 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMići Princ -- A Little Boy Teaching Speech Technologies the Chakavian Dialect
Feb 03, 2026This paper documents our efforts in releasing the printed and audio book of the translation of the famous novel The Little Prince into the Chakavian dialect, as a computer-readable, AI-ready dataset, with the textual and the audio components of the two releases now aligned on the level of each written and spoken word. Our motivation for working on this release is multiple. The first one is our wish to preserve the highly valuable and specific content beyond the small editions of the printed and the audio book. With the dataset published in the CLARIN.SI repository, this content is from now on at the fingertips of any interested individual. The second motivation is to make the data available for various artificial-intelligence-related usage scenarios, such as the one we follow upon inside this paper already -- adapting the Whisper-large-v3 open automatic speech recognition model, with decent performance on standard Croatian, to Chakavian dialectal speech. We can happily report that with adapting the model, the word error rate on the selected test data has being reduced to a half, while we managed to remove up to two thirds of the error on character level. We envision many more usages of this dataset beyond the set of experiments we have already performed, both on tasks of artificial intelligence research and application, as well as dialectal research. The third motivation for this release is our hope that this, now highly structured dataset, will be transformed into a digital online edition of this work, allowing individuals beyond the research and technology communities to enjoy the beauty of the message of the little boy in the desert, told through the spectacular prism of the Chakavian dialect.
The Growing Gains and Pains of Iterative Web Corpora Crawling: Insights from South Slavic CLASSLA-web 2.0 Corpora
Jan 16, 2026Crawling national top-level domains has proven to be highly effective for collecting texts in less-resourced languages. This approach has been recently used for South Slavic languages and resulted in the largest general corpora for this language group: the CLASSLA-web 1.0 corpora. Building on this success, we established a continuous crawling infrastructure for iterative national top-level domain crawling across South Slavic and related webs. We present the first outcome of this crawling infrastructure - the CLASSLA-web 2.0 corpus collection, with substantially larger web corpora containing 17.0 billion words in 38.1 million texts in seven languages: Bosnian, Bulgarian, Croatian, Macedonian, Montenegrin, Serbian, and Slovenian. In addition to genre categories, the new version is also automatically annotated with topic labels. Comparing CLASSLA-web 2.0 with its predecessor reveals that only one-fifth of the texts overlap, showing that re-crawling after just two years yields largely new content. However, while the new web crawls bring growing gains, we also notice growing pains - a manual inspection of top domains reveals a visible degradation of web content, as machine-generated sites now contribute a significant portion of texts.
State of the Art in Text Classification for South Slavic Languages: Fine-Tuning or Prompting?
Nov 11, 2025Until recently, fine-tuned BERT-like models provided state-of-the-art performance on text classification tasks. With the rise of instruction-tuned decoder-only models, commonly known as large language models (LLMs), the field has increasingly moved toward zero-shot and few-shot prompting. However, the performance of LLMs on text classification, particularly on less-resourced languages, remains under-explored. In this paper, we evaluate the performance of current language models on text classification tasks across several South Slavic languages. We compare openly available fine-tuned BERT-like models with a selection of open-source and closed-source LLMs across three tasks in three domains: sentiment classification in parliamentary speeches, topic classification in news articles and parliamentary speeches, and genre identification in web texts. Our results show that LLMs demonstrate strong zero-shot performance, often matching or surpassing fine-tuned BERT-like models. Moreover, when used in a zero-shot setup, LLMs perform comparably in South Slavic languages and English. However, we also point out key drawbacks of LLMs, including less predictable outputs, significantly slower inference, and higher computational costs. Due to these limitations, fine-tuned BERT-like models remain a more practical choice for large-scale automatic text annotation.
Identifying Primary Stress Across Related Languages and Dialects with Transformer-based Speech Encoder Models
May 30, 2025



Automating primary stress identification has been an active research field due to the role of stress in encoding meaning and aiding speech comprehension. Previous studies relied mainly on traditional acoustic features and English datasets. In this paper, we investigate the approach of fine-tuning a pre-trained transformer model with an audio frame classification head. Our experiments use a new Croatian training dataset, with test sets in Croatian, Serbian, the Chakavian dialect, and Slovenian. By comparing an SVM classifier using traditional acoustic features with the fine-tuned speech transformer, we demonstrate the transformer's superiority across the board, achieving near-perfect results for Croatian and Serbian, with a 10-point performance drop for the more distant Chakavian and Slovenian. Finally, we show that only a few hundred multi-syllabic training words suffice for strong performance. We release our datasets and model under permissive licenses.
Language Models on a Diet: Cost-Efficient Development of Encoders for Closely-Related Languages via Additional Pretraining
Apr 08, 2024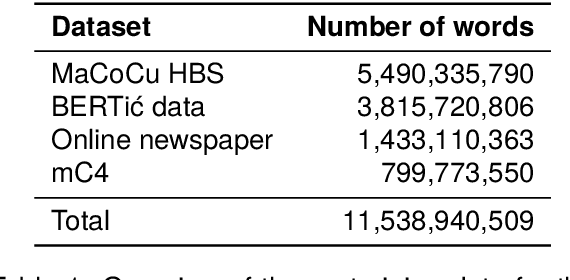
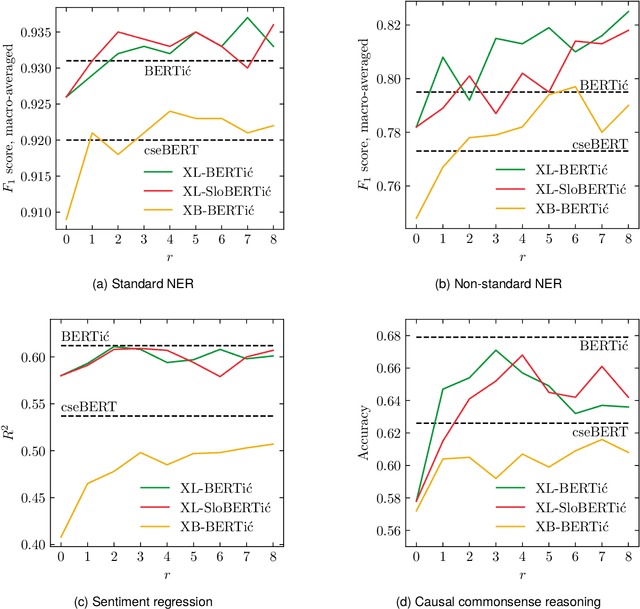
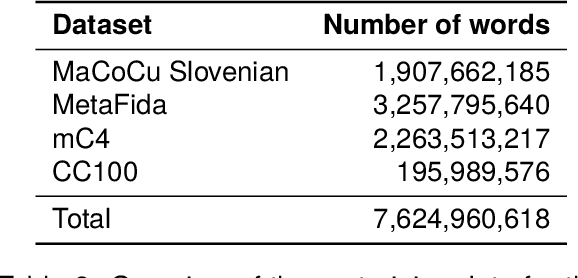

The world of language models is going through turbulent times, better and ever larger models are coming out at an unprecedented speed. However, we argue that, especially for the scientific community, encoder models of up to 1 billion parameters are still very much needed, their primary usage being in enriching large collections of data with metadata necessary for downstream research. We investigate the best way to ensure the existence of such encoder models on the set of very closely related languages - Croatian, Serbian, Bosnian and Montenegrin, by setting up a diverse benchmark for these languages, and comparing the trained-from-scratch models with the new models constructed via additional pretraining of existing multilingual models. We show that comparable performance to dedicated from-scratch models can be obtained by additionally pretraining available multilingual models even with a limited amount of computation. We also show that neighboring languages, in our case Slovenian, can be included in the additional pretraining with little to no loss in the performance of the final model.
Do Language Models Care About Text Quality? Evaluating Web-Crawled Corpora Across 11 Languages
Mar 13, 2024Large, curated, web-crawled corpora play a vital role in training language models (LMs). They form the lion's share of the training data in virtually all recent LMs, such as the well-known GPT, LLaMA and XLM-RoBERTa models. However, despite this importance, relatively little attention has been given to the quality of these corpora. In this paper, we compare four of the currently most relevant large, web-crawled corpora (CC100, MaCoCu, mC4 and OSCAR) across eleven lower-resourced European languages. Our approach is two-fold: first, we perform an intrinsic evaluation by performing a human evaluation of the quality of samples taken from different corpora; then, we assess the practical impact of the qualitative differences by training specific LMs on each of the corpora and evaluating their performance on downstream tasks. We find that there are clear differences in quality of the corpora, with MaCoCu and OSCAR obtaining the best results. However, during the extrinsic evaluation, we actually find that the CC100 corpus achieves the highest scores. We conclude that, in our experiments, the quality of the web-crawled corpora does not seem to play a significant role when training LMs.
The ParlaSent multilingual training dataset for sentiment identification in parliamentary proceedings
Sep 18, 2023Sentiments inherently drive politics. How we receive and process information plays an essential role in political decision-making, shaping our judgment with strategic consequences both on the level of legislators and the masses. If sentiment plays such an important role in politics, how can we study and measure it systematically? The paper presents a new dataset of sentiment-annotated sentences, which are used in a series of experiments focused on training a robust sentiment classifier for parliamentary proceedings. The paper also introduces the first domain-specific LLM for political science applications additionally pre-trained on 1.72 billion domain-specific words from proceedings of 27 European parliaments. We present experiments demonstrating how the additional pre-training of LLM on parliamentary data can significantly improve the model downstream performance on the domain-specific tasks, in our case, sentiment detection in parliamentary proceedings. We further show that multilingual models perform very well on unseen languages and that additional data from other languages significantly improves the target parliament's results. The paper makes an important contribution to multiple domains of social sciences and bridges them with computer science and computational linguistics. Lastly, it sets up a more robust approach to sentiment analysis of political texts in general, which allows scholars to study political sentiment from a comparative perspective using standardized tools and techniques.
The ParlaSent-BCS dataset of sentiment-annotated parliamentary debates from Bosnia-Herzegovina, Croatia, and Serbia
Jun 02, 2022

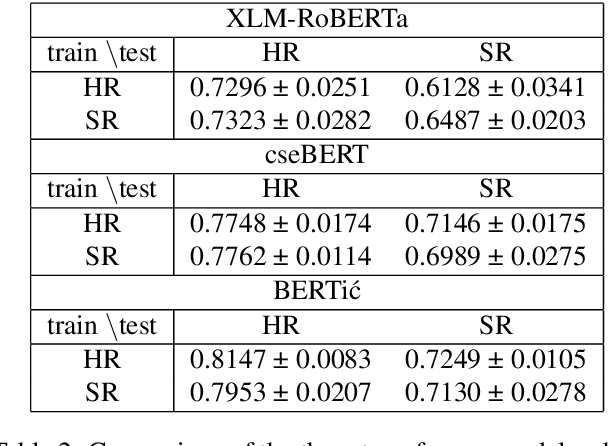

Expression of sentiment in parliamentary debates is deemed to be significantly different from that on social media or in product reviews. This paper adds to an emerging body of research on parliamentary debates with a dataset of sentences annotated for detection sentiment polarity in political discourse. We sample the sentences for annotation from the proceedings of three Southeast European parliaments: Croatia, Bosnia-Herzegovina, and Serbia. A six-level schema is applied to the data with the aim of training a classification model for the detection of sentiment in parliamentary proceedings. Krippendorff's alpha measuring the inter-annotator agreement ranges from 0.6 for the six-level annotation schema to 0.75 for the three-level schema and 0.83 for the two-level schema. Our initial experiments on the dataset show that transformer models perform significantly better than those using a simpler architecture. Furthermore, regardless of the similarity of the three languages, we observe differences in performance across different languages. Performing parliament-specific training and evaluation shows that the main reason for the differing performance between parliaments seems to be the different complexity of the automatic classification task, which is not observable in annotator performance. Language distance does not seem to play any role neither in annotator nor in automatic classification performance. We release the dataset and the best-performing model under permissive licences.
The GINCO Training Dataset for Web Genre Identification of Documents Out in the Wild
Jan 11, 2022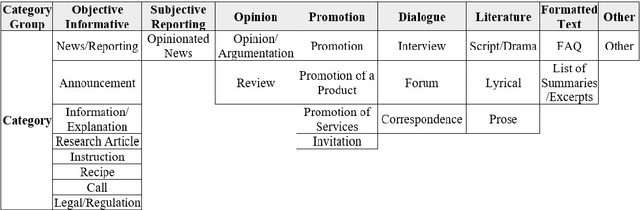

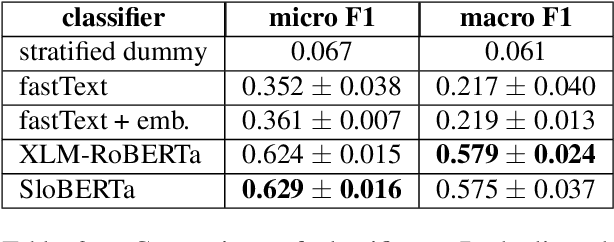

This paper presents a new training dataset for automatic genre identification GINCO, which is based on 1,125 crawled Slovenian web documents that consist of 650 thousand words. Each document was manually annotated for genre with a new annotation schema that builds upon existing schemata, having primarily clarity of labels and inter-annotator agreement in mind. The dataset consists of various challenges related to web-based data, such as machine translated content, encoding errors, multiple contents presented in one document etc., enabling evaluation of classifiers in realistic conditions. The initial machine learning experiments on the dataset show that (1) pre-Transformer models are drastically less able to model the phenomena, with macro F1 metrics ranging around 0.22, while Transformer-based models achieve scores of around 0.58, and (2) multilingual Transformer models work as well on the task as the monolingual models that were previously proven to be superior to multilingual models on standard NLP tasks.