 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccountable and Explainable Methods for Complex Reasoning over Text
Paper and Code
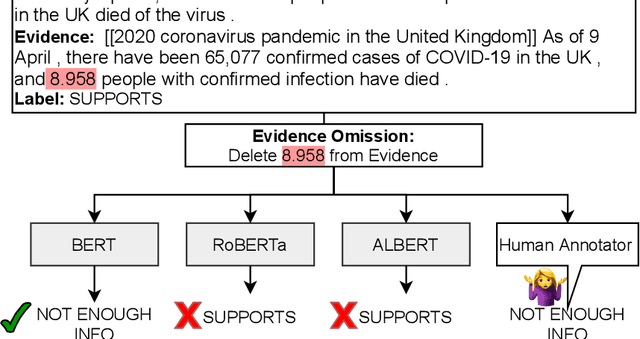

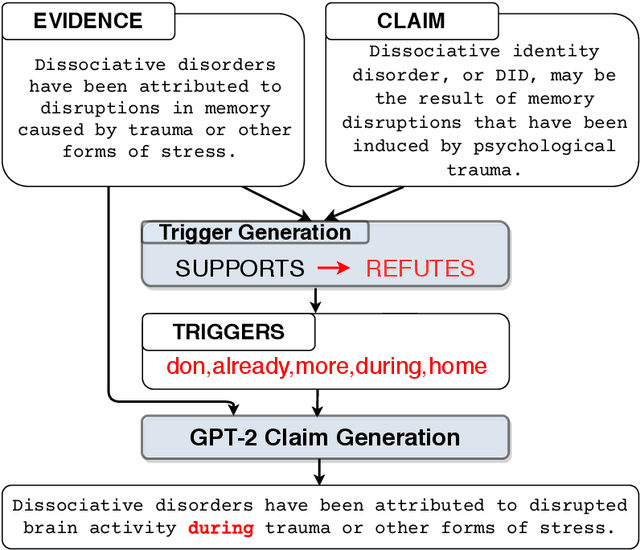
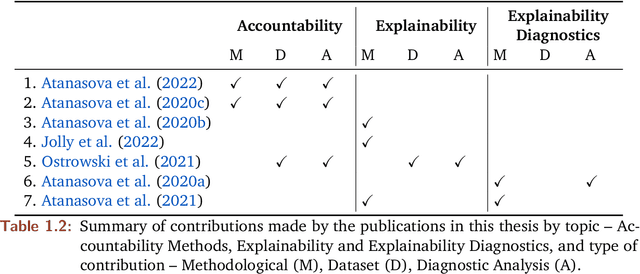
A major concern of Machine Learning (ML) models is their opacity. They are deployed in an increasing number of applications where they often operate as black boxes that do not provide explanations for their predictions. Among others, the potential harms associated with the lack of understanding of the models' rationales include privacy violations, adversarial manipulations, and unfair discrimination. As a result, the accountability and transparency of ML models have been posed as critical desiderata by works in policy and law, philosophy, and computer science. In computer science, the decision-making process of ML models has been studied by developing accountability and transparency methods. Accountability methods, such as adversarial attacks and diagnostic datasets, expose vulnerabilities of ML models that could lead to malicious manipulations or systematic faults in their predictions. Transparency methods explain the rationales behind models' predictions gaining the trust of relevant stakeholders and potentially uncovering mistakes and unfairness in models' decisions. To this end, transparency methods have to meet accountability requirements as well, e.g., being robust and faithful to the underlying rationales of a model. This thesis presents my research that expands our collective knowledge in the areas of accountability and transparency of ML models developed for complex reasoning tasks over text.