 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Growing Gains and Pains of Iterative Web Corpora Crawling: Insights from South Slavic CLASSLA-web 2.0 Corpora
Jan 16, 2026Crawling national top-level domains has proven to be highly effective for collecting texts in less-resourced languages. This approach has been recently used for South Slavic languages and resulted in the largest general corpora for this language group: the CLASSLA-web 1.0 corpora. Building on this success, we established a continuous crawling infrastructure for iterative national top-level domain crawling across South Slavic and related webs. We present the first outcome of this crawling infrastructure - the CLASSLA-web 2.0 corpus collection, with substantially larger web corpora containing 17.0 billion words in 38.1 million texts in seven languages: Bosnian, Bulgarian, Croatian, Macedonian, Montenegrin, Serbian, and Slovenian. In addition to genre categories, the new version is also automatically annotated with topic labels. Comparing CLASSLA-web 2.0 with its predecessor reveals that only one-fifth of the texts overlap, showing that re-crawling after just two years yields largely new content. However, while the new web crawls bring growing gains, we also notice growing pains - a manual inspection of top domains reveals a visible degradation of web content, as machine-generated sites now contribute a significant portion of texts.
Language Models on a Diet: Cost-Efficient Development of Encoders for Closely-Related Languages via Additional Pretraining
Apr 08, 2024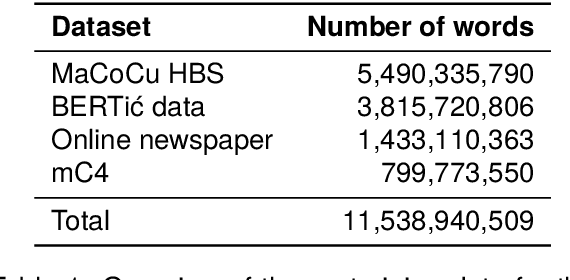
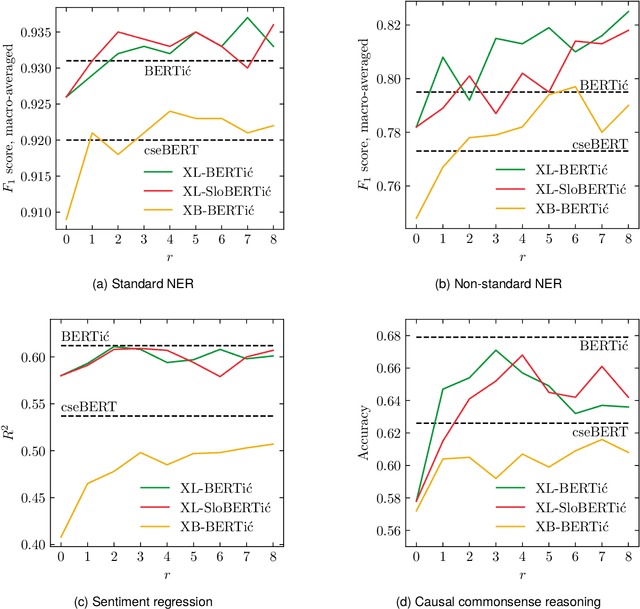
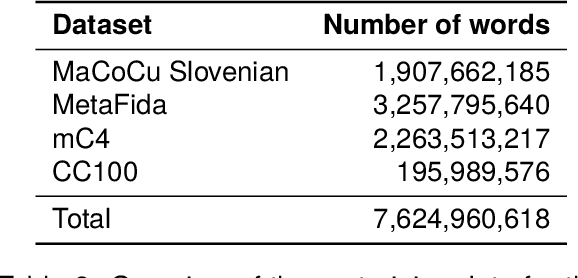

The world of language models is going through turbulent times, better and ever larger models are coming out at an unprecedented speed. However, we argue that, especially for the scientific community, encoder models of up to 1 billion parameters are still very much needed, their primary usage being in enriching large collections of data with metadata necessary for downstream research. We investigate the best way to ensure the existence of such encoder models on the set of very closely related languages - Croatian, Serbian, Bosnian and Montenegrin, by setting up a diverse benchmark for these languages, and comparing the trained-from-scratch models with the new models constructed via additional pretraining of existing multilingual models. We show that comparable performance to dedicated from-scratch models can be obtained by additionally pretraining available multilingual models even with a limited amount of computation. We also show that neighboring languages, in our case Slovenian, can be included in the additional pretraining with little to no loss in the performance of the final model.