 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Parallel Cross-Lingual Benchmark for Multimodal Idiomaticity Understanding
Jan 13, 2026Potentially idiomatic expressions (PIEs) construe meanings inherently tied to the everyday experience of a given language community. As such, they constitute an interesting challenge for assessing the linguistic (and to some extent cultural) capabilities of NLP systems. In this paper, we present XMPIE, a parallel multilingual and multimodal dataset of potentially idiomatic expressions. The dataset, containing 34 languages and over ten thousand items, allows comparative analyses of idiomatic patterns among language-specific realisations and preferences in order to gather insights about shared cultural aspects. This parallel dataset allows to evaluate model performance for a given PIE in different languages and whether idiomatic understanding in one language can be transferred to another. Moreover, the dataset supports the study of PIEs across textual and visual modalities, to measure to what extent PIE understanding in one modality transfers or implies in understanding in another modality (text vs. image). The data was created by language experts, with both textual and visual components crafted under multilingual guidelines, and each PIE is accompanied by five images representing a spectrum from idiomatic to literal meanings, including semantically related and random distractors. The result is a high-quality benchmark for evaluating multilingual and multimodal idiomatic language understanding.
CLASSLA-Express: a Train of CLARIN.SI Workshops on Language Resources and Tools with Easily Expanding Route
Dec 02, 2024

This paper introduces the CLASSLA-Express workshop series as an innovative approach to disseminating linguistic resources and infrastructure provided by the CLASSLA Knowledge Centre for South Slavic languages and the Slovenian CLARIN.SI infrastructure. The workshop series employs two key strategies: (1) conducting workshops directly in countries with interested audiences, and (2) designing the series for easy expansion to new venues. The first iteration of the CLASSLA-Express workshop series encompasses 6 workshops in 5 countries. Its goal is to share knowledge on the use of corpus querying tools, as well as the recently-released CLASSLA-web corpora - the largest general corpora for South Slavic languages. In the paper, we present the design of the workshop series, its current scope and the effortless extensions of the workshop to new venues that are already in sight.
* Published in CLARIN Annual Conference Proceedings 2024 (https://www.clarin.eu/sites/default/files/CLARIN2024_ConferenceProceedings_final.pdf)
bgGLUE: A Bulgarian General Language Understanding Evaluation Benchmark
Jun 07, 2023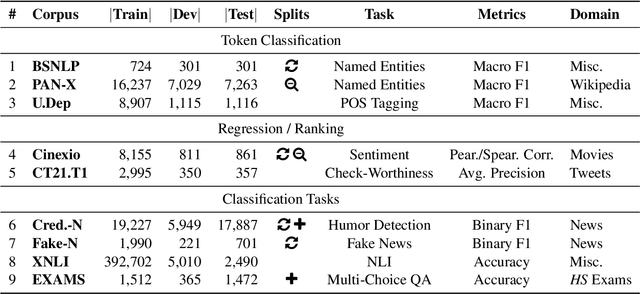
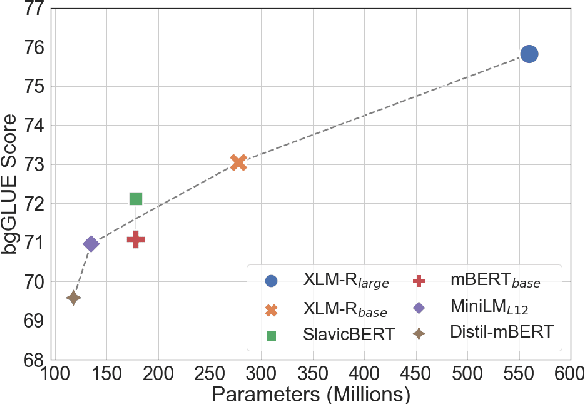

We present bgGLUE(Bulgarian General Language Understanding Evaluation), a benchmark for evaluating language models on Natural Language Understanding (NLU) tasks in Bulgarian. Our benchmark includes NLU tasks targeting a variety of NLP problems (e.g., natural language inference, fact-checking, named entity recognition, sentiment analysis, question answering, etc.) and machine learning tasks (sequence labeling, document-level classification, and regression). We run the first systematic evaluation of pre-trained language models for Bulgarian, comparing and contrasting results across the nine tasks in the benchmark. The evaluation results show strong performance on sequence labeling tasks, but there is a lot of room for improvement for tasks that require more complex reasoning. We make bgGLUE publicly available together with the fine-tuning and the evaluation code, as well as a public leaderboard at https://bgglue.github.io/, and we hope that it will enable further advancements in developing NLU models for Bulgarian.
* Accepted to ACL 2023 (Main Conference)
Multi-aspect Multilingual and Cross-lingual Parliamentary Speech Analysis
Jul 03, 2022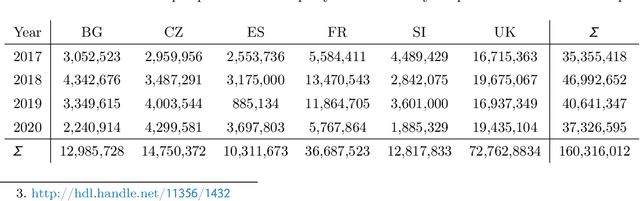
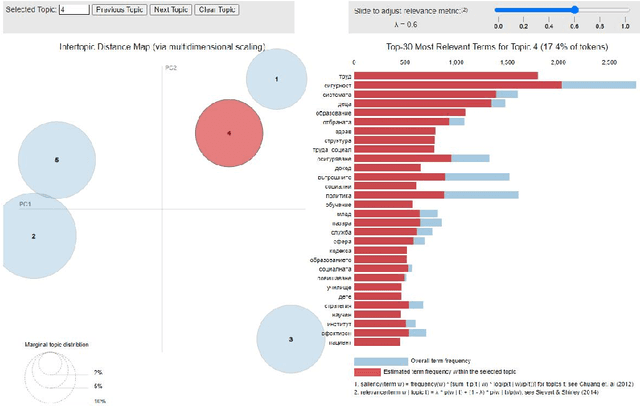
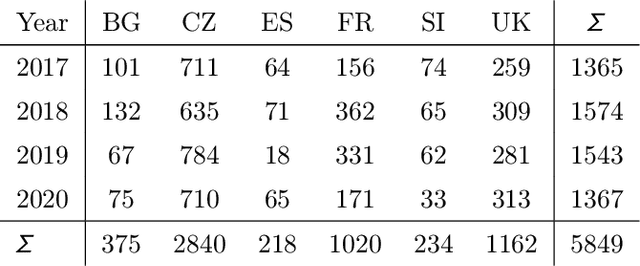
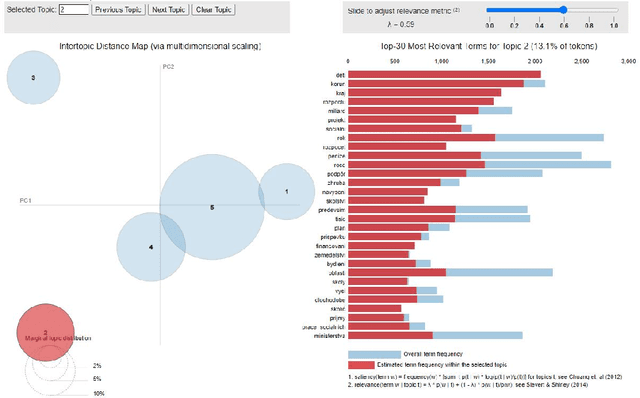
Parliamentary and legislative debate transcripts provide an exciting insight into elected politicians' opinions, positions, and policy preferences. They are interesting for political and social sciences as well as linguistics and natural language processing (NLP). Exiting research covers discussions within individual parliaments. In contrast, we apply advanced NLP methods to a joint and comparative analysis of six national parliaments (Bulgarian, Czech, French, Slovene, Spanish, and United Kingdom) between 2017 and 2020, whose transcripts are a part of the ParlaMint dataset collection. Using a uniform methodology, we analyze topics discussed, emotions, and sentiment. We assess if the age, gender, and political orientation of speakers can be detected from speeches. The results show some commonalities and many surprising differences among the analyzed countries.
Feature-Rich Named Entity Recognition for Bulgarian Using Conditional Random Fields
Sep 26, 2021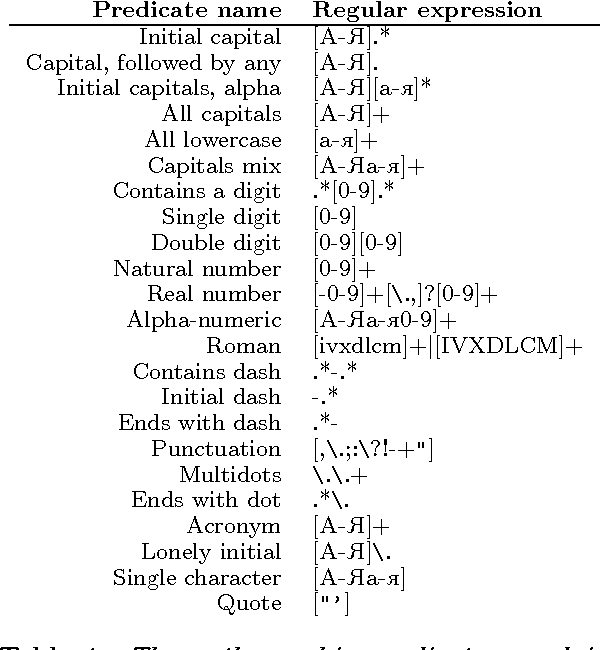

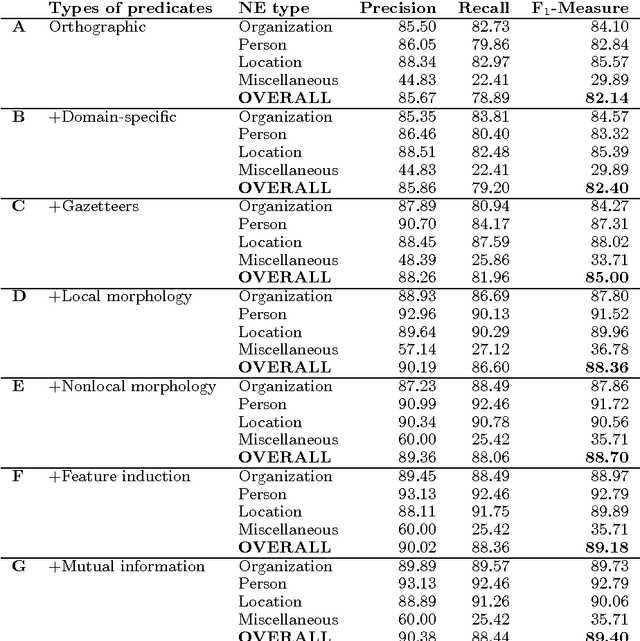
The paper presents a feature-rich approach to the automatic recognition and categorization of named entities (persons, organizations, locations, and miscellaneous) in news text for Bulgarian. We combine well-established features used for other languages with language-specific lexical, syntactic and morphological information. In particular, we make use of the rich tagset annotation of the BulTreeBank (680 morpho-syntactic tags), from which we derive suitable task-specific tagsets (local and nonlocal). We further add domain-specific gazetteers and additional unlabeled data, achieving F1=89.4%, which is comparable to the state-of-the-art results for English.
* named entity recognition, NER, conditional random fields, CRF, Bulgarian, BulTreeBank
Feature-Rich Part-of-speech Tagging for Morphologically Complex Languages: Application to Bulgarian
Nov 26, 2019
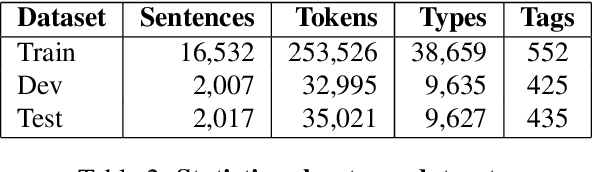

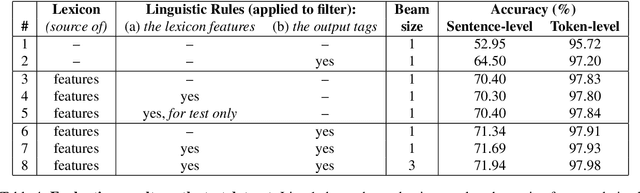
We present experiments with part-of-speech tagging for Bulgarian, a Slavic language with rich inflectional and derivational morphology. Unlike most previous work, which has used a small number of grammatical categories, we work with 680 morpho-syntactic tags. We combine a large morphological lexicon with prior linguistic knowledge and guided learning from a POS-annotated corpus, achieving accuracy of 97.98%, which is a significant improvement over the state-of-the-art for Bulgarian.
* part-of-speech tagging, POS tagging, morpho-syntactic tags, guided learning, Bulgarian, Slavic
A Morpho-Syntactically Informed LSTM-CRF Model for Named Entity Recognition
Aug 27, 2019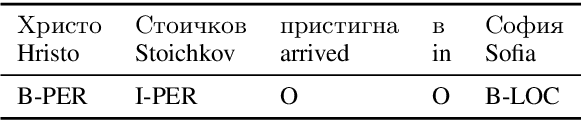
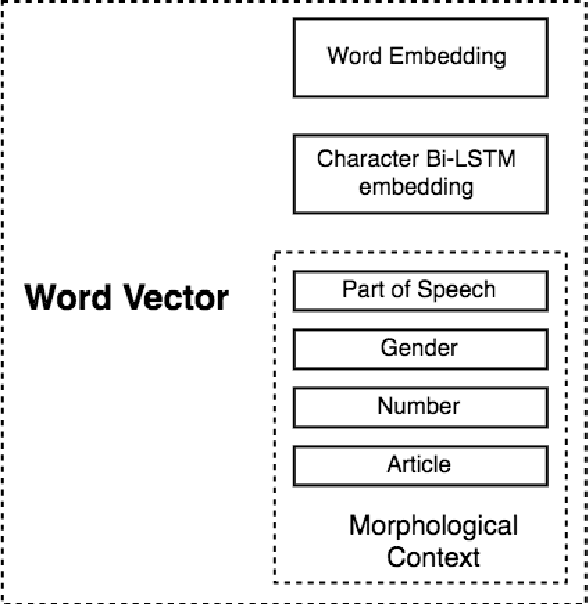


We propose a morphologically informed model for named entity recognition, which is based on LSTM-CRF architecture and combines word embeddings, Bi-LSTM character embeddings, part-of-speech (POS) tags, and morphological information. While previous work has focused on learning from raw word input, using word and character embeddings only, we show that for morphologically rich languages, such as Bulgarian, access to POS information contributes more to the performance gains than the detailed morphological information. Thus, we show that named entity recognition needs only coarse-grained POS tags, but at the same time it can benefit from simultaneously using some POS information of different granularity. Our evaluation results over a standard dataset show sizable improvements over the state-of-the-art for Bulgarian NER.
* named entity recognition; Bulgarian NER; morphology; morpho-syntax