 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Harry Meets Superman: The Role of The Interlocutor in Persona-Based Dialogue Generation
May 30, 2025Endowing dialogue agents with persona information has proven to significantly improve the consistency and diversity of their generations. While much focus has been placed on aligning dialogues with provided personas, the adaptation to the interlocutor's profile remains largely underexplored. In this work, we investigate three key aspects: (1) a model's ability to align responses with both the provided persona and the interlocutor's; (2) its robustness when dealing with familiar versus unfamiliar interlocutors and topics, and (3) the impact of additional fine-tuning on specific persona-based dialogues. We evaluate dialogues generated with diverse speaker pairings and topics, framing the evaluation as an author identification task and employing both LLM-as-a-judge and human evaluations. By systematically masking or disclosing information about the interlocutor, we assess its impact on dialogue generation. Results show that access to the interlocutor's persona improves the recognition of the target speaker, while masking it does the opposite. Although models generalise well across topics, they struggle with unfamiliar interlocutors. Finally, we found that in zero-shot settings, LLMs often copy biographical details, facilitating identification but trivialising the task.
Fine-tuning with HED-IT: The impact of human post-editing for dialogical language models
Jun 11, 2024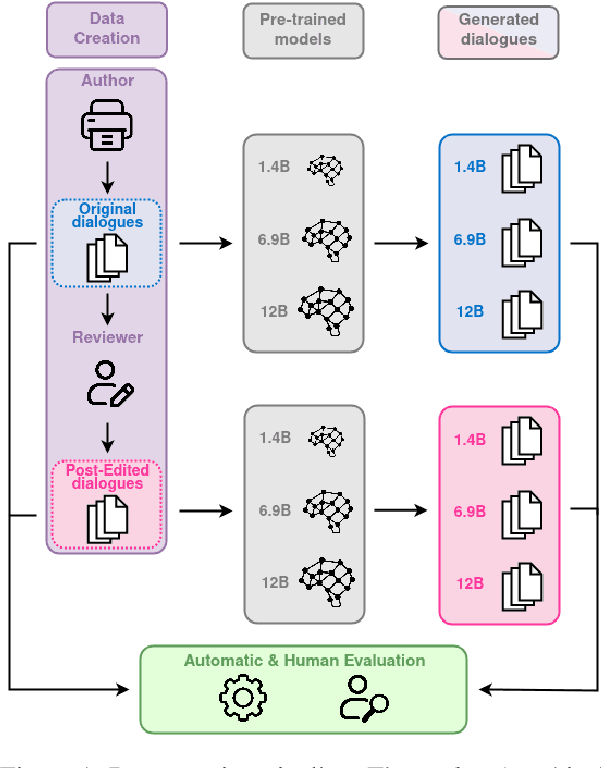

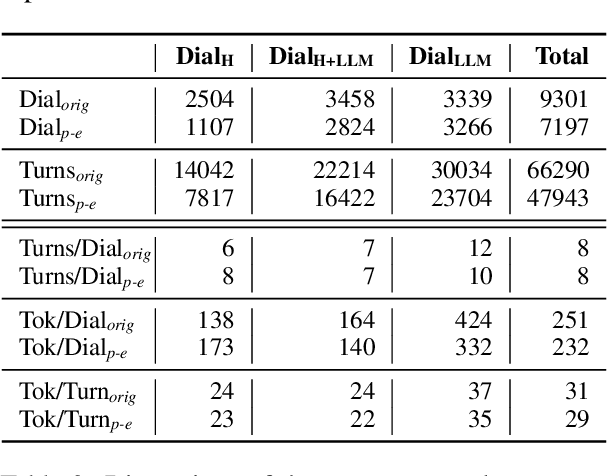

Automatic methods for generating and gathering linguistic data have proven effective for fine-tuning Language Models (LMs) in languages less resourced than English. Still, while there has been emphasis on data quantity, less attention has been given to its quality. In this work, we investigate the impact of human intervention on machine-generated data when fine-tuning dialogical models. In particular, we study (1) whether post-edited dialogues exhibit higher perceived quality compared to the originals that were automatically generated; (2) whether fine-tuning with post-edited dialogues results in noticeable differences in the generated outputs; and (3) whether post-edited dialogues influence the outcomes when considering the parameter size of the LMs. To this end we created HED-IT, a large-scale dataset where machine-generated dialogues are paired with the version post-edited by humans. Using both the edited and unedited portions of HED-IT, we fine-tuned three different sizes of an LM. Results from both human and automatic evaluation show that the different quality of training data is clearly perceived and it has an impact also on the models trained on such data. Additionally, our findings indicate that larger models are less sensitive to data quality, whereas this has a crucial impact on smaller models. These results enhance our comprehension of the impact of human intervention on training data in the development of high-quality LMs.
PRODIGy: a PROfile-based DIalogue Generation dataset
Nov 09, 2023
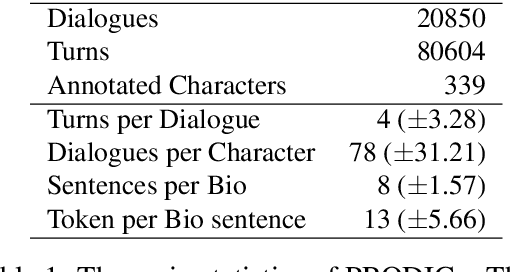


Providing dialogue agents with a profile representation can improve their consistency and coherence, leading to better conversations. However, current profile-based dialogue datasets for training such agents contain either explicit profile representations that are simple and dialogue-specific, or implicit representations that are difficult to collect. In this work, we propose a unified framework in which we bring together both standard and more sophisticated profile representations by creating a new resource where each dialogue is aligned with all possible speaker representations such as communication style, biographies, and personality. This framework allows to test several baselines built using generative language models with several profile configurations. The automatic evaluation shows that profile-based models have better generalisation capabilities than models trained on dialogues only, both in-domain and cross-domain settings. These results are consistent for fine-tuned models and instruction-based LLMs. Additionally, human evaluation demonstrates a clear preference for generations consistent with both profile and context. Finally, to account for possible privacy concerns, all experiments are done under two configurations: inter-character and intra-character. In the former, the LM stores the information about the character in its internal representation, while in the latter, the LM does not retain any personal information but uses it only at inference time.