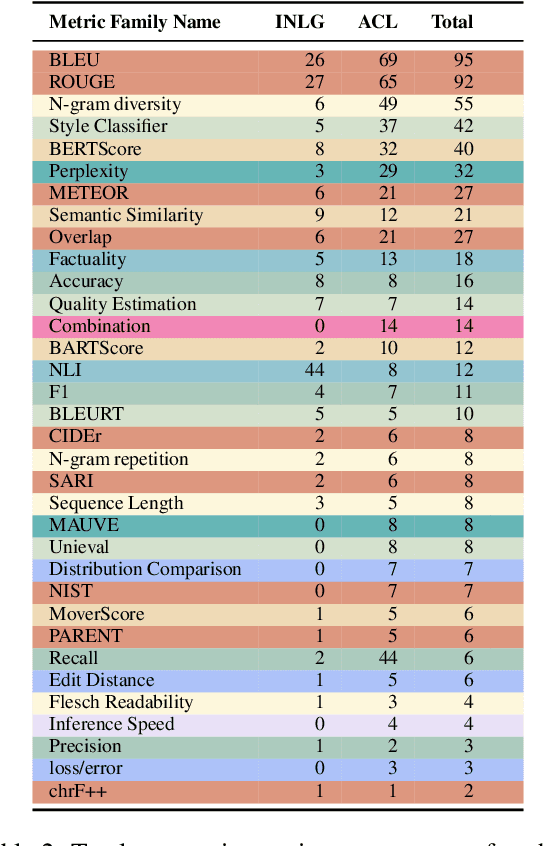
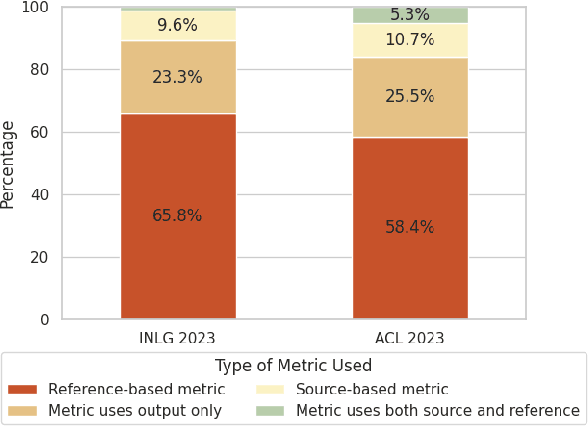
Automatic metrics are extensively used to evaluate natural language processing systems. However, there has been increasing focus on how they are used and reported by practitioners within the field. In this paper, we have conducted a survey on the use of automatic metrics, focusing particularly on natural language generation (NLG) tasks. We inspect which metrics are used as well as why they are chosen and how their use is reported. Our findings from this survey reveal significant shortcomings, including inappropriate metric usage, lack of implementation details and missing correlations with human judgements. We conclude with recommendations that we believe authors should follow to enable more rigour within the field.
OTTers: One-turn Topic Transitions for Open-Domain Dialogue
May 28, 2021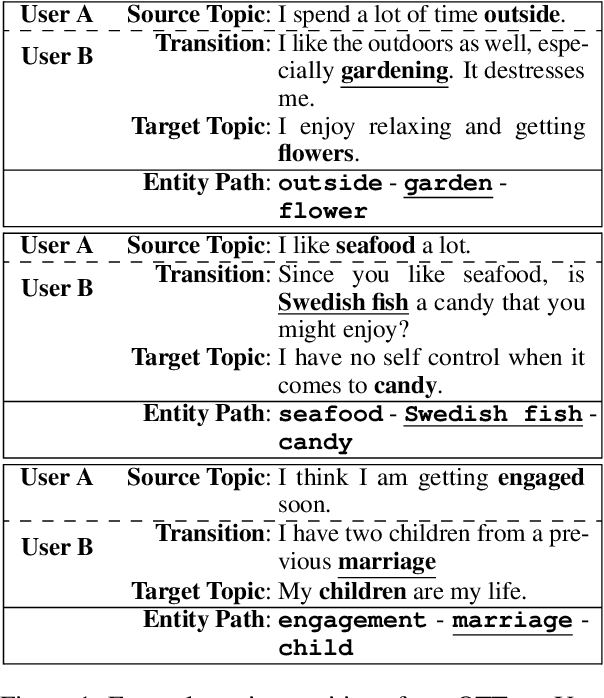



Mixed initiative in open-domain dialogue requires a system to pro-actively introduce new topics. The one-turn topic transition task explores how a system connects two topics in a cooperative and coherent manner. The goal of the task is to generate a "bridging" utterance connecting the new topic to the topic of the previous conversation turn. We are especially interested in commonsense explanations of how a new topic relates to what has been mentioned before. We first collect a new dataset of human one-turn topic transitions, which we call OTTers. We then explore different strategies used by humans when asked to complete such a task, and notice that the use of a bridging utterance to connect the two topics is the approach used the most. We finally show how existing state-of-the-art text generation models can be adapted to this task and examine the performance of these baselines on different splits of the OTTers data.
Semantic Noise Matters for Neural Natural Language Generation
Nov 10, 2019
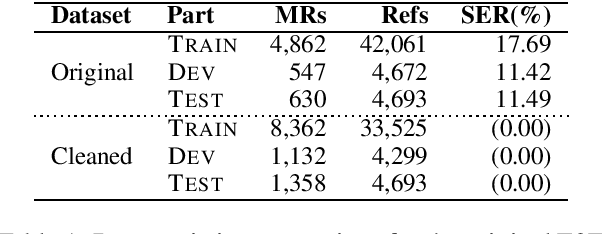


Neural natural language generation (NNLG) systems are known for their pathological outputs, i.e. generating text which is unrelated to the input specification. In this paper, we show the impact of semantic noise on state-of-the-art NNLG models which implement different semantic control mechanisms. We find that cleaned data can improve semantic correctness by up to 97%, while maintaining fluency. We also find that the most common error is omitting information, rather than hallucination.