 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Metrics in Natural Language Generation: A Survey of Current Evaluation Practices
Aug 17, 2024
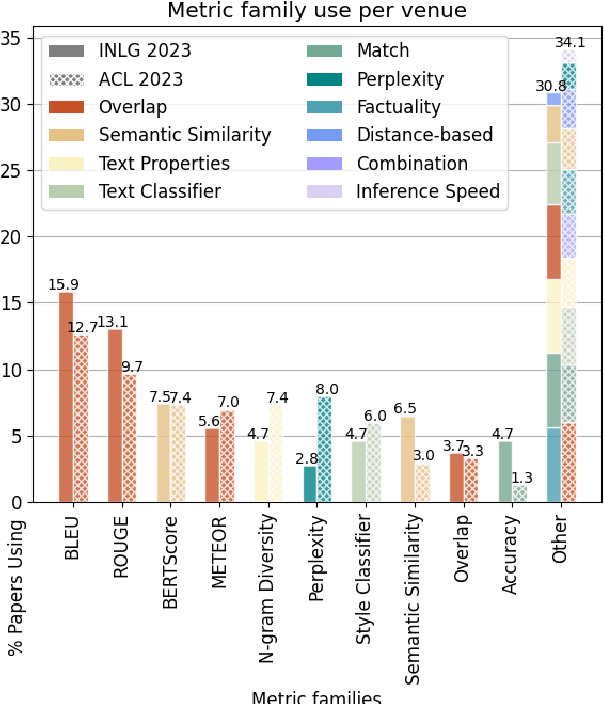
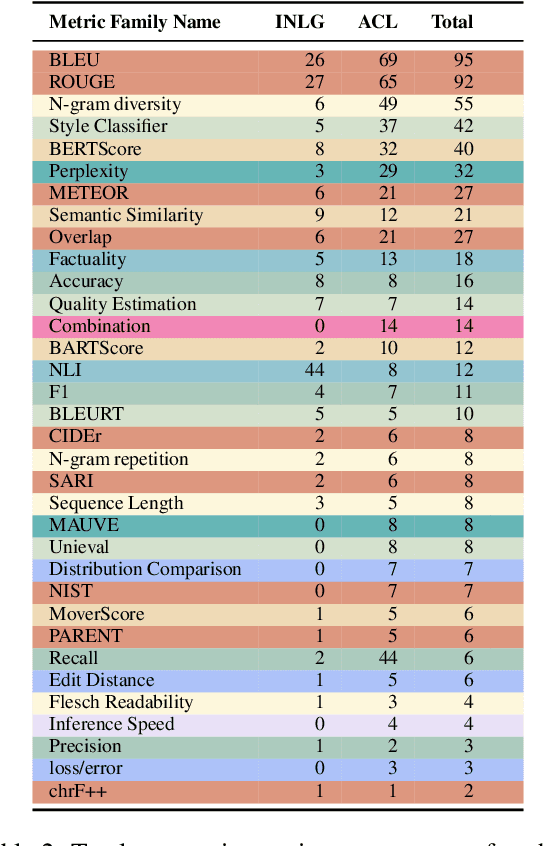
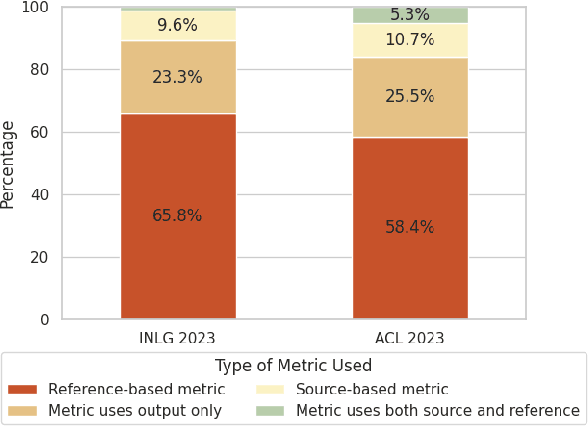
Automatic metrics are extensively used to evaluate natural language processing systems. However, there has been increasing focus on how they are used and reported by practitioners within the field. In this paper, we have conducted a survey on the use of automatic metrics, focusing particularly on natural language generation (NLG) tasks. We inspect which metrics are used as well as why they are chosen and how their use is reported. Our findings from this survey reveal significant shortcomings, including inappropriate metric usage, lack of implementation details and missing correlations with human judgements. We conclude with recommendations that we believe authors should follow to enable more rigour within the field.
Linguistically Communicating Uncertainty in Patient-Facing Risk Prediction Models
Jan 31, 2024



This paper addresses the unique challenges associated with uncertainty quantification in AI models when applied to patient-facing contexts within healthcare. Unlike traditional eXplainable Artificial Intelligence (XAI) methods tailored for model developers or domain experts, additional considerations of communicating in natural language, its presentation and evaluating understandability are necessary. We identify the challenges in communication model performance, confidence, reasoning and unknown knowns using natural language in the context of risk prediction. We propose a design aimed at addressing these challenges, focusing on the specific application of in-vitro fertilisation outcome prediction.
Evaluation of Human-Understandability of Global Model Explanations using Decision Tree
Sep 18, 2023In explainable artificial intelligence (XAI) research, the predominant focus has been on interpreting models for experts and practitioners. Model agnostic and local explanation approaches are deemed interpretable and sufficient in many applications. However, in domains like healthcare, where end users are patients without AI or domain expertise, there is an urgent need for model explanations that are more comprehensible and instil trust in the model's operations. We hypothesise that generating model explanations that are narrative, patient-specific and global(holistic of the model) would enable better understandability and enable decision-making. We test this using a decision tree model to generate both local and global explanations for patients identified as having a high risk of coronary heart disease. These explanations are presented to non-expert users. We find a strong individual preference for a specific type of explanation. The majority of participants prefer global explanations, while a smaller group prefers local explanations. A task based evaluation of mental models of these participants provide valuable feedback to enhance narrative global explanations. This, in turn, guides the design of health informatics systems that are both trustworthy and actionable.