 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe ParlaSent multilingual training dataset for sentiment identification in parliamentary proceedings
Sep 18, 2023Sentiments inherently drive politics. How we receive and process information plays an essential role in political decision-making, shaping our judgment with strategic consequences both on the level of legislators and the masses. If sentiment plays such an important role in politics, how can we study and measure it systematically? The paper presents a new dataset of sentiment-annotated sentences, which are used in a series of experiments focused on training a robust sentiment classifier for parliamentary proceedings. The paper also introduces the first domain-specific LLM for political science applications additionally pre-trained on 1.72 billion domain-specific words from proceedings of 27 European parliaments. We present experiments demonstrating how the additional pre-training of LLM on parliamentary data can significantly improve the model downstream performance on the domain-specific tasks, in our case, sentiment detection in parliamentary proceedings. We further show that multilingual models perform very well on unseen languages and that additional data from other languages significantly improves the target parliament's results. The paper makes an important contribution to multiple domains of social sciences and bridges them with computer science and computational linguistics. Lastly, it sets up a more robust approach to sentiment analysis of political texts in general, which allows scholars to study political sentiment from a comparative perspective using standardized tools and techniques.
The ParlaSent-BCS dataset of sentiment-annotated parliamentary debates from Bosnia-Herzegovina, Croatia, and Serbia
Jun 02, 2022

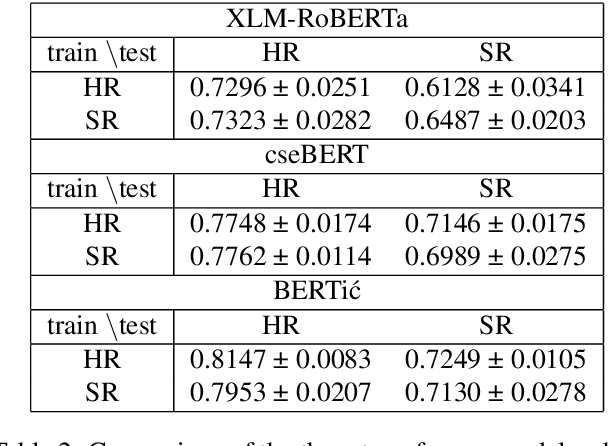

Expression of sentiment in parliamentary debates is deemed to be significantly different from that on social media or in product reviews. This paper adds to an emerging body of research on parliamentary debates with a dataset of sentences annotated for detection sentiment polarity in political discourse. We sample the sentences for annotation from the proceedings of three Southeast European parliaments: Croatia, Bosnia-Herzegovina, and Serbia. A six-level schema is applied to the data with the aim of training a classification model for the detection of sentiment in parliamentary proceedings. Krippendorff's alpha measuring the inter-annotator agreement ranges from 0.6 for the six-level annotation schema to 0.75 for the three-level schema and 0.83 for the two-level schema. Our initial experiments on the dataset show that transformer models perform significantly better than those using a simpler architecture. Furthermore, regardless of the similarity of the three languages, we observe differences in performance across different languages. Performing parliament-specific training and evaluation shows that the main reason for the differing performance between parliaments seems to be the different complexity of the automatic classification task, which is not observable in annotator performance. Language distance does not seem to play any role neither in annotator nor in automatic classification performance. We release the dataset and the best-performing model under permissive licences.