 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Still Explain Themselves? Investigating the Impact of Quantization on Self-Explanations
Jan 01, 2026Quantization is widely used to accelerate inference and streamline the deployment of large language models (LLMs), yet its effects on self-explanations (SEs) remain unexplored. SEs, generated by LLMs to justify their own outputs, require reasoning about the model's own decision-making process, a capability that may exhibit particular sensitivity to quantization. As SEs are increasingly relied upon for transparency in high-stakes applications, understanding whether and to what extent quantization degrades SE quality and faithfulness is critical. To address this gap, we examine two types of SEs: natural language explanations (NLEs) and counterfactual examples, generated by LLMs quantized using three common techniques at distinct bit widths. Our findings indicate that quantization typically leads to moderate declines in both SE quality (up to 4.4\%) and faithfulness (up to 2.38\%). The user study further demonstrates that quantization diminishes both the coherence and trustworthiness of SEs (up to 8.5\%). Compared to smaller models, larger models show limited resilience to quantization in terms of SE quality but better maintain faithfulness. Moreover, no quantization technique consistently excels across task accuracy, SE quality, and faithfulness. Given that quantization's impact varies by context, we recommend validating SE quality for specific use cases, especially for NLEs, which show greater sensitivity. Nonetheless, the relatively minor deterioration in SE quality and faithfulness does not undermine quantization's effectiveness as a model compression technique.
Self-Critique and Refinement for Faithful Natural Language Explanations
May 28, 2025



With the rapid development of large language models (LLMs), natural language explanations (NLEs) have become increasingly important for understanding model predictions. However, these explanations often fail to faithfully represent the model's actual reasoning process. While existing work has demonstrated that LLMs can self-critique and refine their initial outputs for various tasks, this capability remains unexplored for improving explanation faithfulness. To address this gap, we introduce Self-critique and Refinement for Natural Language Explanations (SR-NLE), a framework that enables models to improve the faithfulness of their own explanations -- specifically, post-hoc NLEs -- through an iterative critique and refinement process without external supervision. Our framework leverages different feedback mechanisms to guide the refinement process, including natural language self-feedback and, notably, a novel feedback approach based on feature attribution that highlights important input words. Our experiments across three datasets and four state-of-the-art LLMs demonstrate that SR-NLE significantly reduces unfaithfulness rates, with our best method achieving an average unfaithfulness rate of 36.02%, compared to 54.81% for baseline -- an absolute reduction of 18.79%. These findings reveal that the investigated LLMs can indeed refine their explanations to better reflect their actual reasoning process, requiring only appropriate guidance through feedback without additional training or fine-tuning.
A Reality Check on Context Utilisation for Retrieval-Augmented Generation
Dec 22, 2024



Retrieval-augmented generation (RAG) helps address the limitations of the parametric knowledge embedded within a language model (LM). However, investigations of how LMs utilise retrieved information of varying complexity in real-world scenarios have been limited to synthetic contexts. We introduce DRUID (Dataset of Retrieved Unreliable, Insufficient and Difficult-to-understand contexts) with real-world queries and contexts manually annotated for stance. The dataset is based on the prototypical task of automated claim verification, for which automated retrieval of real-world evidence is crucial. We compare DRUID to synthetic datasets (CounterFact, ConflictQA) and find that artificial datasets often fail to represent the complex and diverse real-world context settings. We show that synthetic datasets exaggerate context characteristics rare in real retrieved data, which leads to inflated context utilisation results, as measured by our novel ACU score. Moreover, while previous work has mainly focused on singleton context characteristics to explain context utilisation, correlations between singleton context properties and ACU on DRUID are surprisingly small compared to other properties related to context source. Overall, our work underscores the need for real-world aligned context utilisation studies to represent and improve performance in real-world RAG settings.
Graph-Guided Textual Explanation Generation Framework
Dec 16, 2024



Natural language explanations (NLEs) are commonly used to provide plausible free-text explanations of a model's reasoning about its predictions. However, recent work has questioned the faithfulness of NLEs, as they may not accurately reflect the model's internal reasoning process regarding its predicted answer. In contrast, highlight explanations -- input fragments identified as critical for the model's predictions -- exhibit measurable faithfulness, which has been incrementally improved through existing research. Building on this foundation, we propose G-Tex, a Graph-Guided Textual Explanation Generation framework designed to enhance the faithfulness of NLEs by leveraging highlight explanations. Specifically, highlight explanations are extracted as highly faithful cues representing the model's reasoning and are subsequently encoded through a graph neural network layer, which explicitly guides the NLE generation process. This alignment ensures that the generated explanations closely reflect the model's underlying reasoning. Experiments on T5 and BART using three reasoning datasets show that G-Tex improves NLE faithfulness by up to 17.59% compared to baseline methods. Additionally, G-Tex generates NLEs with greater semantic and lexical similarity to human-written ones. Human evaluations show that G-Tex can decrease redundant content and enhance the overall quality of NLEs. As our work introduces a novel method for explicitly guiding NLE generation to improve faithfulness, we hope it will serve as a stepping stone for addressing additional criteria for NLE and generated text overall.
From Internal Conflict to Contextual Adaptation of Language Models
Jul 24, 2024



Knowledge-intensive language understanding tasks require Language Models (LMs) to integrate relevant context, mitigating their inherent weaknesses, such as incomplete or outdated knowledge. Nevertheless, studies indicate that LMs often ignore the provided context as it can conflict with the pre-existing LM's memory learned during pre-training. Moreover, conflicting knowledge can already be present in the LM's parameters, termed intra-memory conflict. Existing works have studied the two types of knowledge conflicts only in isolation. We conjecture that the (degree of) intra-memory conflicts can in turn affect LM's handling of context-memory conflicts. To study this, we introduce the DYNAMICQA dataset, which includes facts with a temporal dynamic nature where a fact can change with a varying time frequency and disputable dynamic facts, which can change depending on the viewpoint. DYNAMICQA is the first to include real-world knowledge conflicts and provide context to study the link between the different types of knowledge conflicts. With the proposed dataset, we assess the use of uncertainty for measuring the intra-memory conflict and introduce a novel Coherent Persuasion (CP) score to evaluate the context's ability to sway LM's semantic output. Our extensive experiments reveal that static facts, which are unlikely to change, are more easily updated with additional context, relative to temporal and disputable facts.
A Unified Framework for Input Feature Attribution Analysis
Jun 21, 2024



Explaining the decision-making process of machine learning models is crucial for ensuring their reliability and fairness. One popular explanation form highlights key input features, such as i) tokens (e.g., Shapley Values and Integrated Gradients), ii) interactions between tokens (e.g., Bivariate Shapley and Attention-based methods), or iii) interactions between spans of the input (e.g., Louvain Span Interactions). However, these explanation types have only been studied in isolation, making it difficult to judge their respective applicability. To bridge this gap, we propose a unified framework that facilitates a direct comparison between highlight and interactive explanations comprised of four diagnostic properties. Through extensive analysis across these three types of input feature explanations--each utilizing three different explanation techniques--across two datasets and two models, we reveal that each explanation type excels in terms of different diagnostic properties. In our experiments, highlight explanations are the most faithful to a model's prediction, and interactive explanations provide better utility for learning to simulate a model's predictions. These insights further highlight the need for future research to develop combined methods that enhance all diagnostic properties.
Revealing the Parametric Knowledge of Language Models: A Unified Framework for Attribution Methods
Apr 29, 2024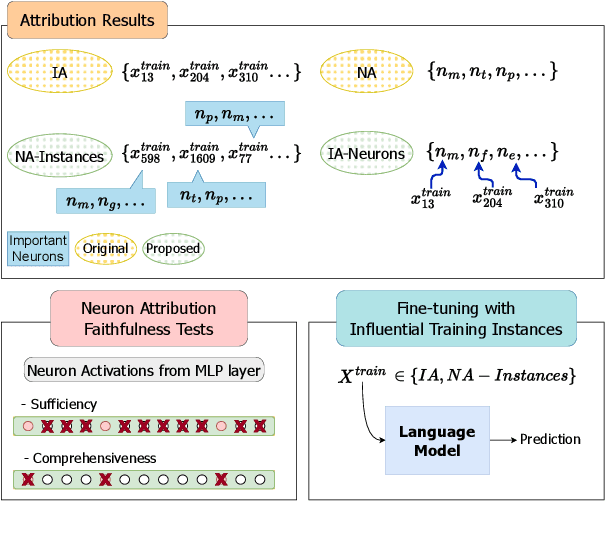
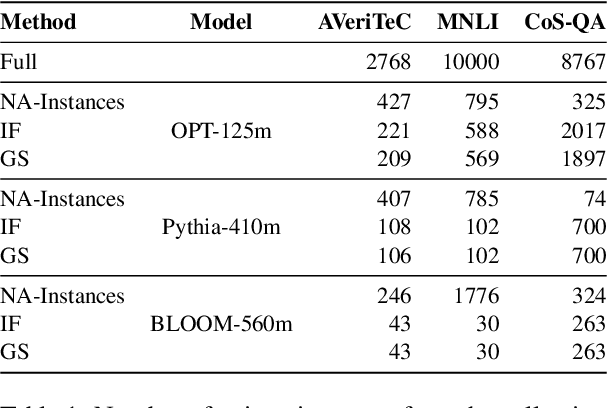
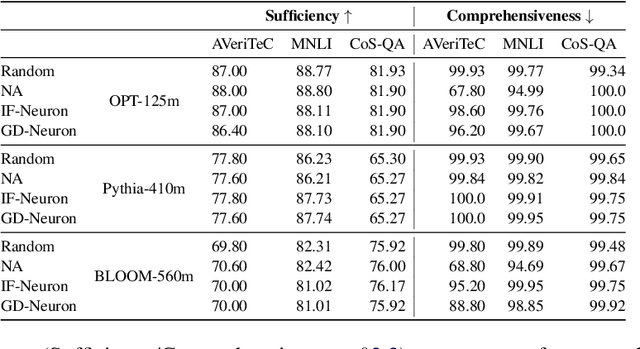
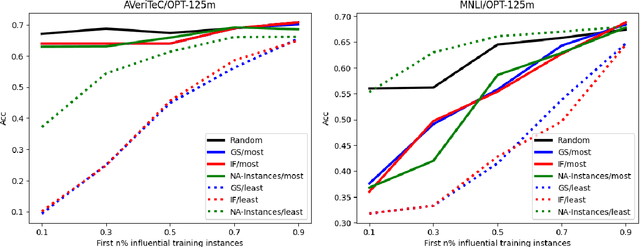
Language Models (LMs) acquire parametric knowledge from their training process, embedding it within their weights. The increasing scalability of LMs, however, poses significant challenges for understanding a model's inner workings and further for updating or correcting this embedded knowledge without the significant cost of retraining. This underscores the importance of unveiling exactly what knowledge is stored and its association with specific model components. Instance Attribution (IA) and Neuron Attribution (NA) offer insights into this training-acquired knowledge, though they have not been compared systematically. Our study introduces a novel evaluation framework to quantify and compare the knowledge revealed by IA and NA. To align the results of the methods we introduce the attribution method NA-Instances to apply NA for retrieving influential training instances, and IA-Neurons to discover important neurons of influential instances discovered by IA. We further propose a comprehensive list of faithfulness tests to evaluate the comprehensiveness and sufficiency of the explanations provided by both methods. Through extensive experiments and analysis, we demonstrate that NA generally reveals more diverse and comprehensive information regarding the LM's parametric knowledge compared to IA. Nevertheless, IA provides unique and valuable insights into the LM's parametric knowledge, which are not revealed by NA. Our findings further suggest the potential of a synergistic approach of combining the diverse findings of IA and NA for a more holistic understanding of an LM's parametric knowledge.
Explaining Interactions Between Text Spans
Oct 20, 2023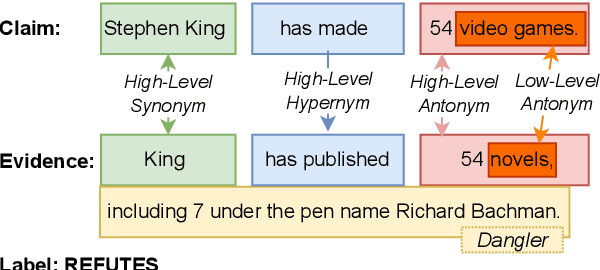
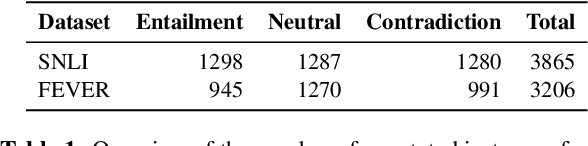
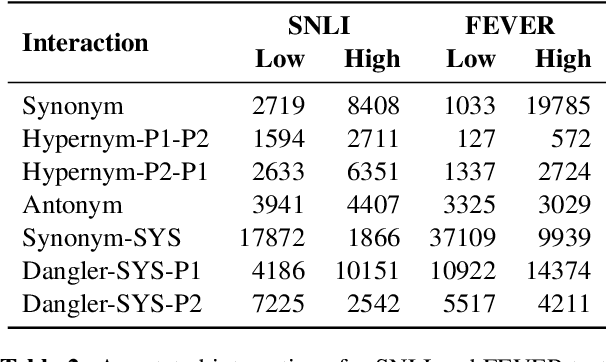
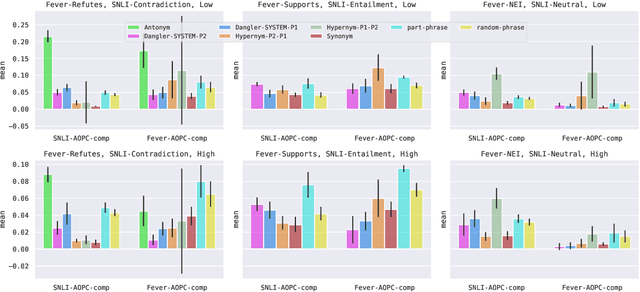
Reasoning over spans of tokens from different parts of the input is essential for natural language understanding (NLU) tasks such as fact-checking (FC), machine reading comprehension (MRC) or natural language inference (NLI). However, existing highlight-based explanations primarily focus on identifying individual important tokens or interactions only between adjacent tokens or tuples of tokens. Most notably, there is a lack of annotations capturing the human decision-making process w.r.t. the necessary interactions for informed decision-making in such tasks. To bridge this gap, we introduce SpanEx, a multi-annotator dataset of human span interaction explanations for two NLU tasks: NLI and FC. We then investigate the decision-making processes of multiple fine-tuned large language models in terms of the employed connections between spans in separate parts of the input and compare them to the human reasoning processes. Finally, we present a novel community detection based unsupervised method to extract such interaction explanations from a model's inner workings.
bgGLUE: A Bulgarian General Language Understanding Evaluation Benchmark
Jun 07, 2023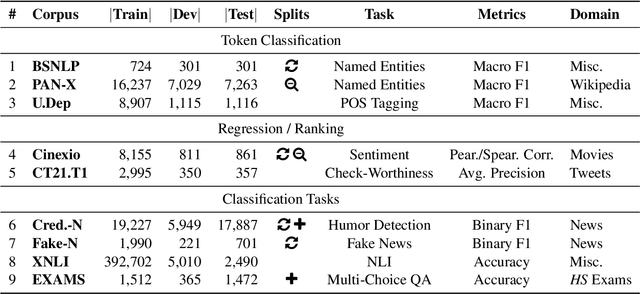

We present bgGLUE(Bulgarian General Language Understanding Evaluation), a benchmark for evaluating language models on Natural Language Understanding (NLU) tasks in Bulgarian. Our benchmark includes NLU tasks targeting a variety of NLP problems (e.g., natural language inference, fact-checking, named entity recognition, sentiment analysis, question answering, etc.) and machine learning tasks (sequence labeling, document-level classification, and regression). We run the first systematic evaluation of pre-trained language models for Bulgarian, comparing and contrasting results across the nine tasks in the benchmark. The evaluation results show strong performance on sequence labeling tasks, but there is a lot of room for improvement for tasks that require more complex reasoning. We make bgGLUE publicly available together with the fine-tuning and the evaluation code, as well as a public leaderboard at https://bgglue.github.io/, and we hope that it will enable further advancements in developing NLU models for Bulgarian.
* Accepted to ACL 2023 (Main Conference)
Faithfulness Tests for Natural Language Explanations
May 29, 2023Explanations of neural models aim to reveal a model's decision-making process for its predictions. However, recent work shows that current methods giving explanations such as saliency maps or counterfactuals can be misleading, as they are prone to present reasons that are unfaithful to the model's inner workings. This work explores the challenging question of evaluating the faithfulness of natural language explanations (NLEs). To this end, we present two tests. First, we propose a counterfactual input editor for inserting reasons that lead to counterfactual predictions but are not reflected by the NLEs. Second, we reconstruct inputs from the reasons stated in the generated NLEs and check how often they lead to the same predictions. Our tests can evaluate emerging NLE models, proving a fundamental tool in the development of faithful NLEs.