 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLASSLA-Express: a Train of CLARIN.SI Workshops on Language Resources and Tools with Easily Expanding Route
Dec 02, 2024

This paper introduces the CLASSLA-Express workshop series as an innovative approach to disseminating linguistic resources and infrastructure provided by the CLASSLA Knowledge Centre for South Slavic languages and the Slovenian CLARIN.SI infrastructure. The workshop series employs two key strategies: (1) conducting workshops directly in countries with interested audiences, and (2) designing the series for easy expansion to new venues. The first iteration of the CLASSLA-Express workshop series encompasses 6 workshops in 5 countries. Its goal is to share knowledge on the use of corpus querying tools, as well as the recently-released CLASSLA-web corpora - the largest general corpora for South Slavic languages. In the paper, we present the design of the workshop series, its current scope and the effortless extensions of the workshop to new venues that are already in sight.
* Published in CLARIN Annual Conference Proceedings 2024 (https://www.clarin.eu/sites/default/files/CLARIN2024_ConferenceProceedings_final.pdf)
LLM Teacher-Student Framework for Text Classification With No Manually Annotated Data: A Case Study in IPTC News Topic Classification
Nov 29, 2024


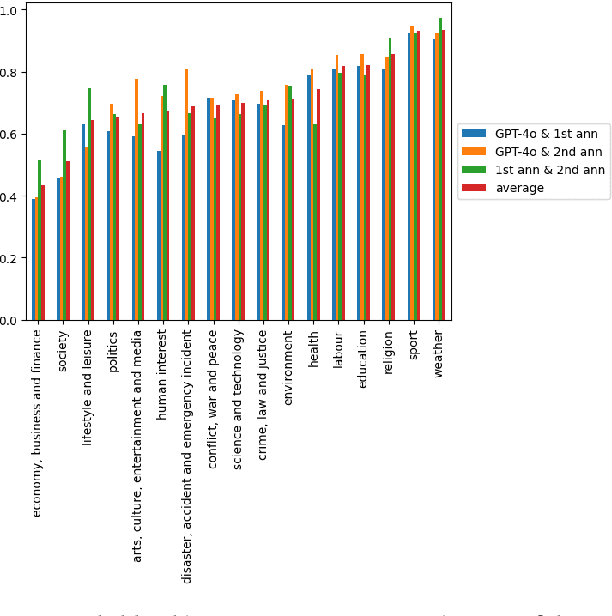
With the ever-increasing number of news stories available online, classifying them by topic, regardless of the language they are written in, has become crucial for enhancing readers' access to relevant content. To address this challenge, we propose a teacher-student framework based on large language models (LLMs) for developing multilingual news classification models of reasonable size with no need for manual data annotation. The framework employs a Generative Pretrained Transformer (GPT) model as the teacher model to develop an IPTC Media Topic training dataset through automatic annotation of news articles in Slovenian, Croatian, Greek, and Catalan. The teacher model exhibits a high zero-shot performance on all four languages. Its agreement with human annotators is comparable to that between the human annotators themselves. To mitigate the computational limitations associated with the requirement of processing millions of texts daily, smaller BERT-like student models are fine-tuned on the GPT-annotated dataset. These student models achieve high performance comparable to the teacher model. Furthermore, we explore the impact of the training data size on the performance of the student models and investigate their monolingual, multilingual and zero-shot cross-lingual capabilities. The findings indicate that student models can achieve high performance with a relatively small number of training instances, and demonstrate strong zero-shot cross-lingual abilities. Finally, we publish the best-performing news topic classifier, enabling multilingual classification with the top-level categories of the IPTC Media Topic schema.
Language Models on a Diet: Cost-Efficient Development of Encoders for Closely-Related Languages via Additional Pretraining
Apr 08, 2024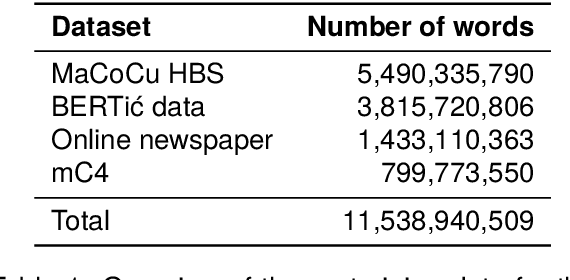
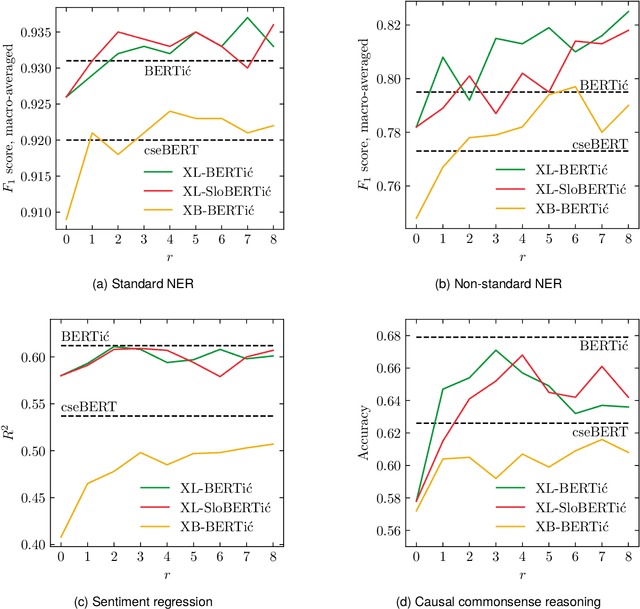
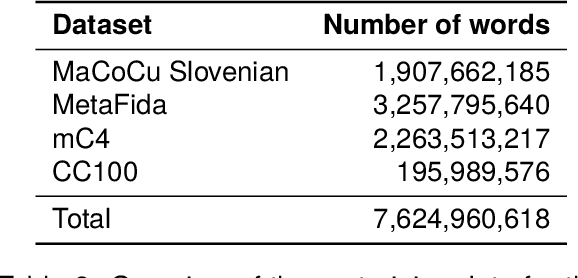

The world of language models is going through turbulent times, better and ever larger models are coming out at an unprecedented speed. However, we argue that, especially for the scientific community, encoder models of up to 1 billion parameters are still very much needed, their primary usage being in enriching large collections of data with metadata necessary for downstream research. We investigate the best way to ensure the existence of such encoder models on the set of very closely related languages - Croatian, Serbian, Bosnian and Montenegrin, by setting up a diverse benchmark for these languages, and comparing the trained-from-scratch models with the new models constructed via additional pretraining of existing multilingual models. We show that comparable performance to dedicated from-scratch models can be obtained by additionally pretraining available multilingual models even with a limited amount of computation. We also show that neighboring languages, in our case Slovenian, can be included in the additional pretraining with little to no loss in the performance of the final model.
CLASSLA-web: Comparable Web Corpora of South Slavic Languages Enriched with Linguistic and Genre Annotation
Mar 26, 2024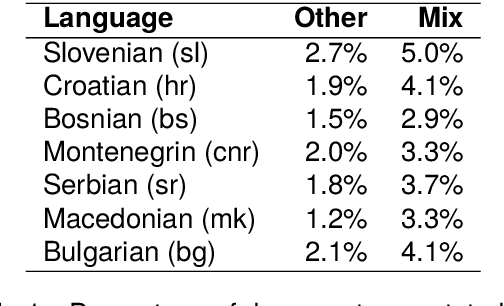
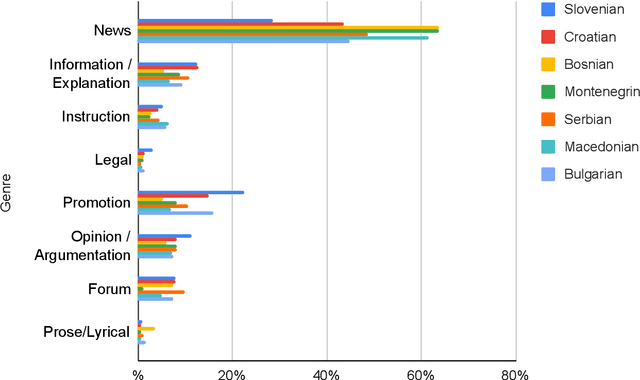
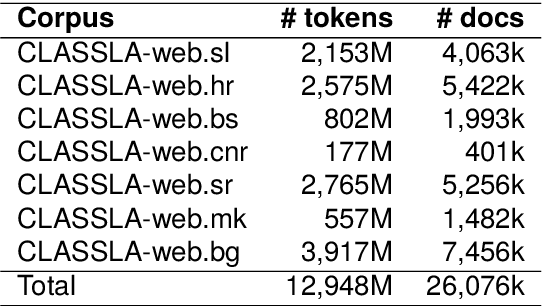
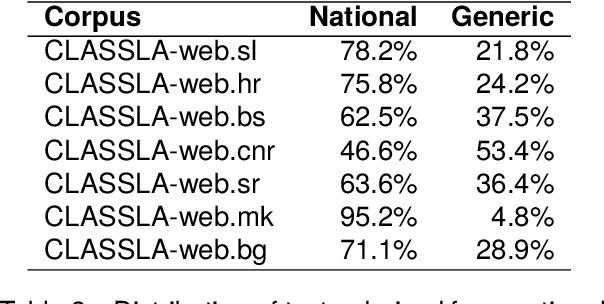
This paper presents a collection of highly comparable web corpora of Slovenian, Croatian, Bosnian, Montenegrin, Serbian, Macedonian, and Bulgarian, covering thereby the whole spectrum of official languages in the South Slavic language space. The collection of these corpora comprises a total of 13 billion tokens of texts from 26 million documents. The comparability of the corpora is ensured by a comparable crawling setup and the usage of identical crawling and post-processing technology. All the corpora were linguistically annotated with the state-of-the-art CLASSLA-Stanza linguistic processing pipeline, and enriched with document-level genre information via the Transformer-based multilingual X-GENRE classifier, which further enhances comparability at the level of linguistic annotation and metadata enrichment. The genre-focused analysis of the resulting corpora shows a rather consistent distribution of genres throughout the seven corpora, with variations in the most prominent genre categories being well-explained by the economic strength of each language community. A comparison of the distribution of genre categories across the corpora indicates that web corpora from less developed countries primarily consist of news articles. Conversely, web corpora from economically more developed countries exhibit a smaller proportion of news content, with a greater presence of promotional and opinionated texts.
Do Language Models Care About Text Quality? Evaluating Web-Crawled Corpora Across 11 Languages
Mar 13, 2024Large, curated, web-crawled corpora play a vital role in training language models (LMs). They form the lion's share of the training data in virtually all recent LMs, such as the well-known GPT, LLaMA and XLM-RoBERTa models. However, despite this importance, relatively little attention has been given to the quality of these corpora. In this paper, we compare four of the currently most relevant large, web-crawled corpora (CC100, MaCoCu, mC4 and OSCAR) across eleven lower-resourced European languages. Our approach is two-fold: first, we perform an intrinsic evaluation by performing a human evaluation of the quality of samples taken from different corpora; then, we assess the practical impact of the qualitative differences by training specific LMs on each of the corpora and evaluating their performance on downstream tasks. We find that there are clear differences in quality of the corpora, with MaCoCu and OSCAR obtaining the best results. However, during the extrinsic evaluation, we actually find that the CC100 corpus achieves the highest scores. We conclude that, in our experiments, the quality of the web-crawled corpora does not seem to play a significant role when training LMs.
ChatGPT: Beginning of an End of Manual Linguistic Data Annotation? Use Case of Automatic Genre Identification
Mar 08, 2023

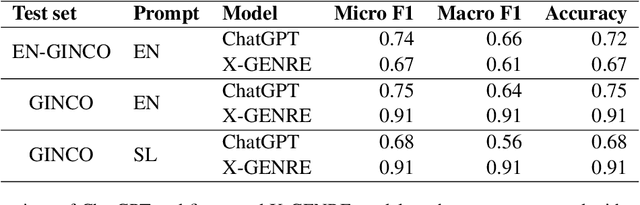
ChatGPT has shown strong capabilities in natural language generation tasks, which naturally leads researchers to explore where its abilities end. In this paper, we examine whether ChatGPT can be used for zero-shot text classification, more specifically, automatic genre identification. We compare ChatGPT with a multilingual XLM-RoBERTa language model that was fine-tuned on datasets, manually annotated with genres. The models are compared on test sets in two languages: English and Slovenian. Results show that ChatGPT outperforms the fine-tuned model when applied to the dataset which was not seen before by either of the models. Even when applied on Slovenian language as an under-resourced language, ChatGPT's performance is no worse than when applied to English. However, if the model is fully prompted in Slovenian, the performance drops significantly, showing the current limitations of ChatGPT usage on smaller languages. The presented results lead us to questioning whether this is the beginning of an end of laborious manual annotation campaigns even for smaller languages, such as Slovenian.
The GINCO Training Dataset for Web Genre Identification of Documents Out in the Wild
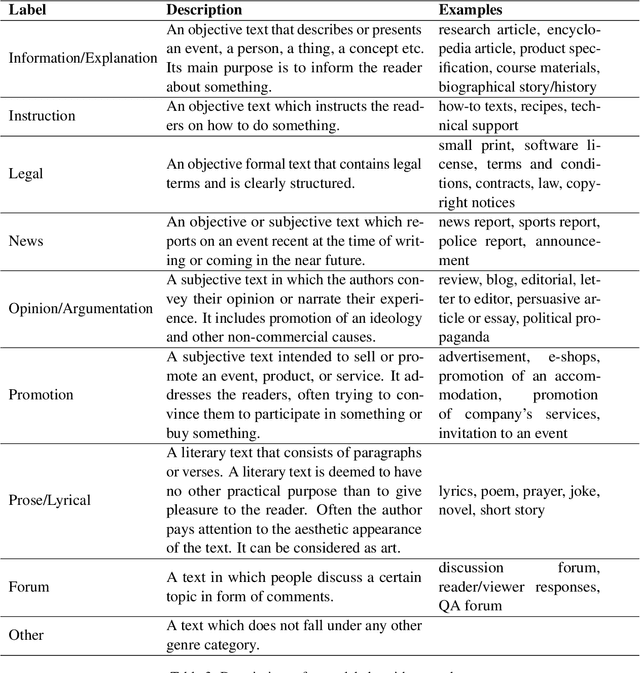
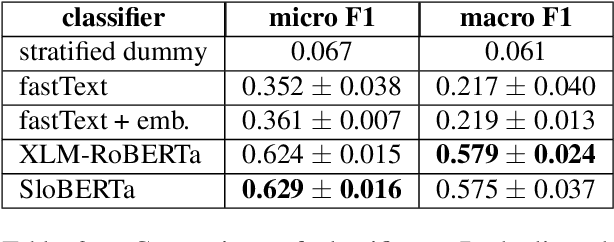
Jan 11, 2022


This paper presents a new training dataset for automatic genre identification GINCO, which is based on 1,125 crawled Slovenian web documents that consist of 650 thousand words. Each document was manually annotated for genre with a new annotation schema that builds upon existing schemata, having primarily clarity of labels and inter-annotator agreement in mind. The dataset consists of various challenges related to web-based data, such as machine translated content, encoding errors, multiple contents presented in one document etc., enabling evaluation of classifiers in realistic conditions. The initial machine learning experiments on the dataset show that (1) pre-Transformer models are drastically less able to model the phenomena, with macro F1 metrics ranging around 0.22, while Transformer-based models achieve scores of around 0.58, and (2) multilingual Transformer models work as well on the task as the monolingual models that were previously proven to be superior to multilingual models on standard NLP tasks.